
作者:京东零售 申磊
一、开篇
自LLM在自然语言处理等领域取得了瞩目成就之后,学术界积极探索生成式模型对搜广推系统的增强或改进方式[1],现有工作大体可以分为两类[2]:(1)用大模型做数据和知识增强、提取表征、通过prompt将推荐转成对话驱动的任务等,本质上没有修改LLM,属于信息增强和补充方法,无法直接建模海量协同信号。 (2)修改LLM直接建模搜广推海量数据中的协同信号,对输入输出范式改造,通过预训练/微调等过程建模海量数据,让模型同时拥有通用的世界知识和垂直领域海量协同信息。是能实现搜广推大模型scaling的前提,需要更复杂的工程架构支持。第一类工作层出不穷,第二类工作是搜广推值得探索的前沿方向之一。2024年至今,业界在第二类工作中也有一些相关进展和成果,例如,GR(Meta)[3]、HLLM(字节)[4]、NoteLLM(小红书)[5]、NoteLLM-2(小红书)[6]、OneRec(快手)[7]。
CPS算法组也在生成式推荐方向上进行了一系列工作,在探索前沿技术的同时提升业务效果。关于生成式推荐系统、CPS联盟广告、以及第一阶段的工作内容介绍可以参考我之前撰写的文章: 生成式推荐系统与京东联盟广告-综述与应用。下面,我将介绍在此文章发布之后的近期工作进展。本文进一步梳理了业务需求,并以此总结出核心技术点,针对CPS广告的特点,对前链路的用户意图和后链路的多目标进行感知和建模,从而进行推荐全链路优化。
