
背景
单位每年都会举行运动会,有一个2000m长跑的项目,大约每年报名人员为男选手40人,女选手20人,只有一条橡胶跑道。一次比赛10人齐跑,所以至少需要6场比赛。
2000米的完成时间要求是20分钟,超过20分钟不计数,所以比赛耗时我们计算为20分钟,加上比赛前的动员组织,比赛后的清场,我们假定每场比赛耗时30分钟。
现在我们预估下耗时:
1、60人/10人每场 = 6场,至少需要举行6场
2、总耗时 = 6场 * 0.5h = 3h
所以每年把这个比赛安排在下午3点到6点,是最后一个比赛项目,晚上7点举行颁奖晚会。这个预估容量也算合理。
但是今年比较特别,取消了4000米的长跑,所以2000米报名人员激增50人。时间还是下午3点到6点,
这个就有问题了,最后为了保证晚会的正常进行,一半的人员的比赛时间推迟到另外一周的周末,搞得怨声四起,大骂举办的行政部门不讲武德。
这个是我们单位真实的故事,这就是设计容量,当你的业务场景的容量发生了变化时候,没有预估到他的变化,以及变化可能产生的影响,没有按照这个影响及时的做调整
(比如将比赛时间提前,拉长整个比赛的过程时间,或者增加比赛跑到,同时进行两场比赛),就会造成灾难。
概念
何为设计容量,从技术上说就是运用一些策略对系统容量进行预估的过程。容量设计是架构师必备的技能之一。
他要求我们分析系统设计容量要求,尽可能给出具体数据描述的:数据量、并发量、带宽、注册用户规模、活跃用户规模、在线用户规模、消息长度,图片大小、网盘空间容量,内存CPU容量等。
下面的内容,我们以 并发 为例子,看看看具体的分析过程。
分析过程
理解一些原理
TPS(Transactions Per Second):每秒事务数
QPS(Query Per Second):每秒请求数,QPS其实是衡量吞吐量的一个常用指标,就是说服务器在一秒的时间内处理了多少个请求。
并发数:并发数是指系统同时能处理的请求数量,这个也是反应了系统的负载能力。
峰值QPS计算:
1、原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
2、公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
PV(Page View):页面访问量,即页面浏览量或点击量,用户每次刷新即被计算一次
UV(Unique Visitor):独立访客,统计1天内访问某站点的用户数(以cookie为依据)
吐吞量:吞吐量是指系统在单位时间内处理请求的数量
响应时间(RT):响应时间是指系统对请求作出响应的时间,一般取平均响应时间
QPS(每秒查询数)、TPS(每秒事务数)是吞吐量的常用量化指标,另外还有HPS(每秒HTTP请求数)。
QPS(TPS)、并发数、响应时间它们三者之间的关系是:
1、QPS(TPS)= 并发数 / 平均响应时间
2、并发数 = QPS * 平均响应时间
系统容量评估时机
主要在三种业务场景下需要及时考虑对系统容量进行评估。
1、临时的流量变化:比如 618、双11,新年大促搞活动等场景,预估我们的流量会大涨,甚至到原来的数倍。这时候要做好应对的措施。
2、初始系统容量评估:假设我们开发了某个系统,这个系统初始上线,我们预估他的容量和负载会是多少。
3、容量基数的变化:比如某个系统,他的功能模块越来越多,数据流量越来越大,日活指数越来越高,迎来了第二波的增长曲线。我们原来定好的系统容量渐渐的不满足我们的需求,这时候我们也要重新评估和扩容。
我们系统容量评估包括数据量、并发量、带宽、CPU、MEMORY、DISK等。以并发量为案例,我们来说明系统容量评估的方法和步骤。
评估的步骤
1、分析日总访问量
分析可能的日访问量,一般系统系统都会提供比较真实的访问量数值,基于此,我们需要评估一个活动的访问量;如果是一个新上线的系统,我们也要评估可能的PV、UV值。
产品、运营部门也需要给出可能的访问预期值。
举个例子:
我们活动期间(9点~10点)会推送2000W的应用消息,假设用户实际点进去查看的比列为1/10,那么这个活动期间(1小时)新增的访问量就有 2000W * 1/10= 200W
2、评估平均访问量QPS
QPS是每秒请求量,假设我们一天正常活动时间一般是11个小时多一点,那一天的时间长度以秒为单位:60*60*11 ≈ 4W, 我们再使用日访问时间再去除以4W总时间即可.
