大家好,我是我是皮皮。
一、前言
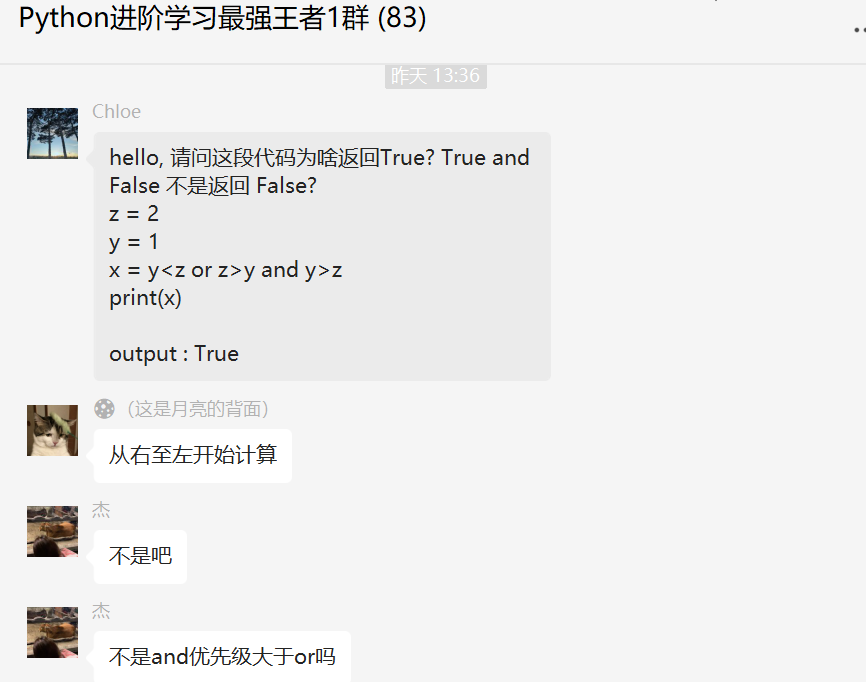
前几天在Python最强王者交流群有个叫【杰】的粉丝问了一个关于Python正则表达式的问题,讨论十分火热,这里拿出来给大家分享下,一起学习。
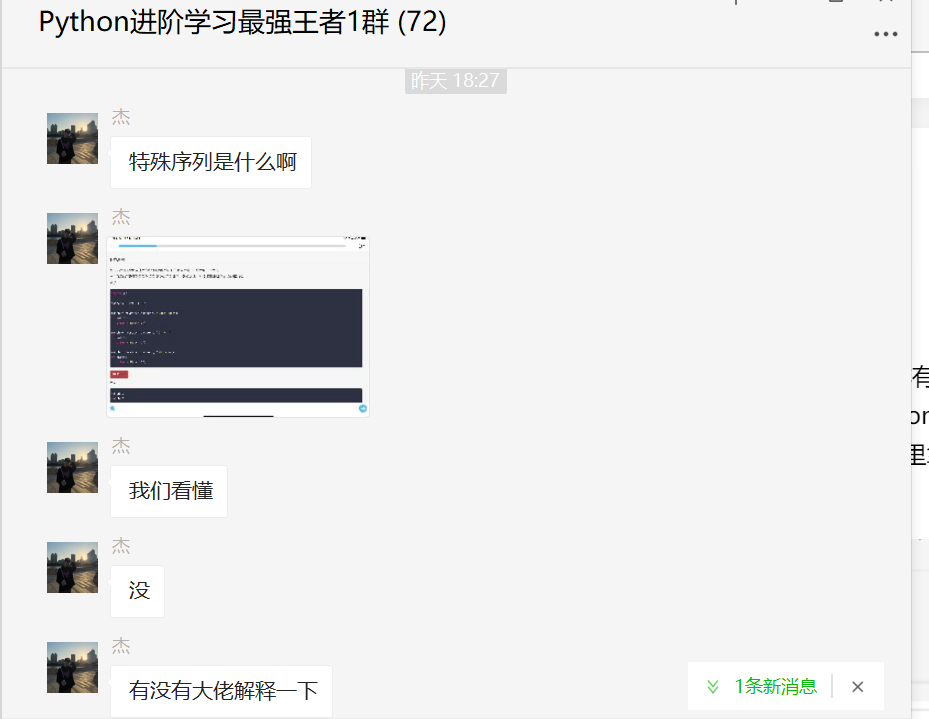
下图是原始题目:
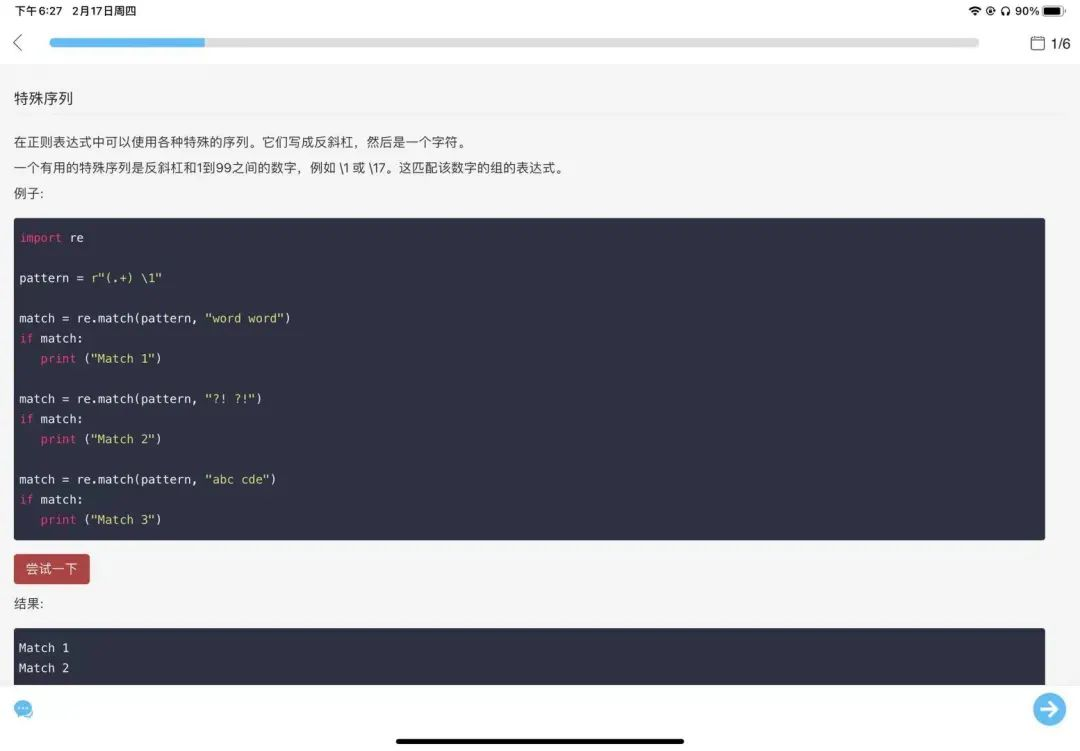
下面是给出的答案,乍看有点难懂,不过有正则狂魔【小王】大佬在,问题不大。
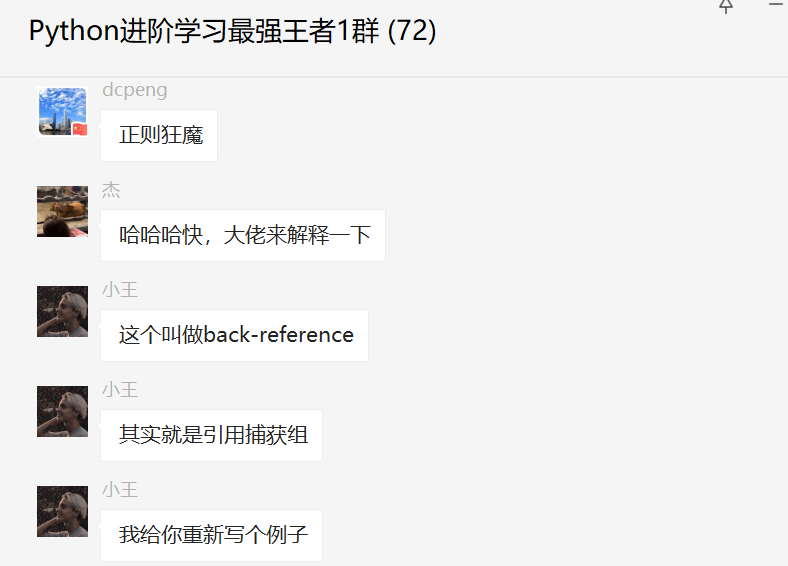
二、解决过程