二、业务需求&核心技术点
CPS广告推荐主要针对站外用户进行多场景推荐。业务需求包括精准感知用户意图、进行多目标优化以兼顾收益与用户活跃度,以及利用和兼容多种场景和任务数据。围绕这些需求,我聚焦于显式意图感知的可控商品推荐、推荐效果的多目标优化、One4All生成式推荐框架这三项核心技术,分别对应生成式模型的指令遵循微调阶段、偏好对齐阶段以及数据到模型的全流程范式。

CPS广告推荐业务需求与核心技术点的关系
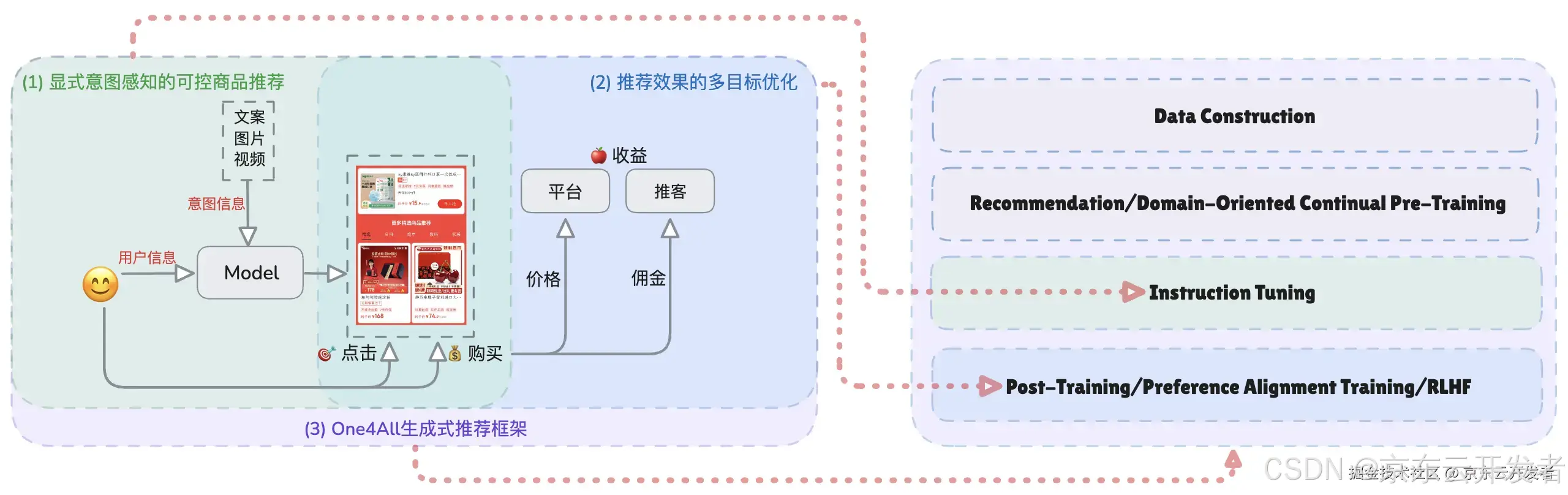
CPS广告推荐的核心技术点与生成式推荐框架
三、显式意图感知的可控商品推荐
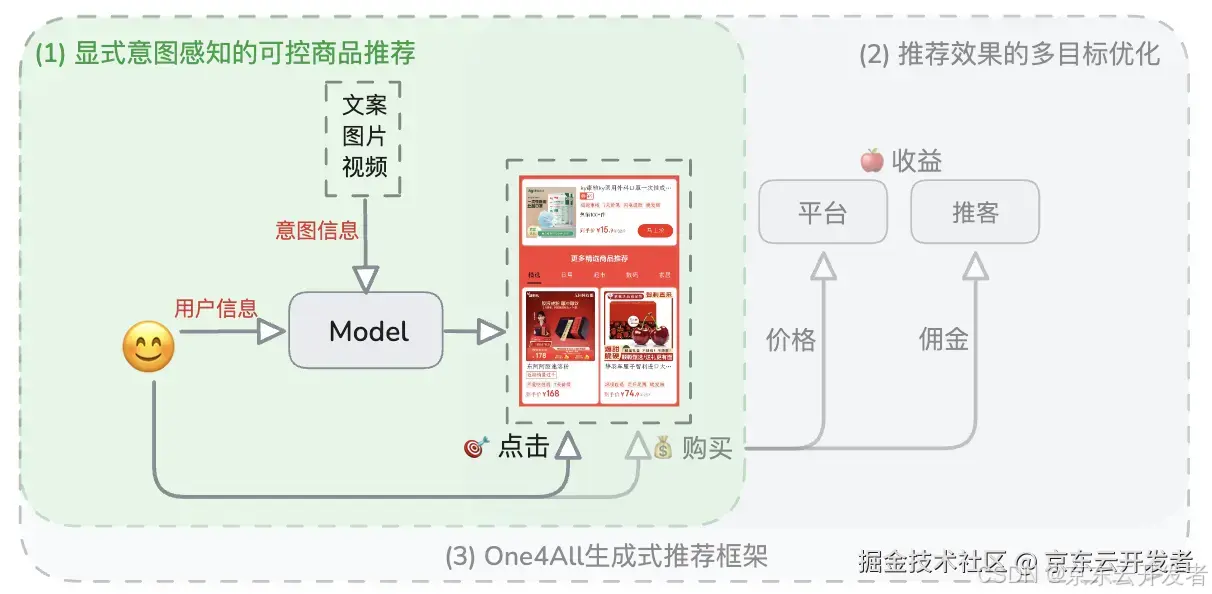
显式意图感知的可控商品推荐示意图
背景介绍
现有方案汇总
落地页商品推荐是站外广告很重要的一种形式,对应的研究课题是触发诱导推荐 (Trigger-Induced Recommendation, TIR),现有方案包含如下三类:
•基于历史行为序列隐式建模用户意图;
