引用近年,大模型技术加速演进,从通用对话、图文生成到多模态理解,AI能力持续跃升。模型愈强,对训练数据的要求也愈加严苛,尤其在数据标注环节,精度、复杂度和效率的门槛被不断抬高。在此背景下,标注员角色该如何进化? 数据堂作为国内领先的AI数据服务商,凭借专业化标注人才库、规模化标注基地、智能化标注工具,助力企业应对大模型时代的数据标注难题,本文将深入探讨标注行业的新挑战,并解析数据堂的解决方案如何精准匹配市场需求。

大模型时代,数据标注的三大挑战!
标注规范日趋复杂:从"对错判断"到"多维评价"
大模型训练对数据质量的要求已从简单的"正确/错误"判断,升级为复杂的多维度综合评价。以偏好数据标注为例,除准确性之外,标注员还需从相关性、简洁性、创造力、事实性等多个维度进行加权评估,这要求标注员具备更强的逻辑分析能力和审美判断力。
这种复杂的评价体系,相应地也提高了对标注员学历背景和综合素质的要求——具备本科及以上学历、逻辑思维清晰的标注员,更能胜任这类需要深度理解和判断的工作。
标注任务复杂化:从"机械操作"到"专业认知"
传统AI时代的标注工作主要考验的是标注员的耐心和细致程度,任务多集中在基础性的打标签、画框等重复操作层面。在大模型时代,标注工作已升级为需要专业背景支撑的认知型工作。
这种转变使得标注员不再是简单的数据加工者,而是AI价值观的塑造者、推理链条的设计者和交互能力的培养者。特别是涉及到医疗、法律、数学等专业领域,标注员必须具备相关学科背景知识、具备相关的专业标注经验,才能更高效执行标注项目。
规模化需求激增:既要“快”,又要“稳”
大模型训练通常需要千万级甚至亿级的标注数据,传统小团队模式难以满足需求,企业面临自建团队成本高和外包质量难把控的两难困境。招募、培训、管理投入巨大,而松散合作的标注团队又存在效率低、一致性差的问题,亟需更高效的解决方案。
数据堂如何构建新时代专业标注力量
作为世界一流的训练数据供应商,数据堂不仅深耕高质量数据生产,更致力于打造具备持续交付能力的标注服务体系。
专业标注人才库:精准匹配大模型需求
数据堂拥有10万+覆盖全球的标注员,支持多语言、多领域标注,并通过基础标注员、专业背景标注员、行业专家等分层管理确保复杂任务落地。同时能够快速组建百人级专项团队,高效灵活应对客户的需求。