举个例子:
我们上面说的两个小时的活动时间,实际的总访问量最后确实是200W,
那么平均访问量QPS为:200W/(60*60)=555.5 QPS.
一个成熟系统日QPS也可以预估 ,比如 百度首页的日PV数量为 5000W,按照我们说的常规活动时间4W秒算,就是5000W / 4W = 1250 QPS.
3、评估高峰区间的QPS
我们在做系统容量规划时,不仅仅是考虑平均QPS,最重要的是要承受住高峰区间的QPS,这个数据可以根据业务流量监控的曲线和28法则来评估,我们来看下具体是怎么做的?
3.1 业务流量监控的曲线
以下面这个云系统作为例子:
日均QPS为2900,业务访问趋势图如下图,我们来对峰值QPS做一下预估




从图中可以看出,峰值QPS大概是均值QPS的2.58倍,日均QPS为2900,于是评估出峰值QPS为2900*2.58=7482。
这种是日常流量情况,如果遇到很特别的业务,比如竞拍\抢订\秒杀情况,流量幅度还是比较大的.
3.2 使用二八法则计算
何为二八法则:80%的业务基本都是发生在20%的时间里面,所以有如下:
峰值QPS公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
4、评估单实例极限承受的QPS
可以使用压测(nGrinder 或者 jmeter)方式来获取单个系统实例的QPS极限值,我们团队的标准是当请求响应时间超过2S的时候,已经达到了瓶颈值,并影响使用,需要进行优化和扩容。
我们在一个系统上线前,一般来说是需要进行压力测试,了解她实际的极限值在哪个地方,以我们上面流量图为例子(日平均QPS为2900,峰值QPS为7500),这个系统的架构可能是这样的:
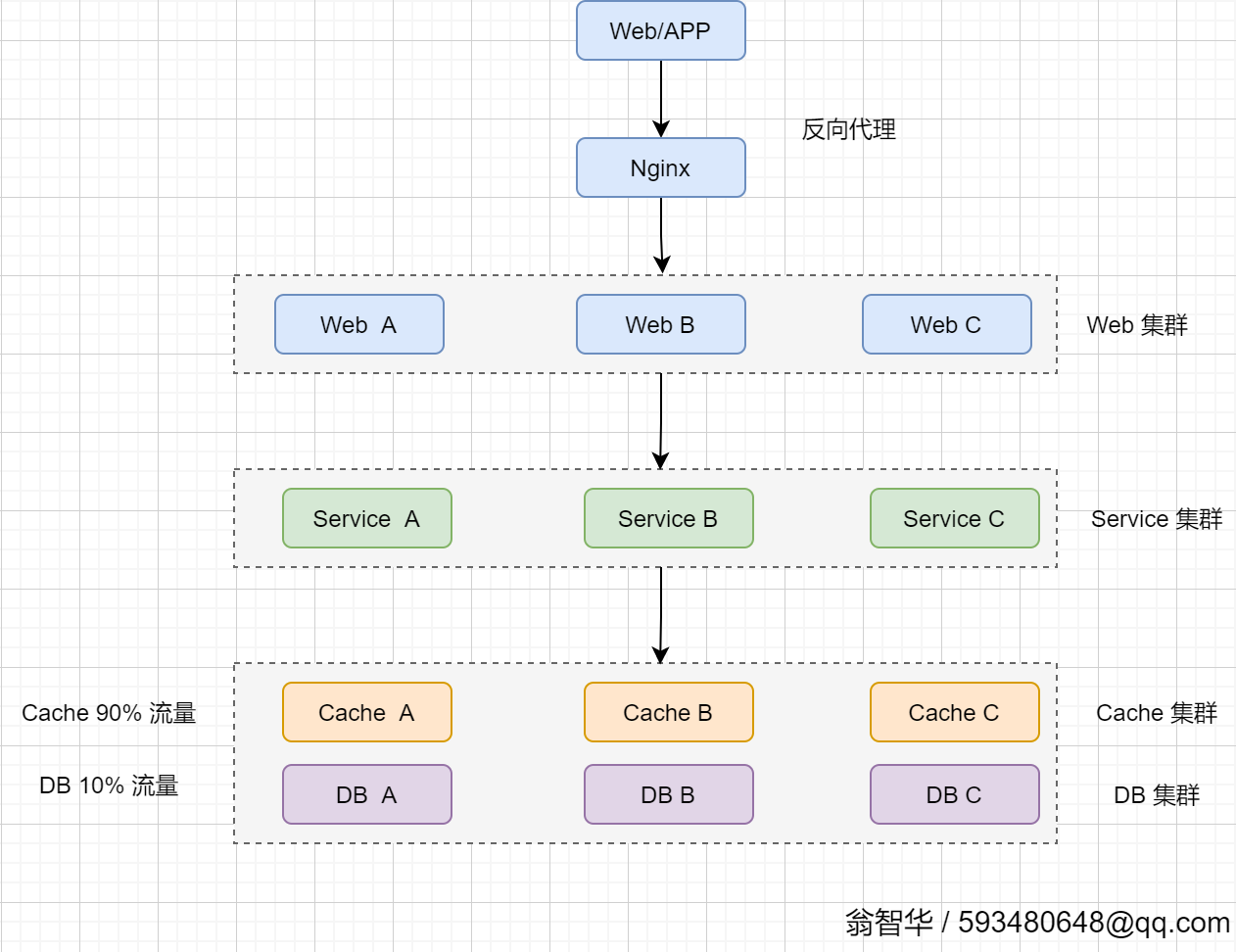
1、经由APP和Web的的请求,会经过Nginx均衡到多台Web站点上去。
2、Web集群会调用并落地到Service集群上
3、Service集群向数据层请求数据,正常情况下其中90%会落到Cache集群中
4、Cache集群中不存在(假设10%),会进入DB集群去访问数据库。
我们通过压测数据发现,web层是瓶颈,tomcat压测单个实例只能支持2500的QPS。
Cache集群和DB集群足够强悍,能够轻松应对峰值7500的QPS,按比例分别是7500*0.9=6750 和 7500*0.1=750.
所以我们得到了web单实例极限的QPS是2500。这边需要下调,因为我们不建议让请求响应时长接近2S,最好是1S以内。所以下调至2000。
5、根据线上冗余度最终确认