•利用触发项进行I2I召回或通过sku2query生成搜索词再进行商品检索;
•通过三个网络来分别表示触发项、建模用户历史行为和预估权重来融合前两者,例如,DIHN、DIAN、DEI2N和DUIN[8、9、10、11]。
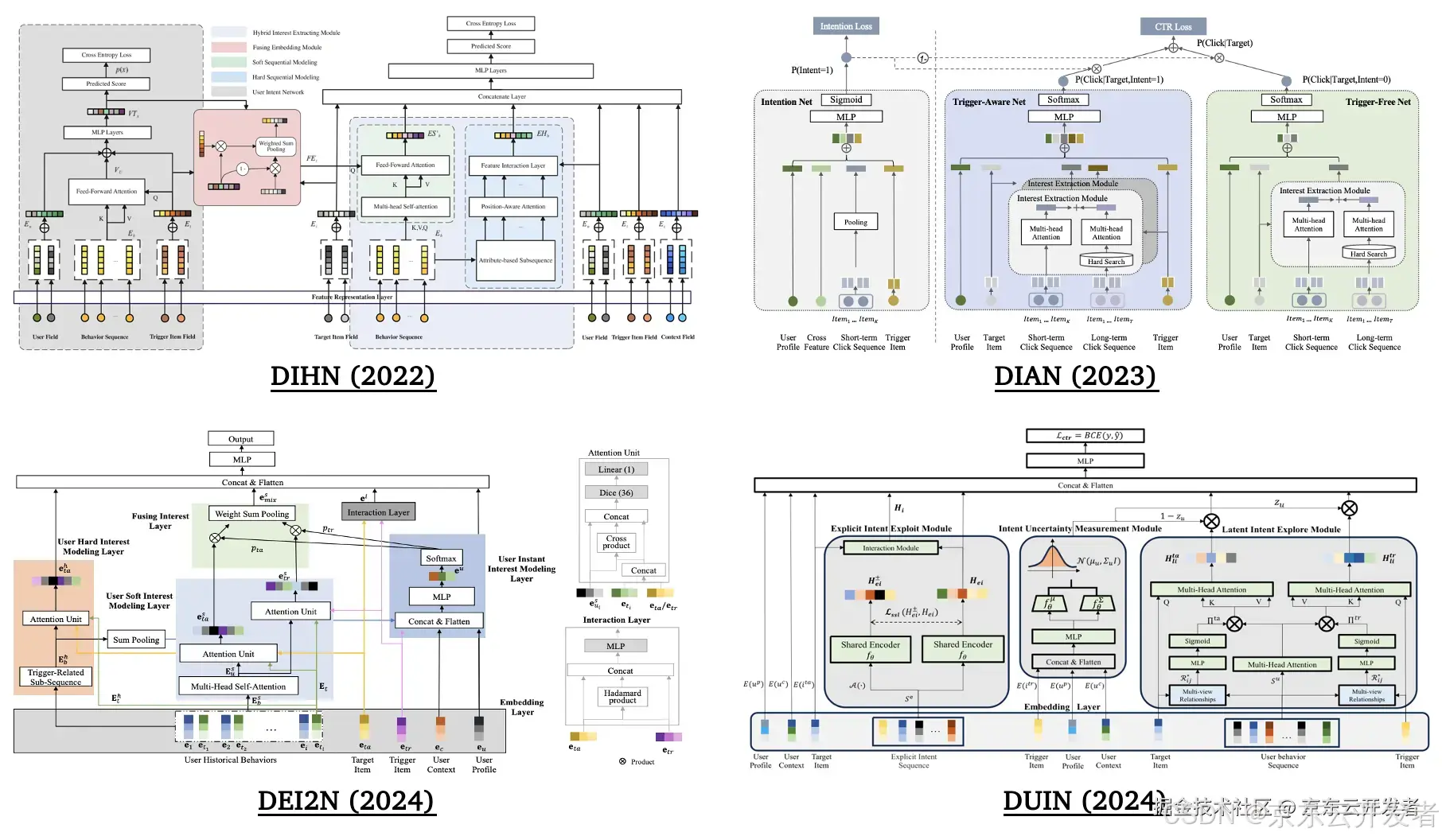
一些触发诱导推荐方案
业务需求&现有方案局限性

显式意图感知的可控商品推荐业务需求与现有方案局限性
解决方案
(1) 通过传统推荐数据自动化地生成丰富的意图描述,以意图文本+历史商品语义ID序列作为输入,目标商品语义ID作为输出的方式 (2) 重构触发诱导推荐的任务范式,利用 (3) 生成式指令遵循微调的方式实现对历史行为和触发项的感知和动态调控。
自动化意图生成和评估
•输入“用户行为数据+目标商品”;
•基于Few-shot Prompting和CoT策略,通过言犀-81B模型对用户行为数据进行总结、推理,并预测当前意图;
•输出“总结-推理-预测”的三元组数据;
•利用Self-Verification的方式对生成的显性意图进行评估。
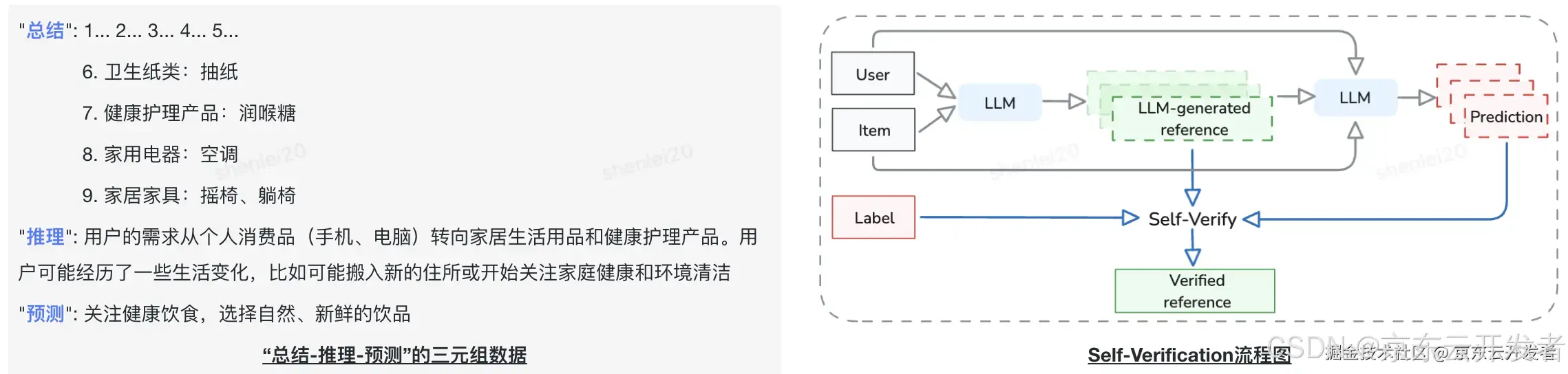
输入输出范式+指令遵循微调
