推荐
专栏
教程
课程
飞鹅
本次共找到5138条
sqlserver存储过程
相关的信息
Python进阶者
•
3年前
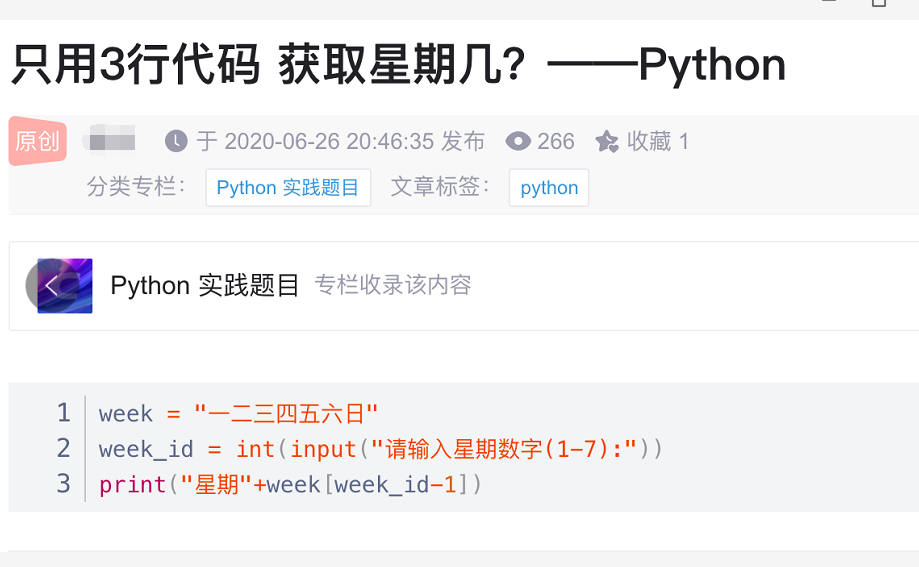
只用3行Python代码,获取星期几?
大家好,我是皮皮。一、前言前几天在Python最强王者交流群分享了一个只用3行Python代码,获取星期几的问题,这里拿出来给大家分享下,一起学习下。看到这个代码,我当时的第一反应是,这个人基础学的还是可以的,input用到位了。对于初学者来说,能写成这样,也是不错的了,起码功能确实是实现了,虽然说起来确实有点说不上来的味道,应缺斯汀。二、解决过程有一说
Python进阶者
•
3年前
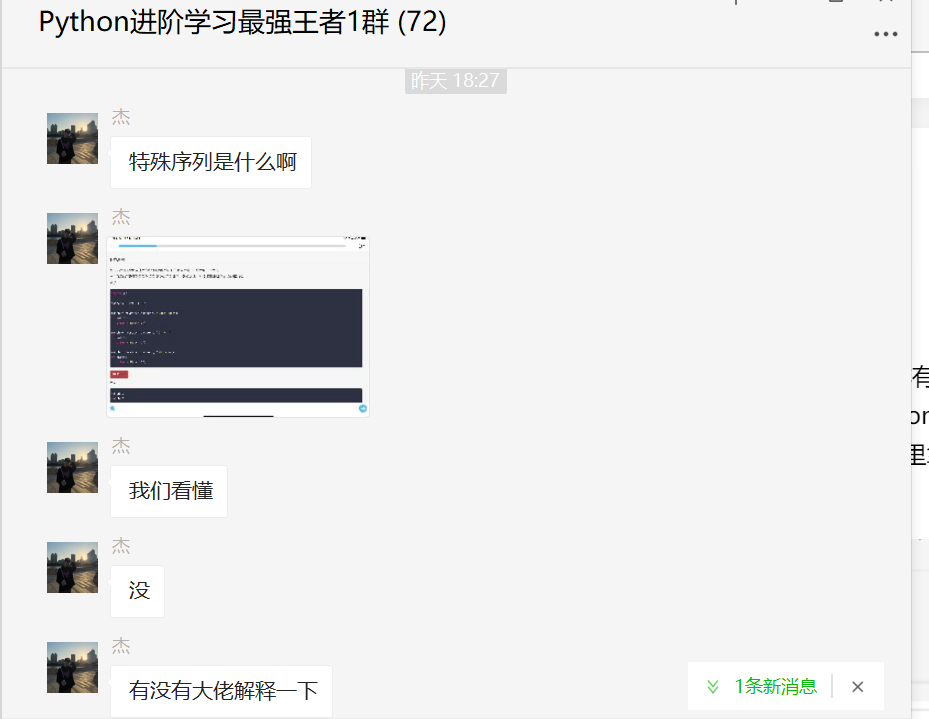
分享一场Python正则表达式中的特殊序列问答交流
大家好,我是我是皮皮。一、前言前几天在Python最强王者交流群有个叫【杰】的粉丝问了一个关于Python正则表达式的问题,讨论十分火热,这里拿出来给大家分享下,一起学习。下图是原始题目:下面是给出的答案,乍看有点难懂,不过有正则狂魔【小王】大佬在,问题不大。二、解决过程这个这里给出【小王】大佬的解答,一起来看看吧,下面是他给的一个示例代码。import
Wesley13
•
4年前
SSH概述与配置文件说明
一、什么是SSH?简单说,SSH是一种网络协议,用于计算机之间的加密登录。在出现SSH之前,系统管理员需要登入远程服务器执行系统管理任务时,都是用telnet来实现的,telnet协议采用明文密码传送,在传送过程中对数据也不加密,很容易被不怀好意的人在网络上监听到密码。如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机,我们就可
李志宽
•
3年前
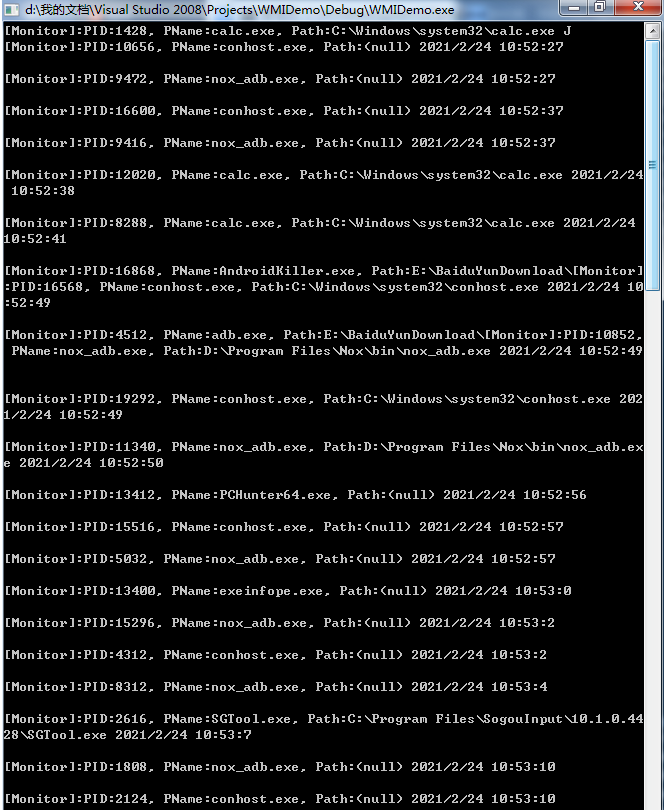
黑客是怎样监控你所有打开EXE程序的?
技术应用背景:目前已知在杀毒厂商以及游戏厂商的安全对抗过程中,常常需要准确的监控收集并进行检测用户创建打开的EXE应用程序是否是安全的。同时也可以将此技术应用于其他应用的安全对抗方案中。那么如何去准确的监控和收集用户每次点击打开的EXE应用程序信息呢?接下来我就进行还原实现下如何准确的监控并收集用户每次点击打开EXE应用程序技术。效果展示:下图展示的是开启
待兔
•
5年前
Golang泛型编程初体验
序言众所周知,Golang中不支持类似C/Java中的标记式泛型,所以对于常用算法,比如冒泡排序算法,有些同学容易写出逻辑上重复的代码,即整型是第一套代码,字符串型是第二套代码,用户自定义类型是第三套代码。重复是万恶之源,我们当然不能容忍,所以要消除重复,使得代码保持在最佳的状态。本文通过一个实际使用的简单算法的演进过程,初次体验了Golan