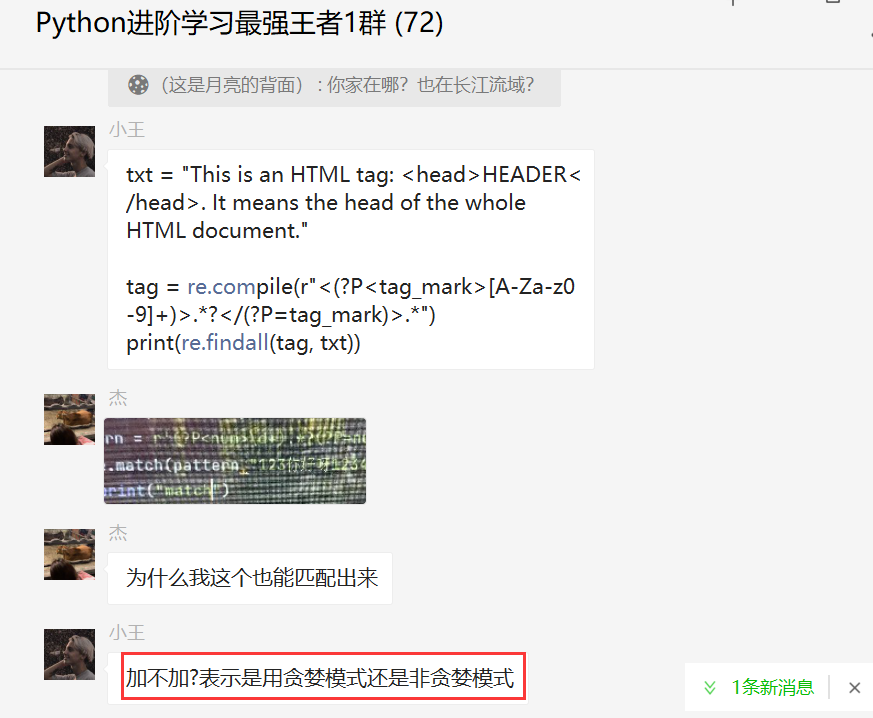
这个这里给出【小王】大佬的解答,一起来看看吧,下面是他给的一个示例代码。
import re
# 命名分组对应命名引用
pattern = re.compile(r"(?P<num>\d+).*?(?P=num)")
txt = "123你好呀123"
print(re.findall(pattern, txt))
# 匿名分组对应匿名引用
pattern = re.compile(r"(\d+).*?\1")
txt = "123你好呀123"
print(re.findall(pattern, txt))