•将数据组织成“Input: [Prompt]. Output: [Response]”的形式,在序列推荐的基础上增加三类任务,其输入输出数据定义如下:

显式意图感知的可控商品推荐任务定义及输入输出示例
方案效果
•离线效果:意图感知的可控模型在HitRate和NDCG指标上,相比非意图感知的模型可提升2~3倍,并且表现出较好的可控能力。
•线上效果:SKUCTR提升3%+,SKUCVR、同店订单和同店佣金也获得显著提升。

样例展示1

样例展示2
四、推荐效果的多目标优化
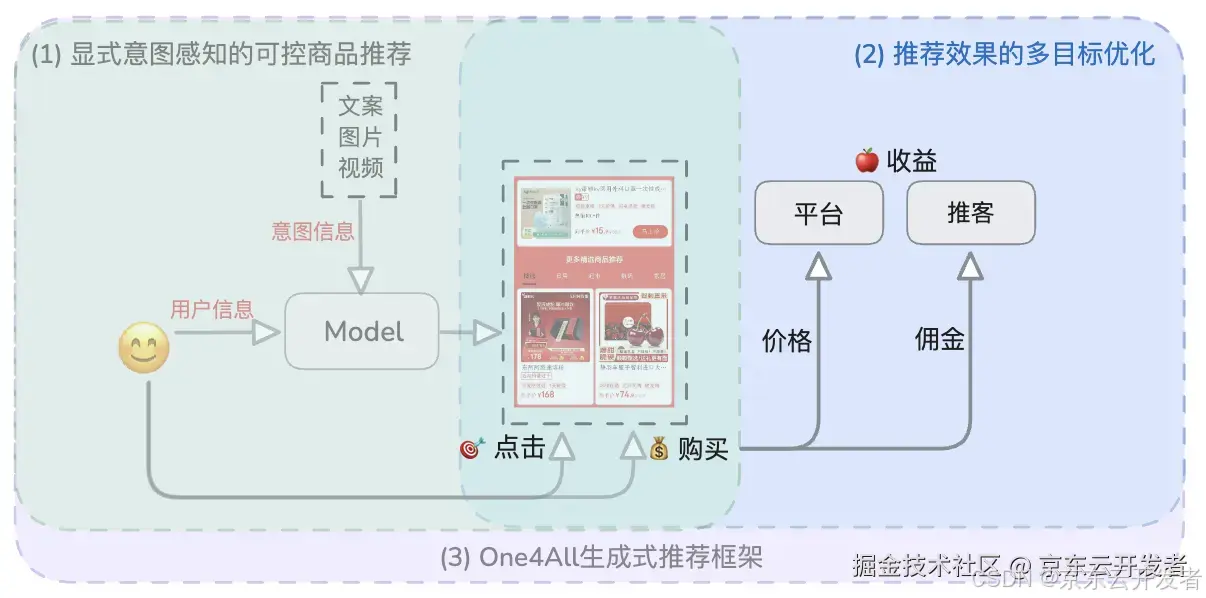
推荐效果的多目标优化示意图
背景介绍
现有方案汇总
非LLM方法
•Shared Bottom、MMOE、PLE:通过共享和独立网络平衡多个任务[12、13];
•ESMM:通过全空间建模解决样本选择偏差问题[14]。
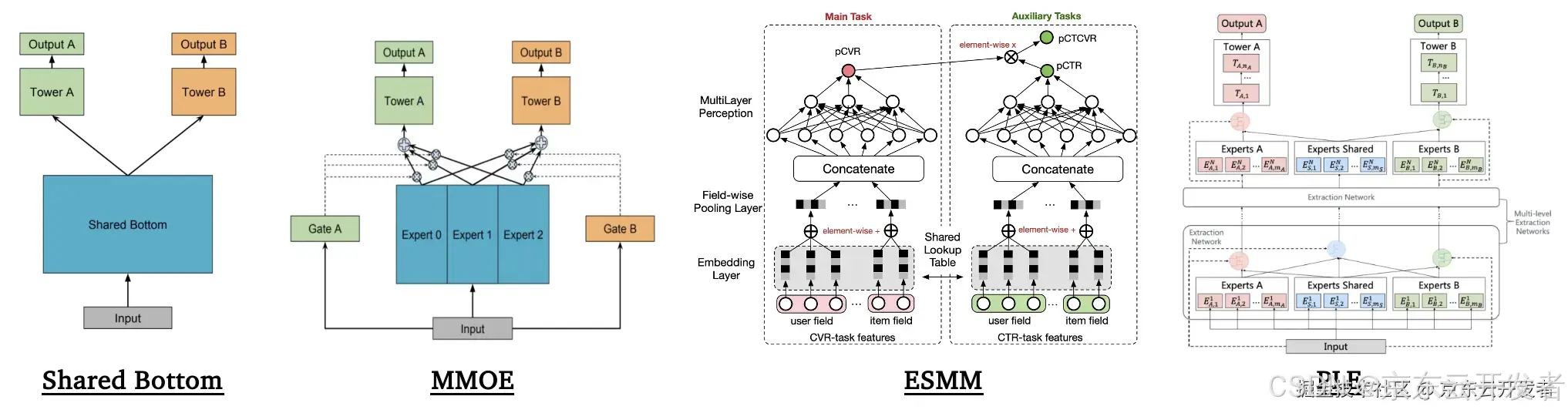
一些多目标优化的非LLM方法
LLM方法
•MORLHF和MODPO:基于RLHF和DPO改进,对多个奖励函数的线性加权[15、16];
•Reward Soups:对多个LLM的权重进行插值[17]。
•

•一些多目标优化的LLM方法
