推荐
专栏
教程
课程
飞鹅
本次共找到3699条
python算法
相关的信息
Irene181
•
4年前
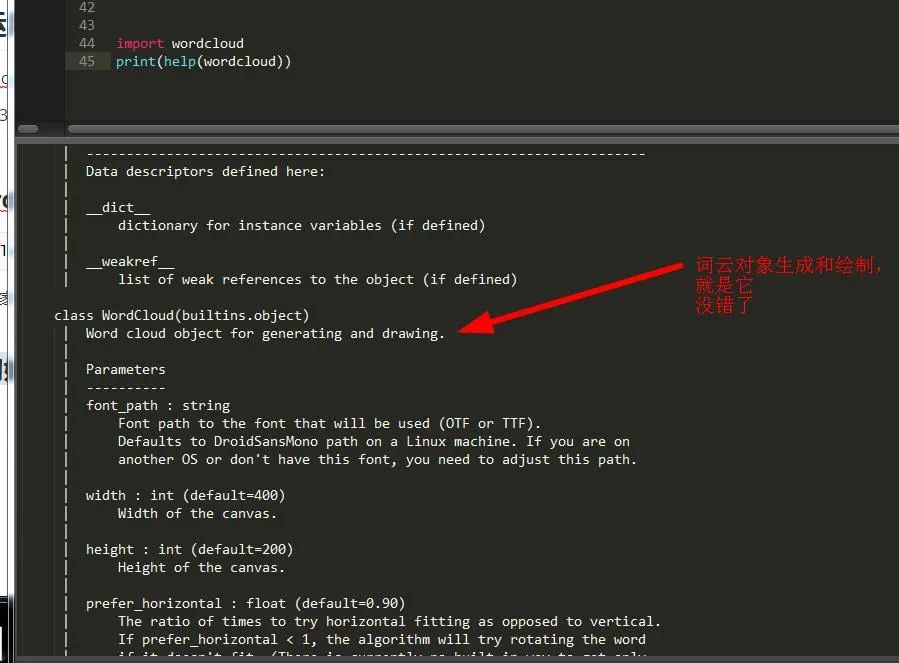
手把手教你使用Python打造绚丽的词云图
前言大家好,我是黄伟。词云,相信大家对这个概念比较陌生,它其实就是指的是对某一段文本中出现频率最高的关键词进行特殊描绘,过滤到太多没用的字眼,以此达到视觉上的突出,让人一看就知道这篇文章讲的什么。一、词云的运用设计到的模块:wordcloud编辑器:sublimetext3编译器:Python3.61.下载安装wordcloud模块pipins
Karen110
•
4年前
超全整理|Python 操作 Excel 库 xlwings 常用操作详解!
大家好,我是早起。在之前的文章中我们曾详细的讲解了如何使用openpyxl操作Excel,其实在Python中还有其他可以直接操作Excel文件的库,如xlwings、xlrd、xlwt等等,本文就将讲解另一个优秀的库xlwings开头还是想说一下,各个库之间没有明确的好坏之分,每个库都有其适合的应用场景,并且xlwings和openpyxl
Aidan075
•
4年前
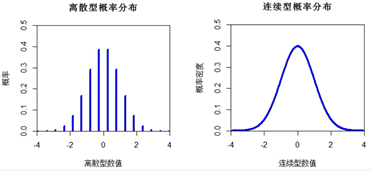
用python重温统计学基础:离散型概率分布
简单介绍数据的分布形态描述中的离散型概率分布利用python中的matplotlib来模拟几种分布的图形在上一篇中提到数据分析的对象主要是结构化化数据,而所有的结构化数据可以从三个维度进行描述,即数据的集中趋势描述,数据的离散程度描述和数据的分布形态描述,并对前两个维度进行了介绍。本篇主要是对数据的分布形态描述中的离散型概率分布进行介绍。
Stella981
•
4年前
Mac python3 环境下 完善pdf转jpg脚本
由于样本图片数据都是保存在pdf里,想拿到样本必须先把图片从pdf中提取出来,算是数据清洗中的一点小小的积累吧。这里不得不吐槽一下公司存储图片的机制,业务员把jpg格式的照片放到word里,然后用工具把word保存为pdf,最后上传到公司服务器里,这简介反人类,不但丢失了图片头文件信息,还造成后期数据转换的大量时间资源的浪费,可能pdf格式会小一
Stella981
•
4年前
Python的pillow库制作动态图,gif或webp
fromPILimportImagefilestreamsfiledirr'F:\CG\PC官方\黑兽_jpg'foriinrange(65,65101):filepathfiledir'\ECG_01_01_'chr(i)'.jpg'
Stella981
•
4年前
Pycharm+Django+Python+MySQL开发 后台管理数据库
Django框架十分简单易用,适合搭建个人博客网站。网上有很多教程,大多是关于命令行操作Django,这里分享一些用最新工具进行Django开发过程,主要是PyCharm太强大,不用有点可惜。第一次写技术开发类的博文,可能抓不到重点,详略也可能失衡,感谢支持。环境&工具:Windowsserver2012 ,PyCharm2016.2.1
Stella981
•
4年前
Python基础练习(一)中国大学定向排名爬取
说好的要从练习中学习爬虫的基础操作,所以就先从容易爬取的静态网页开始吧!今天要爬取的是最好大学网上的2018年中国大学排名。我个人认为这个是刚接触爬虫时用来练习的一个很不错的网页了。在说这个练习之前,给新着手学习爬虫的同学提供一个中国MOOC上北京理工大学嵩天老师的视频,Python网络爬虫与信息提取(https://www.oschina.n
Stella981
•
4年前
Python在VSCode环境抓取TuShare数据存入MongoDB环境搭建
本文出自:https://www.cnblogs.com/2186009311CFF/p/11573094.html(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fwww.cnblogs.com%2F2186009311CFF%2Fp%2F11573094.html)总览
Wesley13
•
4年前
Python 单元测试:assertTrue 是真值_assertFalse 是假值
原文地址(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fclick.aliyun.com%2Fm%2F24494%2F)原文地址(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fclick.aliyun.com%2
Stella981
•
4年前
Selenium+Python自动化测试学习问题总结笔记
1.问题描述:不能导入自定义类错误内容:Thisinspectiondetectsnamesthatshouldresolvebutdon't.Duetodynamicdispatchandducktyping,thisispossibleinalimitedbutusefulnumberofcase
1
•••
301
302
303
•••
370