数据堂的标注人才库中,高素质人才占比显著提升,其中,具有本科及以上学历的专业人才占比超过60%,其中不乏医学、法学、语言学等专业背景的复合型人才,确保能够胜任大模型时代对高质量标注的需求。
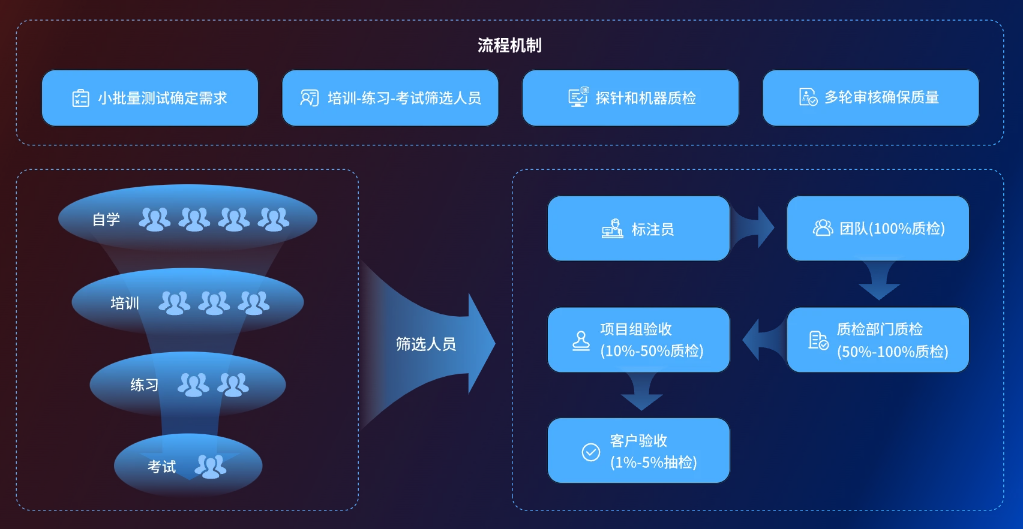
数据堂实行完善的标注员筛选机制,经历自学、培训、练习、考试4项流程,确保为客户选择最合适的标注团队。练习模块有助于标注人员快速掌握标注实操技能,对齐标注规范要求。同时,为通过考试人员颁发资质,提升团队人员筛选效率。针对专业级别的标注员,数据堂不定期举办高级培训课程,确保标注团队不断精进,满足各类标注需求。
自建标注基地:质量与安全的双重保障
数据堂构建了覆盖全球多地的高标准标注基地网络,以“自建+全职”模式确保数据质量与交付效率。在国内,北京、保定、合肥、三大核心基地配备专业全职团队,专注3D点云、语音识别等复杂标注;内蒙古、广西、山西等特色基地则深耕多语言语音、方言标注等细分领域。所有基地均配备保密工作室,独立门禁带监控,标注员终端电脑USB物理封口,确保作业过程的机密性。