业务需求&现有方案局限性

推荐效果的多目标优化业务需求与现有方案局限性
解决方案
整合行为和价格数据,提高点击到购买的转化率,并最终提升广告收益。
基于DPO的偏好对齐算法
•基于点击商品预测模型,对“购买”偏好进行建模f (点击->购买);
•以“点击且购买”商品作为正例,“点击未购买”商品作为负例,将数据组织成“Input: [Prompt]. Output1: [Response+ ]. Output2: [Response-]”的形式。
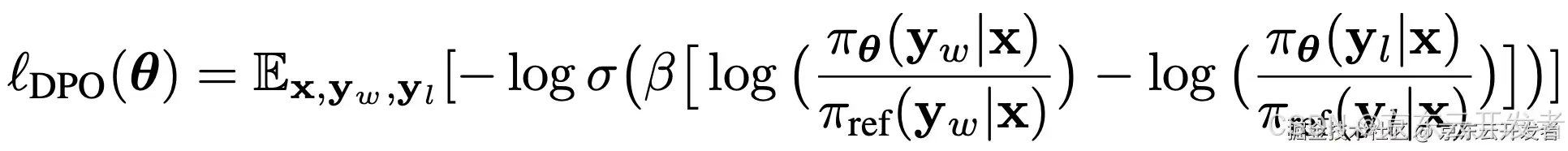
•劣势:DPO[18、19]仅考虑了f(点击->购买),且是正负例间的相对关系,需要将数据组成三元组的形式,没有利用到奖励值。
基于RiC (Rewards-in-Context) 的偏好对齐算法
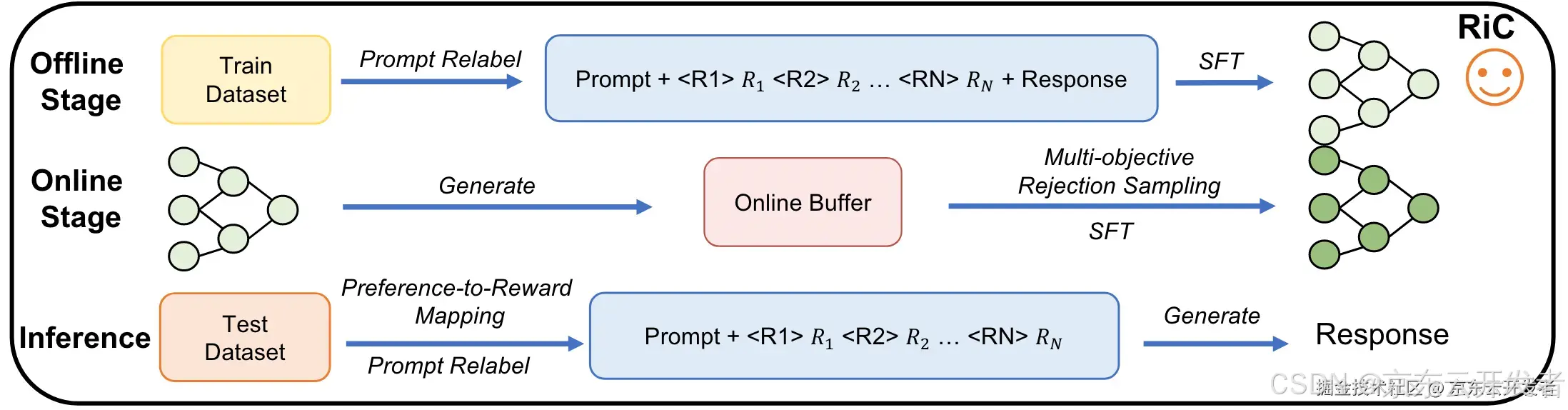
RiC框架图
•离线训练:把行为和收益相关的多种奖励融入数据进行监督微调,让模型学习不同奖励组合下的策略
◦数据形式:“Input: [Prompt]
◦奖励设计:针对点击、购买、价格、佣金奖励进行设计,并归一化。
•在线训练:通过在帕累托前沿上的增强数据来改善数据稀疏问题