通过上面的计算,我们已经得到了峰值QPS是7500,单个实例能够顺畅承载QPS是2000,那么Web集群中至少有4个实例能够承接这样的请求洪峰。
除此之外,其他类型的的容量预估,如数据量、带宽、CPU、MEMORY、DISK等都可以采用类似策略。
案例分析
结合项目:如何计算图书系统的QPS、峰值QPS、N个实例和并发数
1、图书预定系统的并发数计算:
1.1、二八法则定理:80%的业务基本都是发生在20% 的时间里面,如系统有早中晚高峰,历经9个小时(早上10点到晚上19点),9*3600=32400。
1.2、获取峰值QPS:公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
即 ( 1500000 * 80% ) / ( 32400 * 20% ) = 600000/6480≈185/秒
1.3、并发数 = QPS * 平均响应时间 = 0.5*185 = 92.5 ,矫正为100
1.4、利用343估算法判定 154,向上矫正为200
Pessimism 悲观 | 30% | 80 |
Normal 标准 | 40% | 100 |
Optimism 乐观 | 30% | 300 |
最后提供给性能测试QA 的测试标准数据是 建议支持并发 200+,QA最终的测试结果是 该并发下响应时间在 50~100ms
总结
系统设计容量评估时机:
1、临时的流量变化:比如 618、双11,新年大促搞活动等场景,预估我们的流量会大涨,甚至到原来的数倍。这时候要做好应对的措施。
2、初始系统容量评估:假设我们开发了某个系统,这个系统初始上线,我们预估他的容量和负载会是多少。
3、容量基数的变化:比如某个系统,他的功能模块越来越多,数据流量越来越大,日活指数越来越高,迎来了第二波的增长曲线。我们原来定好的系统容量渐渐的不满足我们的需求,这时候我们也要重新评估和扩容。
系统设计容量评估的步骤:
1、分析日总访问量:产品、运营的评估和线上数据的收集
2、评估日平均访问量QPS:评估运营时间内的平均QPS
3、评估高峰区间的QPS:流量曲线计算 或 28 法则估算
4、性能压力测试:评估实例能够承受的极限吞吐量
5、根据线上冗余度,与实际的差值进行调整,评估出能承载容量的实际结果值
显然,开头的运动会如果子报名结束后能够根据报名的人数对比,重新做容量设计,提早做好准备,情况就不会那么糟糕。
本文转自 https://www.cnblogs.com/wzh2010/p/14454954.html,如有侵权,请联系删除。