# 命名分组对应匿名引用
pattern = re.compile(r"(\d+).*?\1")
txt = "123你好呀123"
print(re.findall(pattern, txt))
输出结果如下图所示:
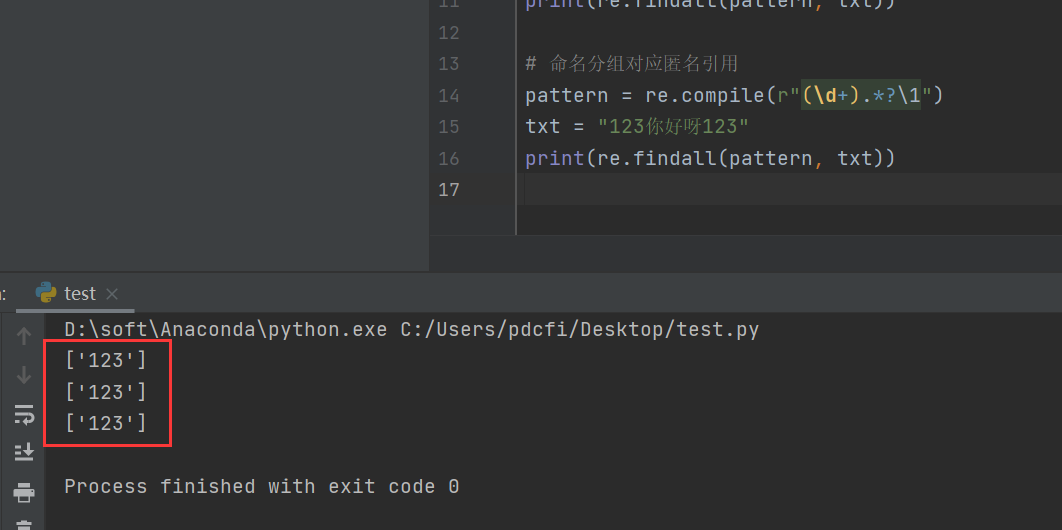
关于输出的解析如下:
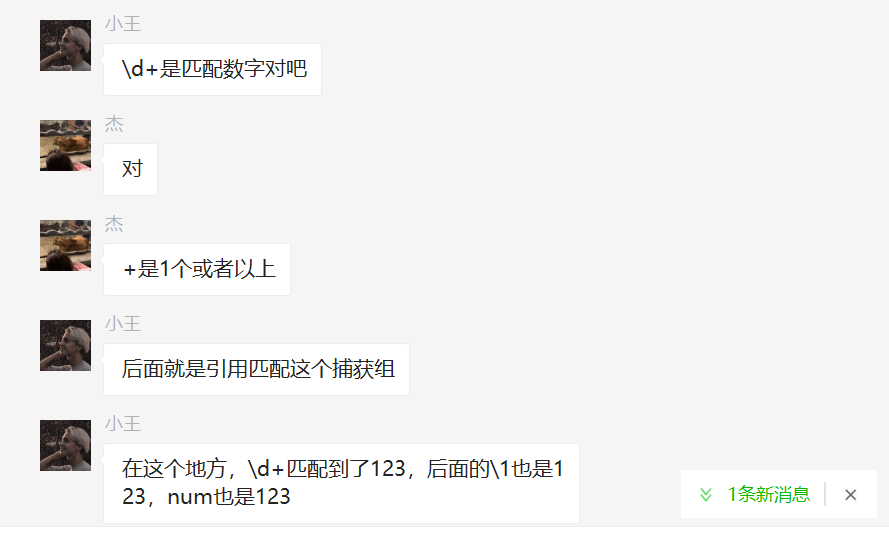
不过这么说还是不太好理解,这里【小王】大佬又给出了另外一个简单的示例,代码如下:
txt = "测试文本123python 测试文本python~"
pattern = re.compile(r"([一-龟]+)(\d+)(\w+)(\s+)(\1)(\3).*")