◦产生随机提示:在帕累托前沿附近分配奖励,即除一维度外均赋最大值;
◦离线SFT模型生成结果,奖励模型评分,多目标拒绝采样过滤样本。
•推理阶段:利用偏好到奖励的映射,自由适应多样化的用户偏好
•优势:(1) 仅通过监督微调就能实现LLM策略的对齐;(2) 同时利用正面和负面反馈,提升对奖励机制的理解;(3) 扩展性非常强,覆盖多种奖励组合下的多样化表现[20、21、22]。
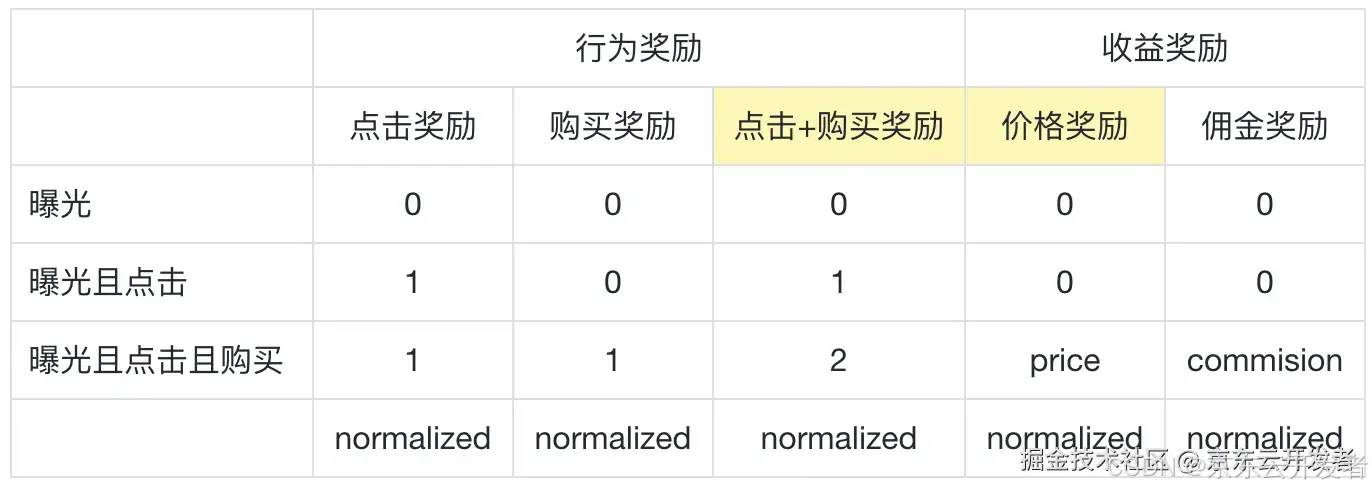
RiC奖励设计方案
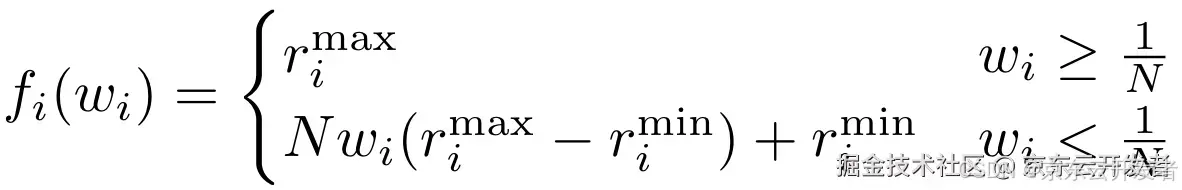
偏好到奖励的映射函数
方案效果
•离线效果:HitRate@1在多个数据集上提升10%+;
•线上效果:SKUCTR提升1.5%+,SKUCVR提升7%+,同店订单和同店佣金也获得显著提升。
五、One4All生成式推荐框架
背景介绍
业务需求
•CPS广告推荐涉及多样的业务场景,需要强化系统的跨场景适应性;
•需要优化框架中的模型更新策略,提升系统实时性与灵活性。
解决方案
设计可扩展框架兼顾行为和语义的理解与生成,提升推荐系统的泛化能力;同时优化模型更新策略,确保系统能够灵活适用于不同任务和场景。
可扩展框架设计
