推荐
专栏
教程
课程
飞鹅
本次共找到996条
svm算法
相关的信息
Souleigh ✨
•
4年前
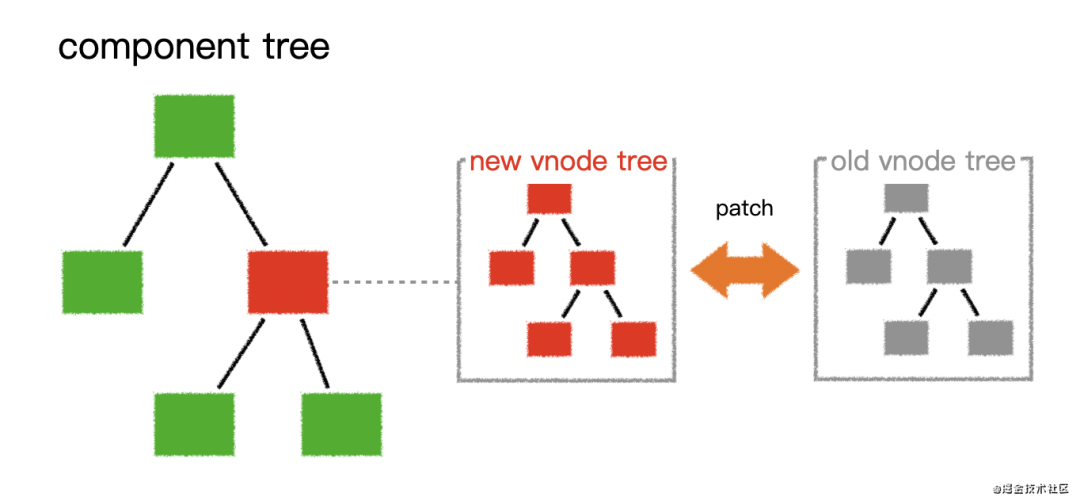
Vue - diff 算法
diff是什么?diff就是比较两棵树,render会生成两颗树,一棵新树newVnode,一棵旧树oldVnode,然后两棵树进行对比更新找差异就是diff,全称difference,在vue里面diff算法是通过patch函数来完成的,所以有的时候也叫patch算法⏳diff发生的时机diff发生在什么时候呢?当然我们可以说在数据更新的时候发生d
Easter79
•
4年前
Vue diff 算法
一、虚拟DOM(virtualdom) diff算法首先要明确一个概念就是diff的对象是虚拟DOM(virtualdom),更新真实DOM是diff算法的结果。 注:virtualdom 可以看作是一个使用JavaScript模拟了DOM结构的树形结构,这个树结构包含
Souleigh ✨
•
5年前
JS排序算法
引子有句话怎么说来着:雷锋推倒雷峰塔,JavaimplementsJavaScript.当年,想凭借抱Java大腿火一把而不惜把自己名字给改了的JavaScript(原名LiveScript),如今早已光芒万丈。nodeJS的出现更是让JavaScript可以前后端通吃。虽然Java依然制霸企业级软件开发领域(C/C的大神们不要打
Stella981
•
4年前
LeetCode算法题
这是悦乐书的第258次更新,第271篇原创<br/01看题和准备今天介绍的是LeetCode算法题中Easy级别的第125题(顺位题号是551)。您将获得一个表示学生出勤记录的字符串。该记录仅包含以下三个字符:'A':缺席。'L':迟到。'P':在场。如果学生的出勤记录不超过一个“A”(缺席)或超过两个
Wesley13
•
4年前
BFS经典算法
1\.Bipartite:Determineifanundirectedgraphisbipartite.Abipartitegraphisoneinwhichthenodescanbedividedintotwogroupssuchthatnonodeshavedirectedgestoo
Stella981
•
4年前
LightGBM 算法原理
LightGBM的动机GBDT(GradientBoostingDecisionTree)是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT在工业界应用广泛,通常被用于点击率预测,搜索排序等任务而GBDT在每一次迭代的时
Wesley13
•
4年前
KNN算法详解
简单的说,K近邻算法是采用不同特征值之间的距离方法进行分类。 该方法优点:精确值高、对异常值不敏感、无数据输入假定 缺点:计算复杂度高、空间复杂度高 适用范围:数据型和标称型 现在我们来讲KNN算法的工作原理:存在一个样本数据集,也称作训练样本集,并且样本中每条数据都存在标签。将新输入的没有标签的数据与训练样本数据集中
Wesley13
•
4年前
User
1基于用户的协同过滤算法:基于用户的协同过滤算法是推荐系统中最古老的的算法,可以说是这个算法的诞生标志了推荐系统的诞生。该算法在1992年被提出,并应用于邮件过滤系统,1994年被GroupLens用于新闻过滤。在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的而用户A没有接触过的物品推
Stella981
•
4年前
LVS调度算法
内核中的连接调度算法IPVS在内核中的负载均衡调度是以连接为粒度的。在HTTP协议(非持久中),每个对象从WEB服务器上获取都需要建立一个TCP连接,同一用户的不同请求会被调度到不同服务器上,所以这种细粒度的调度在一定程度上可以避免单个用户访问的突发性引起服务器间的负载不平衡。在内核中的连接调度算法上,IPVS已实现了以下八种调
Stella981
•
4年前
Lua 排序算法
冒泡排序(BubbleSort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。算法步骤1.有一个长度为n
1
•••
7
8
9
•••
100