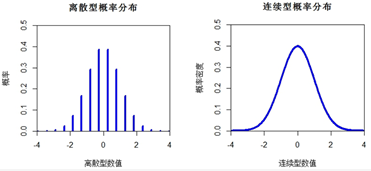
简单介绍数据的分布形态描述中的离散型概率分布
利用python中的matplotlib来模拟几种分布的图形
在上一篇描述性统计中提到数据分析的对象主要是结构化化数据,而所有的结构化数据可以从三个维度进行描述,即数据的集中趋势描述,数据的离散程度描述和数据的分布形态描述,并对前两个维度进行了介绍。
本篇主要是对数据的分布形态描述中的离散型概率分布进行介绍。
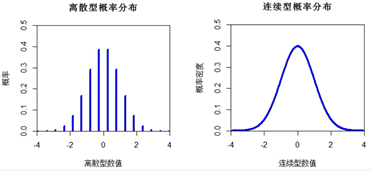
离散型概率分布是一条条垂直于X轴的垂线(或矩形柱),每条垂线与X轴的交点代表事件可能发生的结果,垂线上端点对应的Y轴表示该结果发生的概率(区别于概率密度)。
常见的离散型概率分布有二项分布、伯努利分布和泊松分布等。
二项分布
二项分布是由伯努利提出的概念,指的是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。
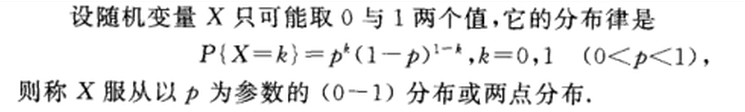
下面用python中的matplotlib模拟二项分布:
# 利用plt模拟二项分布
n , p =10 ,0.5
sample = np.random.binomial(n, p, size=10000) # 产生10000个符合二项分布的随机数
bins = np.arange(n + 2)
plt.hist(sample, bins=bins, align='left',density=True, rwidth=0.5) # 绘制直方图
# 设置标题和坐标
plt.title('Binomial FMF with n={},p={}'.format(n, p))
plt.xlabel('number of successes')
plt.ylabel('probability')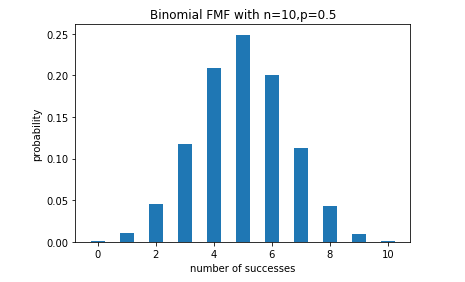
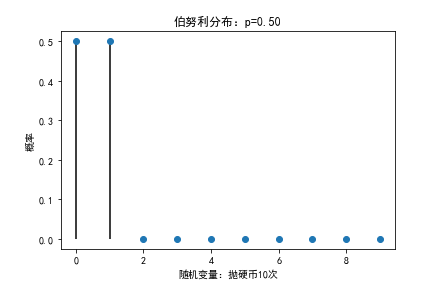
伯努利分布
伯努利分布亦称“零一分布”、“两点分布”。称随机变量X有伯努利分布, 参数为p(0<p<1),如果它分别以概率p和1-p取1和0为值。EX= p,DX=p(1-p)。伯努利试验成功的次数服从伯努利分布,参数p是试验成功的概率。伯努利分布是一个离散型机率分布,是N=1时二项分布的特殊情况
伯努利分布与二项分布之间的关系:
• 伯努利分布是具有单项试验的二项式分布的特殊情况。
• 伯努利分布和二项式分布只有两种可能的结果,即成功与失败。
• 伯努利分布和二项式分布都具有独立的轨迹。
下面用python中的matplotlib模拟二项分布:
# 利用plt模拟伯努利分布
#解决画图中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#定义随机变量
X = np.arange(10)
p = 0.5
#伯努利概率函数
pList = bernoulli.pmf(X,p)
#绘图,marker:点的形状,linestyle:线条的形状
plt.plot(X,pList,marker = 'o',linestyle = 'None' )
#vlines绘制树直线,参数的含义(x轴坐标轴,y轴最小值,y轴最大值)
plt.vlines(X,0,pList)
plt.xlabel("随机变量:抛硬币{}次".format(len(X)))
plt.ylabel("概率")
plt.title('伯努利分布:p={:.2f}' .format(p))
泊松分布
泊松分布的概率函数为: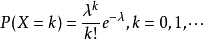
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数。泊松分布适合于描述单位时间内随机事件发生的次数。
泊松分布的期望和方差均为 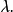
特征函数为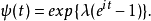
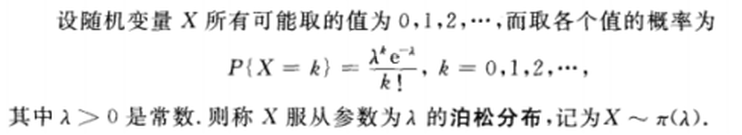
泊松分布与二项分布之间的关系:****
泊松分布在满足以下条件的情况下是二项式分布的极限情况:
• 试验次数无限大或n → ∞。
• 每个试验成功的概率是相同的,无限小的,或p → 0。
• np = λ,是有限的。
假设通过一定时间的观察,我们知道某个路口每小时平均有8辆车通过,这是一个典型的泊松分布实例,我们通过Python进行统计模拟来看看在统计图它具体是如何呈现的。
下面用python中的matplotlib模拟二项分布:
# 用plt模拟泊松分布
lamb = 8
sample = np.random.poisson(lamb, size=10000)
bins = np.arange(20)
plt.hist(sample, bins=bins, align='left',density=True, rwidth=0.5)
plt.title('Possion PMF (lambda=8)')
plt.xlabel('number of appear')
plt.ylabel('probability')
plt.show()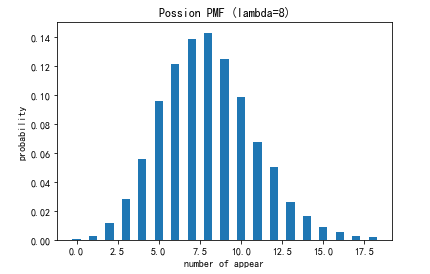
本文完。
朱小五,某互联网公司数据分析师,热衷于爬虫,数据分析,可视化,个人公众号《凹凸玩数据》
本文相关ipynb格式代码已上传github:
https://github.com/zpw1995/aotodata/tree/master/tongji/lisan

历史文章:
44万条数据揭秘:如何成为网易云音乐评论区的网红段子手?
破解大众点评的字体加密,这一篇就够了。
用Python爬取b站弹幕,看大家还会接受《爱情公寓5》吗?

本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/kRjEsvarsEALiQkUyIdpYw,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。