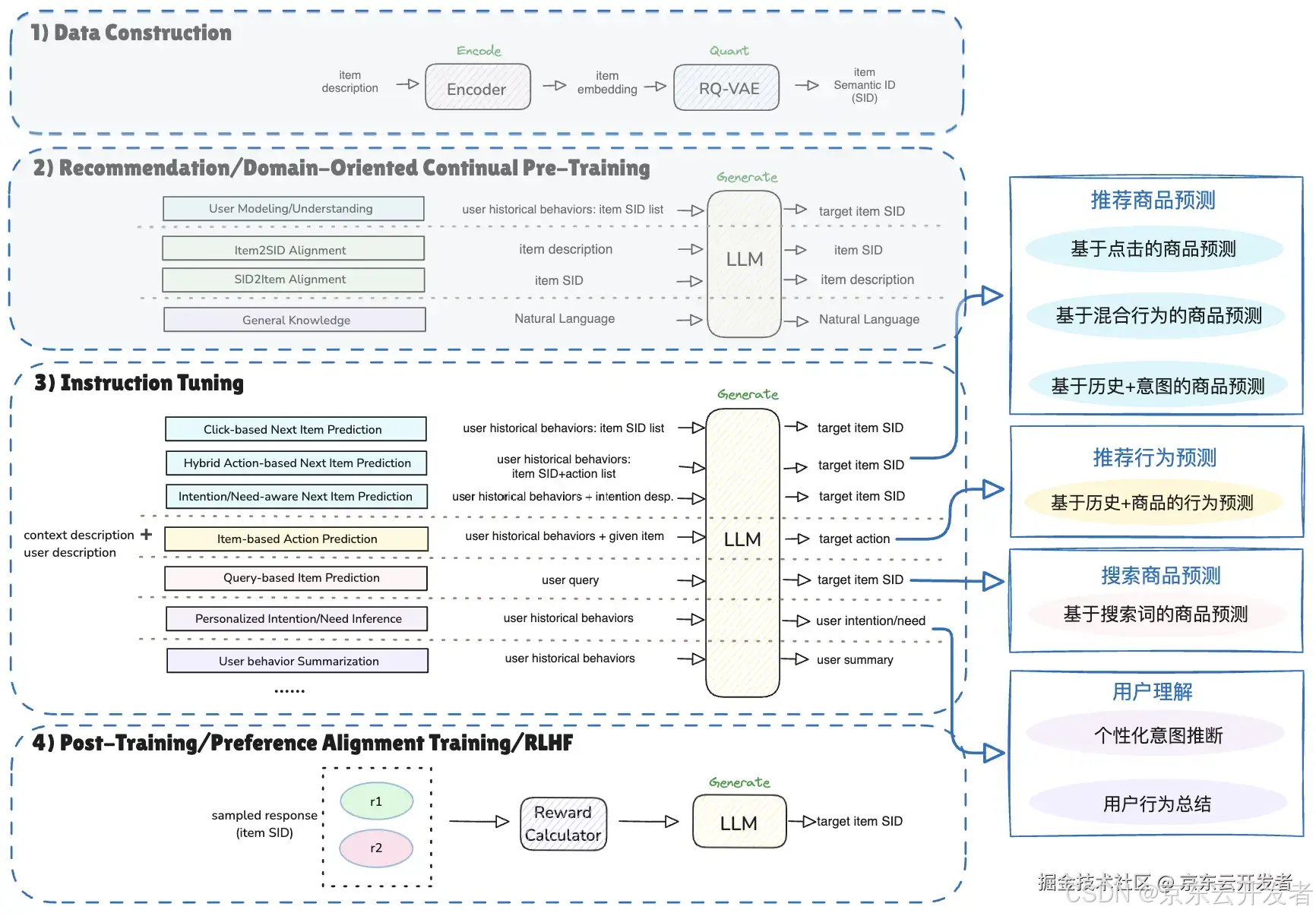
One4All生成式推荐框架示意图
线上模型更新策略

线上模型更新策略
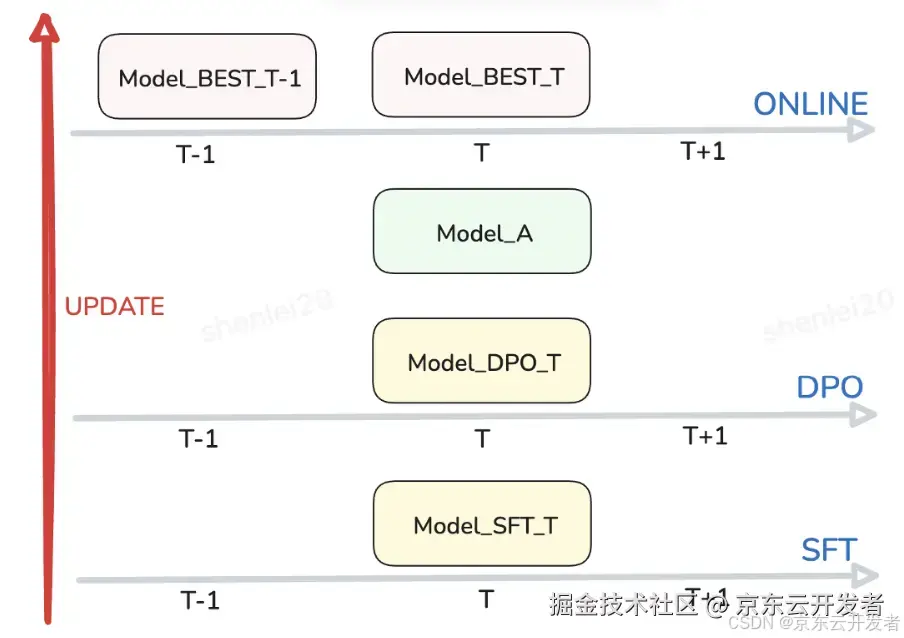
线上模型更新策略示意图
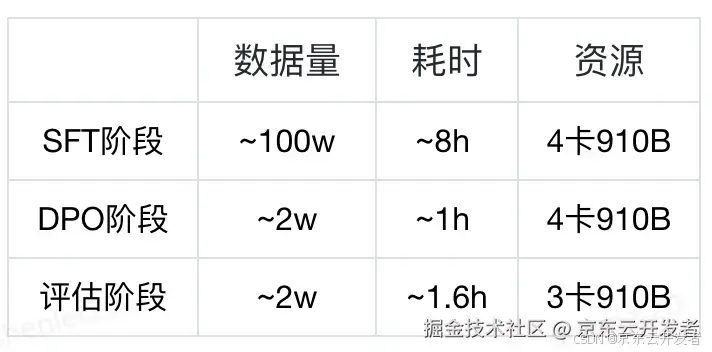
线上例行化更新信息
方案效果
•完成了线上例行化的开发,支撑CPS广告每天1000w+UV的在线实时推理;
•基于One4All生成式推荐框架,在现有序列推荐主任务的基础上兼容更多的行为和语言理解的任务,推动召排一体化、搜推联合建模、用户行为总结、个性化意图推断等技术的探索。
六、总结和未来展望
•交互式推荐系统(搜索推荐联合)
◦现有方案仍未更大限度激发生成式模型的效果和能力,交互式应用是值得尝试的方向,同时需要配合上下游进行产品形式的重构。
•多模态信息理解与生成
◦前链路中有丰富的图片和视频信息,对多模态信息进行高效地理解和内容组织,可以增强推荐效果和提升展示形式的丰富程度。
最后打个小广告:
欢迎对生成式推荐系统感兴趣的同学联系我(erp: shenlei20)一起交流讨论,也欢迎加入我们CPS算法组共同探索下一代交互式搜广推系统!