print(re.findall(pattern, txt))
输出结果如下图所示:
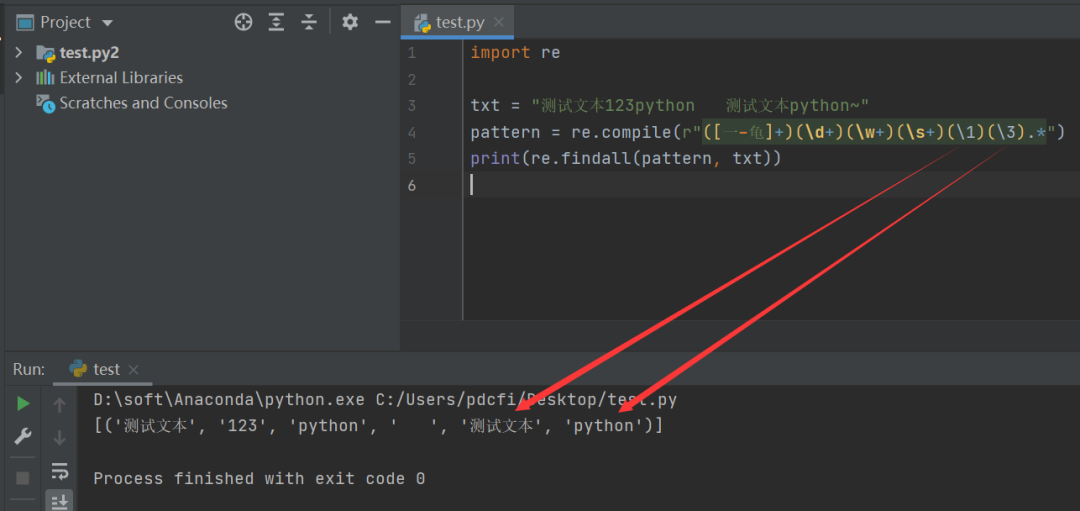
这下就清晰多了!
三、总结
大家好,我是皮皮。这篇文章基于粉丝提问,针对Python正则表达式中的特殊序列问题,给出了具体说明和演示,顺利的帮助粉丝解决了问题。
最后感谢粉丝【杰】提问,感谢【小王】、【(这是月亮的背面)】、【dcpeng】、【wangning】、【Chloé P.】等大佬们参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。