推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Aimerl0
•
4年前
Python网络爬虫与信息提取
title:Python网络爬虫与信息提取date:2020121001:00:23tags:Pythoncategories:学习笔记写在前面不知道写啥其实说实话TOC网络爬虫之规则安装requests库cmd命令行打开输入pip3installrequests,等待即可简单测试,爬一下bkjwpythonimportrequ
Stella981
•
4年前
32个Python爬虫项目让你一次吃到撑
整理了32个Python爬虫项目。整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心。所有链接指向GitHub,祝大家玩的愉快~O(∩\_∩)OWechatSogou\1\(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Flink.zhihu.com%2F%3
Stella981
•
4年前
Python_爬虫_案例汇总:
1.豆瓣采集!(https://oscimg.oschina.net/oscnet/29e918bf2ebced4da903f8ab789cd37ca35.jpg)!(https://oscimg.oschina.net/oscnet/83a646b5655e70dc379744e8ebfe145238d.jpg)1codin
Stella981
•
4年前
Python基础练习(一)中国大学定向排名爬取
说好的要从练习中学习爬虫的基础操作,所以就先从容易爬取的静态网页开始吧!今天要爬取的是最好大学网上的2018年中国大学排名。我个人认为这个是刚接触爬虫时用来练习的一个很不错的网页了。在说这个练习之前,给新着手学习爬虫的同学提供一个中国MOOC上北京理工大学嵩天老师的视频,Python网络爬虫与信息提取(https://www.oschina.n
Stella981
•
4年前
Python中的基础数据类型(String,Number)及其常用用法简析
点击上方“Python爬虫与数据挖掘”,进行关注回复“书籍”即可获赠Python从入门到进阶共10本电子书今日鸡汤寄意寒星荃不察,我以我血荐轩辕。Python中的基础数据类型前言哈喽,各位小伙伴们,相信大家和我一样,在开始接触Python这门语言的时候,会遇到很多困
小白学大数据
•
1年前
从爬取到分析:Faraday爬取Amazon音频后的数据处理
什么是Faraday?Faraday是一个简单、灵活的高级爬虫框架,支持多种编程语言。它提供了一套丰富的API,允许开发者快速构建复杂的爬虫应用。Faraday的主要特点包括:●模块化设计:易于扩展和自定义。●多语言支持:支持Python、Ruby、Nod
Python进阶者
•
1年前
怎么用xpath写drissionpage?或者用相对位置?
大家好,我是Python进阶者。一、前言前几天在Python最强王者交流群【黑科技·鼓包】问了一个Python网络爬虫处理的问题。问题如下:有没有大佬指点下怎么用xpath写drissionpage?或者用相对位置?我看了半天中文文档硬是写不出来。这是xp
小白学大数据
•
1年前
Python爬虫教程:Selenium可视化爬虫的快速入门
网络爬虫作为获取数据的一种手段,其重要性日益凸显。Python语言以其简洁明了的语法和强大的库支持,成为编写爬虫的首选语言之一。Selenium是一个用于Web应用程序测试的工具,它能够模拟用户在浏览器中的操作,非常适合用来开发可视化爬虫。本文将带你快速入
Python进阶者
•
3年前
盘点一个Python网络爬虫过程中中文乱码的问题
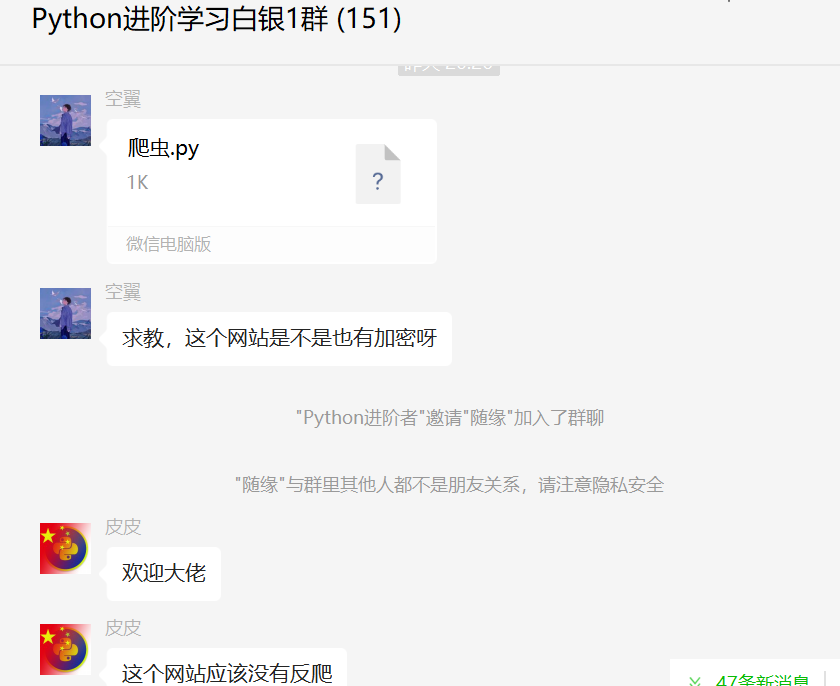
大家好,我是皮皮。一、前言前几天在Python白银交流群【空翼】问了一个Python网络爬虫中文乱码的问题,提问截图如下:原始代码如下:importrequestsimportparselurl'https://news.p2peye.com/article5147231.html'headers'AcceptLanguage':'zhCN,zh;q
Python进阶者
•
2年前
盘点一个Python网络爬虫问题
大家好,我是皮皮。一、前言前几天在Python最强王者群【刘桓鸣】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。他自己的代码如下:importrequestskeyinput("请输入关键字")resrequests.post(url"htt
1
•••
4
5
6
•••
294