七、参考文献
1.Xu L, Zhang J, Li B, et al. Prompting large language models for recommender systems: A comprehensive framework and empirical analysis[J]. arXiv preprint arXiv:2401.04997, 2024.
2.知乎《一文梳理工业界大模型推荐实战经验》. 2024
3.Zhai J, Liao L, Liu X, et al. Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations[C]//Proceedings of the 41st International Conference on Machine Learning. 2024: 58484-58509.
4.Chen J, Chi L, Peng B, et al. Hllm: Enhancing sequential recommendations via hierarchical large language models for item and user modeling[J]. arXiv preprint arXiv:2409.12740, 2024.
5.Zhang C, Wu S, Zhang H, et al. Notellm: A retrievable large language model for note recommendation[C]//Companion Proceedings of the ACM Web Conference 2024. 2024: 170-179.
6.Zhang C, Zhang H, Wu S, et al. NoteLLM-2: multimodal large representation models for recommendation[J]. arXiv preprint arXiv:2405.16789, 2024.
7.Deng J, Wang S, Cai K, et al. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment[J]. arXiv preprint arXiv:2502.18965, 2025.
8.Ma J, Xiao Z, Yang L, et al. Modeling User Intent Beyond Trigger: Incorporating Uncertainty for Trigger-Induced Recommendation[C]//Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2024: 4743-4751.
9.Shen Q, Wen H, Tao W, et al. Deep interest highlight network for click-through rate prediction in trigger-induced recommendation[C]//Proceedings of the ACM web conference 2022. 2022: 422-430.
10.Xia Y, Cao Y, Hu S, et al. Deep intention-aware network for click-through rate prediction[C]//Companion Proceedings of the ACM Web Conference 2023. 2023: 533-537.
11.Xiao Z, Yang L, Zhang T, et al. Deep evolutional instant interest network for ctr prediction in trigger-induced recommendation[C]//Proceedings of the 17th ACM International Conference on Web Search and Data Mining. 2024: 846-854.
12.Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1930-1939.
13.Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations[C]//Proceedings of the 14th ACM conference on recommender systems. 2020: 269-278.
14.Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
15.Zhou Z, Liu J, Shao J, et al. Beyond One-Preference-Fits-All Alignment: Multi-Objective Direct Preference Optimization[C]//Findings of the Association for Computational Linguistics ACL 2024. 2024: 10586-10613.
16.Li K, Zhang T, Wang R. Deep reinforcement learning for multi-objective optimization[J]. IEEE transactions on cybernetics, 2020, 51(6): 3103-3114.
17.Rame A, Couairon G, Dancette C, et al. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards[J]. Advances in Neural Information Processing Systems, 2023, 36: 71095-71134.
18.Rafailov R, Sharma A, Mitchell E, et al. Direct preference optimization: Your language model is secretly a reward model[J]. Advances in Neural Information Processing Systems, 2023, 36: 53728-53741.
19.Wu J, Xie Y, Yang Z, et al. beta-DPO: Direct Preference Optimization with Dynamic beta[J]. Advances in Neural Information Processing Systems, 2025, 37: 129944-129966.
20.Lin X, Chen H, Pei C, et al. A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation[C]//Proceedings of the 13th ACM Conference on recommender systems. 2019: 20-28.
21.Hu J, Tao L, Yang J, et al. Aligning language models with offline learning from human feedback[J]. arXiv preprint arXiv:2308.12050, 2023.
22.Yang R, Pan X, Luo F, et al. Rewards-in-context: multi-objective alignment of foundation models with dynamic preference adjustment[C]//Proceedings of the 41st International Conference on Machine Learning. 2024: 56276-56297.