智能标注工具:让“人效”最大化
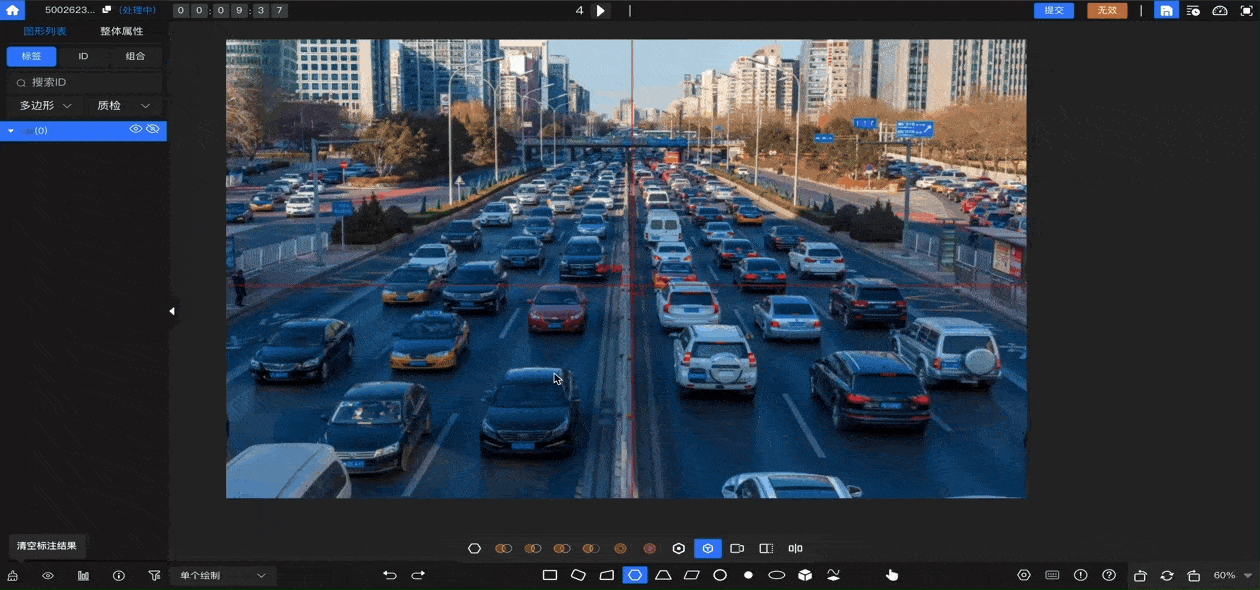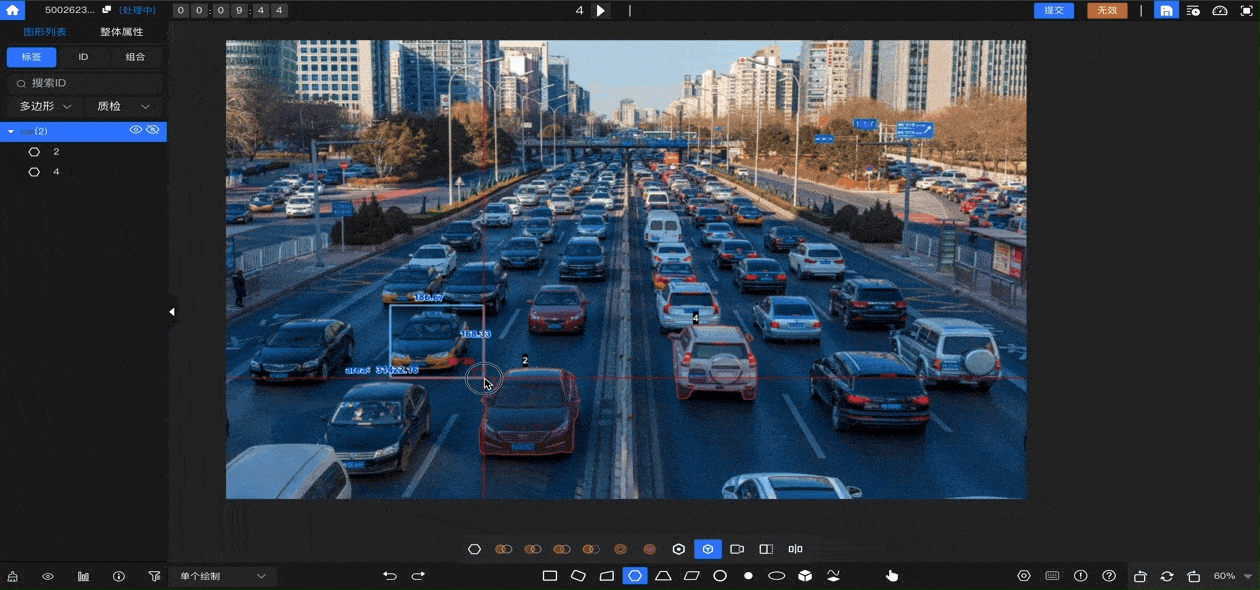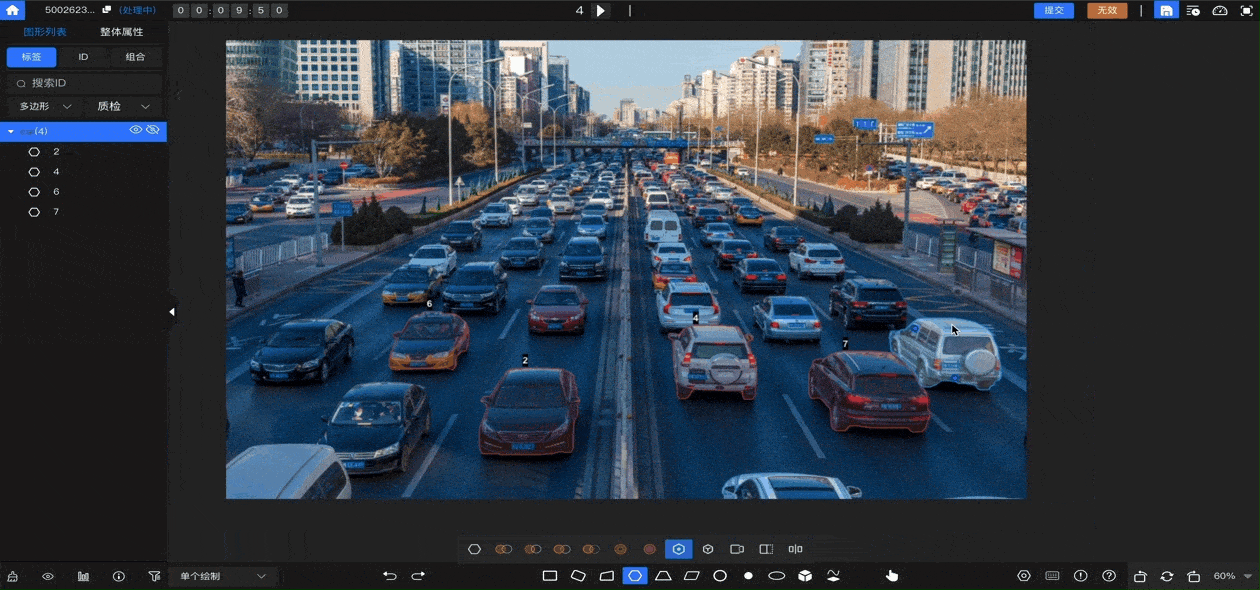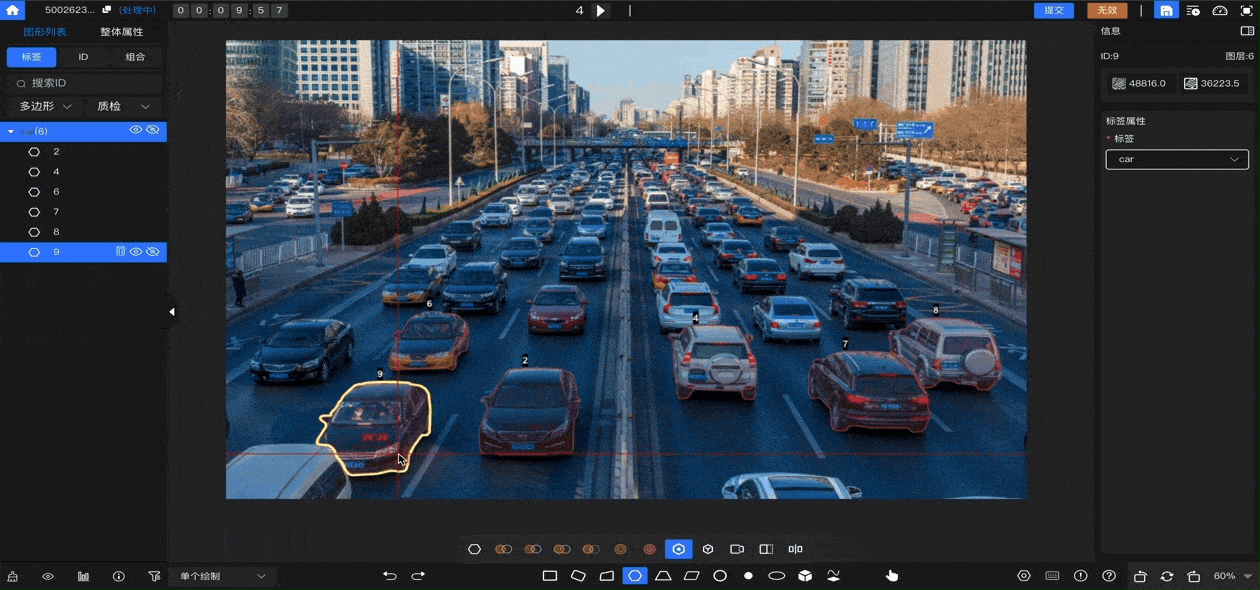
数据堂的智能标注工具集成AI预标注功能,可支持本地预识别能力接入和第三方预识别模型接入,全面提升标注效率。针对大模型时代特有的、标注规范无法细致描述、需依赖主观判断的标注场景,标注平台支持“拟合”流程设计。采取多人共同实施一条数据的方式,根据系统设定的拟合规则和拟合数量进行判别,拟合成功后才会提交质检。搭配多轮质检流程,真正做到精准高效交付。
大模型是AI领域的“工业革命”,而数据标注是这场革命的“基础工程”。标注员的角色,正在从幕后走向幕前,从执行者变为“AI教练”。数据堂将持续打造以人才、平台、交付能力为核心的智能数据生产体系,为每一个有志于AI产业的合作伙伴,提供值得信赖的数据底座。