MySQL 那些常见的错误设计规范
依托于互联网的发达,我们可以随时随地利用一些等车或坐地铁的碎片时间学习以及了解资讯。同时发达的互联网也方便人们能够快速分享自己的知识,与相同爱好和需求的朋友们一起共同讨论。
但是过于方便的分享也让知识变得五花八门,很容易让人接收到错误的信息。这些错误最多的都是因为技术发展迅速,而且没有空闲时间去及时更新已经发布的内容所导致。为了避免给后面学习的人造成误解,我们今天来看一看 MySQL 设计规范中几个常见的错误例子。
主键的设计
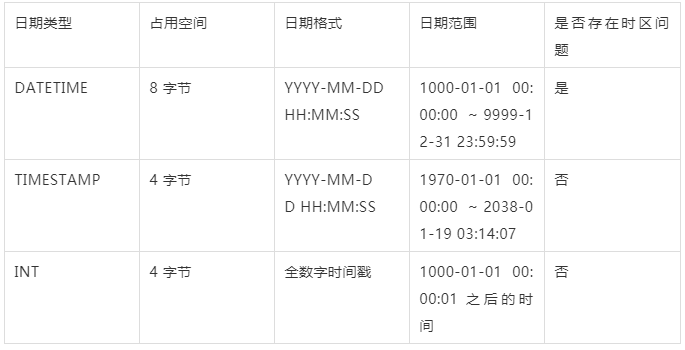
错误的设计规范:主键建议使用自增 ID 值,不要使用 UUID,MD5,HASH,字符串作为主键
这个设计规范在很多文章中都能看到,自增主键的优点有占用空间小,有序,使用起来简单等优点。
下面先来看看自增主键的缺点:
- 自增值由于在服务器端产生,需要有一把自增的 AI 锁保护,若这时有大量的插入请求,就可能存在自增引起的性能瓶颈,所以存在并发性能问题;
- 自增值做主键,只能在当前实例中保证唯一,不能保证全局唯一,这就导致无法在分布式架构中使用;
- 公开数据值,容易引发安全问题,如果我们的商品 ID 是自增主键的话,用户可以通过修改 ID 值来获取商品,严重的情况下可以知道我们数据库中一共存了多少商品。
- MGR(MySQL Group Replication) 可能引起的性能问题;
因为自增值是在 MySQL 服务端产生的值,需要有一把自增的 AI 锁保护,若这时有大量的插入请求,就可能存在自增引起的性能瓶颈。比如在 MySQL 数据库中,参数 innodb_autoinc_lock_mode 用于控制自增锁持有的时间。虽然,我们可以调整参数 innodb_autoinc_lock_mode 获得自增的最大性能,但是由于其还存在其它问题。因此,在并发场景中,更推荐 UUID 做主键或业务自定义生成主键。
我们可以直接在 MySQ L 使用 UUID () 函数来获取 UUID 的值。
MySQL> select UUID();
+--------------------------------------+
| UUID() |
+--------------------------------------+
| 23ebaa88-ce89-11eb-b431-0242ac110002 |
+--------------------------------------+
1 row in set (0.00 sec)需要特别注意的是,在存储时间时,UUID 是根据时间位逆序存储, 也就是低时间低位存放在最前面,高时间位在最后,即 UUID 的前 4 个字节会随着时间的变化而不断 “随机” 变化,并非单调递增。而非随机值在插入时会产生离散 IO,从而产生性能瓶颈。这也是 UUID 对比自增值最大的弊端。
为了解决这个问题,MySQL 8.0 推出了函数 UUID_TO_BIN,它可以把 UUID 字符串:
- 通过参数将时间高位放在最前,解决了 UUID 插入时乱序问题;
- 去掉了无用的字符串 "-",精简存储空间;
- 将字符串其转换为二进制值存储,空间最终从之前的 36 个字节缩短为了 16 字节。
下面我们将之前的 UUID 字符串 23ebaa88-ce89-11eb-b431-0242ac110002 通过函数 UUID_TO_BIN 进行转换,得到二进制值如下所示:
MySQL> SELECT UUID_TO_BIN('23ebaa88-ce89-11eb-b431-0242ac110002',TRUE) as UUID_BIN;
+------------------------------------+
| UUID_BIN |
+------------------------------------+
| 0x11EBCE8923EBAA88B4310242AC110002 |
+------------------------------------+
1 row in set (0.01 sec)除此之外,MySQL 8.0 也提供了函数 BIN_TO_UUID,支持将二进制值反转为 UUID 字符串。
虽然 MySQL 8.0 版本之前没有函数 UUID_TO_BIN/BIN_TO_UUID,还是可以通过自定义函数的方式解决。应用层的话可以根据自己的编程语言编写相应的函数。
当然,很多同学也担心 UUID 的性能和存储占用的空间问题,这里我也做了相关的插入性能测试,结果如下表所示:

可以看到,MySQL 8.0 提供的排序 UUID 性能最好,甚至比自增 ID 还要好。此外,由于 UUID_TO_BIN 转换为的结果是 16 字节,仅比自增 ID 增加 8 个字节,最后存储占用的空间也仅比自增大了 3G。
而且由于 UUID 能保证全局唯一,因此使用 UUID 的收益远远大于自增 ID。可能你已经习惯了用自增做主键,但是在并发场景下,更推荐 UUID 这样的全局唯一值做主键。
