Nginx防爬虫优化
Robots协议(也称为爬虫协议,机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
我理解的是robots.txt是通过代码控制搜索引擎蜘蛛索引的一个手段,以便减轻网站服务器的带宽使用率,从而让网站的空间更稳定,同时也可以提高网站其他页面的索引效率,提高网站收录。
我们只需要创建一个robots.txt文本文件,然后在文档内设置好代码,告诉搜索引擎我网站的哪些文件你不能访问。然后上传到网站根目录下面,因为当搜索引擎蜘蛛在索引一个网站时,会先爬行查看网站根目录下是否有robots.txt文件。
京东的robots.txt设置如下:
https://www.jd.com/robots.txt
淘宝的robots.txt设置如下:
https://www.taobao.com/robots.txt
360的robots.txt设置如下:
http://www.360.cn/robots.txt
我们可以根据客户端的user-agents信息,轻松地阻止指定的爬虫爬取我们的网站。
阻止下载协议代理,命令如下:
##Block download agents##
if ($http_user_agent ~* LWP:Simple | BBBike | wget)
{
return 403;
}
#说明:如果用户匹配了if后面的客户端(例如wget),就返回403.
这里根据$http_user_agent获取客户端agent,然后判断是否允许或返回指定错误码。
添加内容防止N多爬虫代理访问网站,命令如下:
#这些爬虫代理使用“|”分隔,具体要处理的爬虫可以根据需求增加或减少,添加的内容如下:
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot-Modile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Yahoo! SSlurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot")
{
return 403;
}
测试禁止不同的浏览器软件访问
if ($http_user_agent ~* "Firefox|MSIE")
{
rewrite ^(.*) http://www.wk.com/$1 permanent;
}
#如果浏览器为Firefox或IE,就会跳转到http://www.wk.com
利用Nginx限制HTTP的请求方法
最常用的HTTP方法为GET,POST,我们可以通过Nginx限制HTTP请求的方法来达到提升服务器安全的目的,例如,让HTTP只能使用GET,HEAD和POST方法的配置如下:
#Only allow these request methods
if ($request_method ! ~ ^(GET|HEAD|POST)$)
{
return 501;
}
当上传服务器上传数据到存储服务器时,用户上传写入的目录就不得不给Nginx对应的用户相关权限,这样一旦程序有漏洞,木马就有可能被上传到服务器挂载的对应存储服务器的目录里,虽然我们也做了禁止PHP,SH,PL,PY等扩展名的解析限制,但还是会遗漏一些想不到的可执行文件。对于这样情况可以通过限制上传服务器的Web服务(可以具体到文件)使用GET方法,防止用户通过上传服务器访问存储内容,让访问存储渠道只能从静态或图片服务器入口进入。例如,在上传服务器上限制HTTP的GET方法的配置如下:
#Only deny GET request methods ##
if ($request_method ~* ^(GET)$)
{
return 501;
}
#提示:还可以加一层location,更具体地限制文件名
使用CDN做网站内容加速
什么是CDN
- CDN的全称是Content Delivery Network,中文意思是内容分发网络。简单地讲,通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的Cache服务器内,通过智能DNS负载均衡技术,判断用户的来源,让用户就近使用与服务器相同线路的带宽访问Cache服务器,取得所需的内容。例如:天津网通用户访问天津网通Cache服务器上的内容,北京电信访问北京电信Cache服务器上的内容。这样可以有效减少数据在网络上传输的时间,提高访问速度。
- CDN是一套全国或全球的1分布式缓存集群,其实质是通过智能DNS判断用户的来源地域及上网线路,为用户选择一个最接近用户地域,以及和用户上网线路相同的服务器节点,因为地域近,且线路相同,所以,可以大幅提升用户浏览网站的体验。
- CDN产生背景之一:BGP机房虽然可以提升用户体验,但是价格昂贵,对于用户来说,CDN的诞生可以提供比BGP机房更好的体验(让同一地区,同一线路的用户访问和当地同一线路的网站),BGP机房和普通机房有将近5~10倍的价格差。CDN多使用单线的机房,根据用户的线路及位置,为用户选择靠近用户的位置,以及相同的运营商线路,不但提升了用户体验,价格也降下来了。
CDN的价值:
- 为架设网站的企业省钱
- 提升企业网站的用户访问体验(相同线路,相同地域,内存访问)
- 可以阻挡大部分流量攻击,例如:DDOS攻击
CDN的特点
CDN就是一个具备根据用户区域和线路智能调度的分布式内存缓存集群。其特点如下:
- 通过服务器内存缓存网站数据,提高了企业站点(尤其含有大量图片,视频等的站点)的访问速度,并大大提高企业站点的稳定性(省钱且提升用户体验)。
- 用户根据智能DNS技术自动选择最适合的Cache服务器,降低了不同运营商之间互联瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量。
- 加快了访问速度,减少了原站点的带宽
- 用户访问时从服务器的内存中读取数据,分担了网络流量,同时减轻了原站点负载压力等。
- 使用CDN可以分担源站的网络流量,同时可以减轻原站点的负载压力,并降低黑客入侵及各种DDOS攻击对网站的影响,保证网站有较好的服务质量。
企业使用CDN的基本要求
首先要说的是,不是所有的网站都可以一上来就能用CDN的。要加速的业务数据应该存在独立的域名,例如:img1-4.yunjisuan.com/video1-4.yunjisuan.com,业务内容图片,附件,JS,CSS等静态元素,这样的静态网站域名才可以使用CDN。
DNS解析范例。DNS服务器加速前的A记录如下:
;A records
img.yunjisuanl.com IN A 124.106.0.21 (企业服务器的IP)
#删除上面的记录,命令如下:
img.yunjisuanl.com IN A 124.106.0.21 (服务器的IP)
#然后,做下面的别名解析:
;CNAME records
img.yunjisuan.com IN CNAME bbs
img.yunjisuan.com 3M IN CNAME img.yunjisuan.com.cachecn.com.
