推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
python知道
•
4年前
《Python3网络爬虫开发实战》
提取码:1028内容简介······本书介绍了如何利用Python3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、BeautifulSoup、XPath、pyquery、数据存储、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下如何实现数据爬取,后介绍了pyspider框架、S
Python进阶者
•
3年前
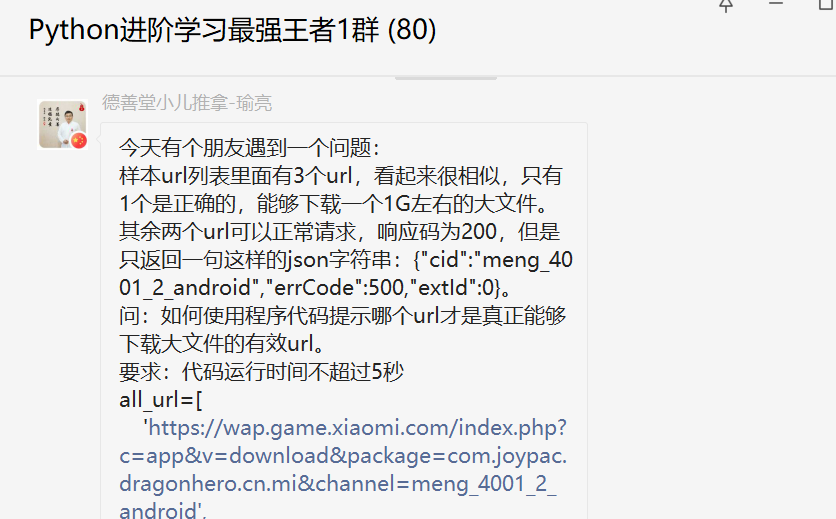
Python网络爬虫过程中,构建网络请求的时候,参数`stream=True`的使用
大家好,我是皮皮。一、前言前几天在Python最强王者交流群【德善堂小儿推拿瑜亮老师】分享了一个关于Python网络爬虫的问题,这里拿出来给大家分享下,一起学习。二、解决过程这里【PI】大佬提出了思路,的确可行。【皮皮】给了一份代码,取巧,这里就不展示了。后来【月神】给了一份可行的代码,如下所示:forurlinallurl:respr
Karen110
•
4年前
Python爬虫 | Selenium爬取当当畅销图书排行
01前言上篇文章我们爬取了,心情相当愉悦,今天这篇文章我们使用Selenium来爬取当当网的畅销图书排行。正所谓书中自有黄金屋,书中自有颜如玉,我们通过读书学习来提高自身的才华,自然能有荣华富贵,也自然少不了漂亮小姐姐。02准备工作在爬取数据前,我们需要安装Selenium库以及Chrome浏览器,并配置好Chro
Karen110
•
4年前
纯干货:手把手教你用Python做数据可视化(附代码)
前言Hi,大家好,又见面了,我是Python进阶者,废话不多说,直接开始肝吧,奥里给!爬虫管理效果图依赖包文件:requirements.txt文件的内容这里直接贴出来了:appdirs1.4.4APScheduler3.5.1attrs20.1.0Automat20.2.0beautifulsoup44.9.1certifi202
Stella981
•
4年前
Python数据可视化:折线图、柱状图、饼图代码
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。作者:godweiyang来源:算法码上来Python爬虫、数据分析、网站开发等案例教程视频免费在线观看https://space.bilibili.com/523606542!(https://oscimg.oschi
Stella981
•
4年前
Python网络爬虫与文本数据分析
!(https://oscimg.oschina.net/oscnet/713b3c2bfee647209be73d544df565cf.jpg)课程介绍在过去的两年间,Python一路高歌猛进,成功窜上“最火编程语言”的宝座。惊奇的是使用Python最多的人群其实不是程序员,而是数据科学家,尤其是社会科学家,涵盖的学科有经
Python进阶者
•
3年前
盘点一个使用playwright实现网络爬虫的实战案例
大家好,我是皮皮。一、前言前几天在Python白银交流群【空翼】问了一个Pyhton网络爬虫的问题,这里拿出来给大家分享下。二、实现过程【喜靓仔】提出用playwright实现,后来他自己给出了代码,如下图所示:代码如下:fromplaywright.sy
Python进阶者
•
2年前
xpath的一次性同时获取a标签和p标签的内容?(下篇)
大家好,我是皮皮。一、前言前几天在Python白银交流群【上海新年人】问了一个Python网络爬虫数据提取的问题,一起来看看吧。他的需求就是:xpath的一次性同时获取a标签和p标签的内容。上一篇文章中,大佬们已经给出了一个答案,可是数据获取下来后发现和网
小白学大数据
•
2个月前
拼多多数据抓取:Python 爬虫中的 JS 逆向基础案例分析
一、拼多多反爬虫机制与JS逆向的必要性拼多多的前端页面数据加载并非传统的服务端渲染,而是大量采用异步请求(AJAX)加载数据。这些异步请求的参数(如sign、token等)往往经过JavaScript加密处理,直接通过Python的requests库发送请
1
•••
13
14
15
•••
294