推荐
专栏
教程
课程
飞鹅
本次共找到1471条
tcp超时重传机制
相关的信息
简
•
4年前
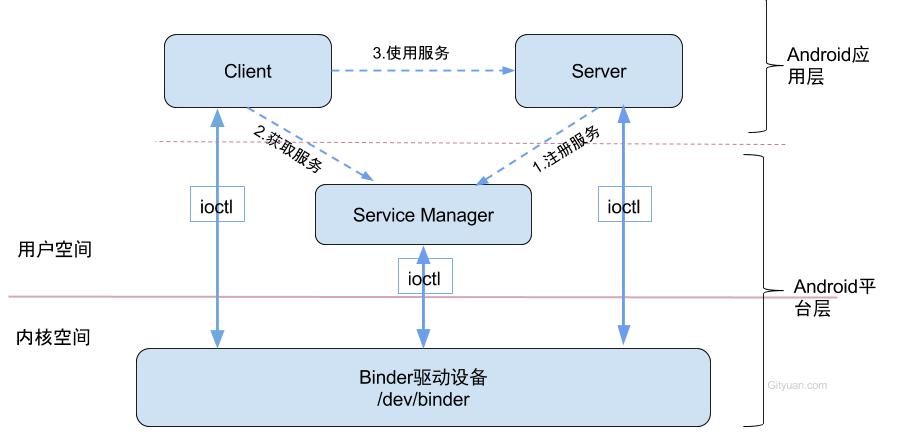
Binder Driver缺陷导致定屏的案例
本文讲解异步bindercall是如何阻塞整个系统的,通过ramdump信息以及binder通信协议来演绎并还原定屏现场。一、背景知识点解决此问题所涉及到的基础知识点有:Trace、CPU调度、Ramdump推导、Crash工具、GDB工具、Ftrace,尤其深入理解binderIPC机制。1.1工具简介Trace:分析死锁
DevOpSec
•
5年前
Kubernetes(k8s)中文文档 Kubernetes概述
简介Kubernetes(https://www.kubernetes.org.cn/)是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。Kubernetes一个核心的特点就是能够自主的管理容
Stella981
•
4年前
LVS DR +keepalived配置
LVSDRkeepalived配置我们先来看看为什么要引入keepalived,前面的lvs虽然已经配置成功也实现了负载均衡,但是我们测试的时候发现,当某台realserver把nginx停掉,那么director照样会把请求转发过去,这样就造成了某些请求不正常。所以需要有一种机制用来检测realserver的状
Wesley13
•
4年前
ActiveMQ
前言JMS的消息确认模式,定义了客户端(消息发送者或者消费者)与broker确认消息的方式,可以认为是客户端与Broker之间建立一种简单的“担保”机制。在java的JMS标准中,javax.jms.Session包定义了4种消息确认模式,分别是:\\AUTO\_ACKNOWLEDGE:\\自动确认\\
Stella981
•
4年前
Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述1、MapReduce中,mapper阶段处理的数据如何传递给reducer阶段,是MapReduce框架中最关键的一个流程,这个流程就叫Shuffle2、Shuffle:数据混洗——(核心机制:数据分区,排序,局部聚合,缓存,拉取,再合并排序)3、具体来说:就是将MapTask输出的处理结果数据,按照Par
Wesley13
•
4年前
Java知识图谱
1JVM1.内存模型(内存分为几部分?堆溢出、栈溢出原因及实例?线上如何排查?)2.类加载机制3.垃圾回收2Java基础什么是接口?什么是抽象类?区别是什么?什么是序列化?网络通信过程及实践什么是线程?java线程池运行过程及实践(Exec
Stella981
•
4年前
Hyperledger Fabric节点Gossip实验完整记录
Gossip在HyperledgerFabric中发挥着重要的作用。在这个教程中,我们将分阶段考察Fabric网络启动时gossip的运行机制,学习Fabric中的一些核心概念,例如主导节点/leader、锚节点/anchor等,理解gossip是如何帮助HyperledgerFabric成为一个可伸缩的联盟链平台。HyperledgerFa
Wesley13
•
4年前
60分钟视频带你掌握NLP BERT理论与实战
向AI转型的程序员都关注了这个号👇👇👇机器学习AI算法工程 公众号:datayx本课程会介绍最近NLP领域取得突破性进展的BERT模型。首先会介绍一些背景知识,包括WordEmbedding、RNN/LSTM/GRU、Seq2Seq模型和Attention机制等。然后介绍BERT的基础Transformer模
Stella981
•
4年前
JavaScript性能优化
❝性能优化是一个很大的概念,性能优化的方向有很多比如底层、框架层面上、页面上等等,本篇文章介绍的是JavaScript语言的优化,了解JavaScript的运行的机制❞本片文章主要从如下几个方面讲解:内存管理垃圾回收与常见GC算法V8引擎的垃圾回收Perf
Wesley13
•
4年前
Java并发编程指南
多线程是实现并发机制的一种有效手段。在Java中实现多线程有两种手段,一种是继承Thread类,另一种就是实现Runnable/Callable接口。 java.util.concurrent包是专为Java并发编程而设计的包。类图如下:!(https://oscimg.oschina.net/oscnet/29ddbb
1
•••
98
99
100
•••
148