提示:
这个img.yunjisuan.com.cachecn.com.地址必须是事先由CDN公司配置好的CDN公司的域名。国内较大的CDN提供商为网宿,蓝讯,快网。
Nginx程序架构优化
解耦是开发人员中流行的一个名词,简单地说就是把一堆程序代码按照业务用途分开,然后提供服务,例如:注册登录,上传,下载,浏览列表,商品内容页面,订单支付等都应该是独立的程序服务,只不过在客户端看来是一个整体而已。如果中小公司做不到上述细致的解耦,起码也要让下面的几个程序模块独立。
- 网页页面服务。(静态,动态页面)
- 图片附件及下载服务。(upload)
- 上传图片服务。(static)
上述三者的功能尽量分离。分离的最佳方式是分别使用独立的服务器(需要改动程序),如果程序实在不易更改,次选方案是在前端负载均衡器Haproxy/Nginx上,根据URI(例如目录或扩展名)过滤请求,然后抛给后面对应的服务器。
例如:根据扩展名分发,请求http://www.wk.com/a/b.jpg就应抛给图片服务器(独立的静态服务器最适合使用CDN);根据URL路径分发,请求http://www.wk.com/upload/index.php就应抛给上传服务器。不符合上面两个要求的,默认抛给Web服务器。
说明:可以部署3台服务器,人为分布请求服务器。当然了,这适合并发比较高,服务器较多的情况。程序架构分离了,效率,安全性都会提高很多。
使用普通用户启动Nginx(监牢模式)多实例nginx
为什么要让Nginx服务使用普通用户
默认情况下,Nginx的Master进程使用的是root用户,worker进程使用的是Nginx指定的普通用过户,使用root用户跑Nginx的Master进程有两个最大的问题:
- 管理权限必须是root,这就使得最小化分配权限原则遇到难题。
- 使用root跑Nginx服务,一旦网站出现漏洞,用户就可以很容易地获得服务器的root权限。
给Nginx服务降权的解决方案
- 给Nginx服务降权,用inca用户跑Nginx服务,给开发及运维设置普通账号,只要与inca同组即可管理Nginx,该方案解决了Nginx管理问题,防止root分配权限过大。
- 开发人员使用普通账户即可管理Nginx服务及站点下的程序和日志。
- 采取项目负责制度,即谁负责项目维护,出了问题就是谁负责。
给Nginx服务降权实战
配置普通用户启动Nginx的过程如下:
useradd wk
su - wk
mkdir conf logs www #在普通用户家目录下创建nginx配置文件目录
cp /usr/local/nginx/conf/mime.types ~/conf/
echo "hehe" > www/index.html
在普通用户的家目录里的conf目录里建主配置 文件 主配文件的路径全部找/home/wk
特权用户root使用的80端口,改为普通用过户使用的端口,在1024以上,这cat conf/nginx.conf
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
worker_rlimit_nofile 65535;
error_log /home/wk/logs/error.log;
user wk wk;
pid /home/wk/logs/nginx.pid;
events {
use epoll;
worker_connections 10240;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
log_format main '$remote_addr-$remote_user[$time_local]"$request"'
'$status $body_bytes_sent "$http_referer"'
'"$http_user_agent""$http_x_forwarded_for"';
server {
listen 8080;
server_name www.wk.com;
root /home/wk/www;
location / {
index index.php index.html index.htm;
}
access_log /home/wk/logs/web_blog_access.log main;
}
}
tree
├── conf
│ ├── mime.types
│ └── nginx.conf
├── logs
└── www
└── index.html
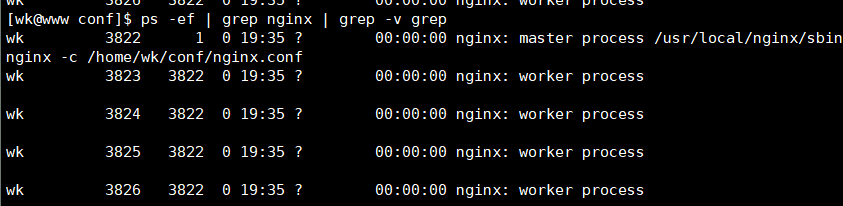
启动Nginx,命令如下:
/usr/local/nginx/sbin/nginx -c /home/wk/conf/nginx.conf &>/dev/null
ps -ef | grep nginx | grep -v grep

控制Nginx并发连接数量
ngx_http_limit_conn_module这个模块用于限制每个定义的key值的连接数(Nginx默认已经被编译),特别是单IP的连接数。