当然了,UUID 虽好,但是在分布式场景下,主键还需要加入一些额外的信息,这样才能保证后续二级索引的查询效率,推荐根据业务自定义生成主键。但是在并发量和数据量没那么大的情况下,还是推荐使用自增 UUID 的。大家更不要以为 UUID 不能当主键了。
金融字段的设计
错误的设计规范:同财务相关的金额类数据必须使用 decimal 类型 由于 float 和 double 都是非精准的浮点数类型,而 decimal 是精准的浮点数类型。所以一般在设计用户余额,商品价格等金融类字段一般都是使用 decimal 类型,可以精确到分。
但是在海量互联网业务的设计标准中,并不推荐用 DECIMAL 类型,而是更推荐将 DECIMAL 转化为整型类型。 也就是说,金融类型更推荐使用用分单位存储,而不是用元单位存储。如 1 元在数据库中用整型类型 100 存储。
下面是 bigint 类型的优点:
- decimal 是通过二进制实现的一种编码方式,计算效率不如 bigint
- 使用 bigint 的话,字段是定长字段,存储高效,而 decimal 根据定义的宽度决定,在数据设计中,定长存储性能更好
- 使用 bigint 存储分为单位的金额,也可以存储千兆级别的金额,完全够用
枚举字段的使用
错误的设计规范:避免使用 ENUM 类型
在以前开发项目中,遇到用户性别,商品是否上架,评论是否隐藏等字段的时候,都是简单的将字段设计为 tinyint,然后在字段里备注 0 为什么状态,1 为什么状态。
这样设计的问题也比较明显:
- 表达不清:这个表可能是其他同事设计的,你印象不是特别深的话,每次都需要去看字段注释,甚至有时候在编码的时候需要去数据库确认字段含义
- 脏数据:虽然在应用层可以通过代码限制插入的数值,但是还是可以通过 sql 和可视化工具修改值
这种固定选项值的字段,推荐使用 ENUM 枚举字符串类型,外加 SQL_MODE 的严格模式
在 MySQL 8.0.16 以后的版本,可以直接使用 check 约束机制,不需要使用 enum 枚举字段类型
而且我们一般在定义枚举值的时候使用 "Y","N" 等单个字符,并不会占用很多空间。但是如果选项值不固定的情况,随着业务发展可能会增加,才不推荐使用枚举字段。
索引个数限制
错误的设计规范:限制每张表上的索引数量,一张表的索引不能超过 5 个
MySQL 单表的索引没有个数限制,业务查询有具体需要,创建即可,不要迷信个数限制
子查询的使用
错误的设计规范:避免使用子查询
其实这个规范对老版本的 MySQL 来说是对的,因为之前版本的 MySQL 数据库对子查询优化有限,所以很多 OLTP 业务场合下,我们都要求在线业务尽可能不用子查询。
然而,MySQL 8.0 版本中,子查询的优化得到大幅提升,所以在新版本的 MySQL 中可以放心的使用子查询。
子查询相比 JOIN 更易于人类理解,比如我们现在想查看 2020 年没有发过文章的同学的数量
SELECT COUNT(*)
FROM user
WHERE id not in (
SELECT user_id
from blog
where publish_time >= "2020-01-01" AND publish_time <= "2020-12-31"
)可以看到,子查询的逻辑非常清晰:通过 not IN 查询文章表的用户有哪些。
如果用 left join 写
SELECT count(*)
FROM user LEFT JOIN blog
ON user.id = blog.user_id and blog.publish_time >= "2020-01-01" and blog.publish_time <= "2020-12-31"
where blog.user_id is NULL;可以发现,虽然 LEFT JOIN 也能完成上述需求,但不容易理解。
我们使用 explain 查看两条 sql 的执行计划,发现都是一样的

通过上图可以很明显看到,不论是子查询还是 LEFT JOIN,最终都被转换成了 left hash Join,所以上述两条 SQL 的执行时间是一样的。即,在 MySQL 8.0 中,优化器会自动地将 IN 子查询优化,优化为最佳的 JOIN 执行计划,这样一来,会显著的提升性能。
总结
阅读完前面的内容相信大家对 MySQL 已经有了新的认知,想要实战演练的朋友可以在3A云服务器上部署环境进行试验,这些常见的错误可以总结为以下几点:
- UUID 也可以当主键,自增 UUID 比自增主键性能更好,多占用的空间也可忽略不计
- 金融字段除了 decimal,也可以试试 bigint,存储分为单位的数据
- 对于固定选项值的字段,MySQL8 以前推荐使用枚举字段,MySQL8 以后使用 check 函数约束,不要使用 0,1,2 表示
- 一张表的索引个数并没有限制不能超过 5 个,可以根据业务情况添加和删除
- MySQL8 对子查询有了优化,可以放心使用。