Wesley13
•
4年前
JS实现在线生成带logo的二维码
jquery.qrcode.js是一个能够在客户端生成矩阵二维码QRCode的jquery插件,使用它可以很方便的在页面上生成二维条码。此插件是能够独立使用的,体积也比较小,使用gzip压缩后才不到4kb。因为它是直接在客户端生成的条码,所以不会有图片下载的过程,能够实现快速生成。它是基于一个多语言的类库封装的,也不依赖于其他额外的服务。
Stella981
•
4年前
2020年csdn盘点
十年前就注册了csdn账号,之后一直没有写过博客,都是看别人的博客,等到2015年左右发表了第一篇自己的博客,直到2016年底觉着做技术的就需要记录自己的博客,不仅是自己学习的过程,说不定还可以帮助别人,于是坚持写了差不多四年,平均每年100篇,如今产量已经达到600篇,很多都是很浅显的内容,我刚开始写的时候,一个同事还很瞧不起这种没有技术含量的博客
Easter79
•
4年前
TOP100summit:【分享实录
王洋:猫眼电影商品业务线技术负责人、技术专家。主导了猫眼商品供应链和交易体系从0到1的建设,并在猫眼与美团拆分、与点评电影业务融合过程中,从技术层面保障了商品业务的平稳切换,同时也是美团点评《领域驱动设计》课程的讲师。在加入猫眼电影之前,曾就职于蚂蚁金服,参与了阿里网商银行从0到1的建设,以及支付宝钱包、花呗等产品的研发。导读:互联网电影行业在2016年
Stella981
•
4年前
Guava库学习:学习Guava EventBus(一)EventBus
在软件开发过程中,对象信息的分享以及相互直接的协作是必须的,困难在于确保对象之间的沟通是有效完成的,而不是拥有成本高度耦合的组件。当对象对其他组件的责任有太多的细节时,它被认为是高度耦合的。当一个应用程序有高度的耦合,维护将变得非常具有挑战,任何变化都将带来涟漪效应。为了解决这一类的软件设计问题,我们就需要基于事件的编程。本篇,我们就来学习Guava
Wesley13
•
4年前
Java多线程导致的的一个事物性问题
业务场景我们现在有一个类似于文件上传的功能,各个子站点接受业务,业务上传文件,各个子站点的文件需要提交到总站点保存,文件是按批次提交到总站点的,也就是说,一个批次下面约有几百个文件。 考虑到白天提交这么多文件会影响到子站点其他系统带宽,我们将分站点的文件提交到总站点这个操作过程独立出来,放到晚上来做,具体时间是晚上7:00到早上7:00。
1
•••
488
489
490
•••
514