不是所有的连接数都会被计数。一个符合计数要求的连接是整个请求头已经被读取的连接。
控制Nginx并发连接数量参数的说明如下:
limit_conn_zone参数:
语法:limit_conn_zone key zone=name:size;
上下文:http
#用于设置共享内存区域,key可以是字符串,Nginx自带变量或前两个组合,如$binary_remote_addr,$server_name.name为内存区域的名称,size为内存区域的大小。
limit_conn参数:
语法:limit_conn zone number;
上下文:http,server,location
#用于指定key设置最大连接数。当超过最大连接数时,服务器会返回503(Service Temporarily Unavailable)错误
限制单IP并发连接数
Nginx的配置文件如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
limit_conn_zone $binary_remote_addr zone=addr:10m; #limit_conn_zone参数
server {
listen 80;
server_name www.yunjisuan.com;
location / {
root html;
index index.html index.htm;
limit_conn addr 1; #限制同IP的并发为1;
}
}
以上功能的应用场景之一是用于服务器下载,命令如下:
location /download/ {
limit_conn addr 11;
}上面的命令限制访问download下载目录的连接数,该连接数1.
限制虚拟主机总连接数
不仅可以限制单IP的并发连接数,还可以限制虚拟主机总连接数,甚至可以对两者同时限制。
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
limit_conn_zone $binary_remote_addr zone=addr:10m; #设置参数下边才会生效
limit_conn_zone $server_name zone=perserver:10m; #设置参数下边才会生效
server {
listen 80;
server_name www.yunjisuan.com;
location / {
root html;
index index.html index.htm;
#limit_conn addr 1;
limit_conn perserver 2; #设置虚拟主机连接数为2
}
}
控制客户端请求Nginx的速率
ngx_http_limit_req_module模块用于限制每个IP访问每个定义key的请求速率。
语法:limit\_req\_zone key zone=name: size rate=rate;
上下文1:http
#用于设置共享内存区域,key可以是1字符串,Nginx自带变量或前两个组合,如$binary_remote_addr。name为内存区域的名称,size为内存区域的大小,rate为速率,单位为r/s,每秒一个请求。
limit_req参数说明如下:
语法:limit_req zone=name [burst=number][nodelay];
上下文:http,server,location
- 这里运用了令牌桶原理,burst=num,一共有num块令牌,令牌发完后,多出来的那些请求就会返回503。
- 换句话说,一个银行,只有一个营业员,银行很小,等候室只有5个人的位置。因此,营业员一个时刻只能为一个人提供服务,剩下的不超过5个人可以在银行内等待,超出的人不提供服务,直接返回503。
- nodelay默认在不超过burst值的前提下会排队等待处理,如果使用此参数,就会处理完num + 1次请求,剩余的请求都视为超时,返回503。
Nginx配置文件如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; #以请求的客户端IP作为key值,内存区域命令为one,分配10m内存空间,访问速率限制为1秒1次请求(request)
# limit_conn_zone $binary_remote_addr zone=addr:10m;
# limit_conn_zone $server_name zone=perserver:10m;
server {
listen 80;
server_name www.yunjisuan.com;
location / {
root html;
index index.html index.htm;
limit_req zone=one burst=5; #使用前面定义的名为one的内存空间,队列值为5,即可以有5个请求排队等待
# limit_conn addr 1;
# limit_conn addr 1;
}
}