推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Irene181
•
4年前
浅谈Python两大爬虫库——urllib库和requests库区别
一、前言在使用Python爬虫时,需要模拟发起网络请求,主要用到的库有requests库和python内置的urllib库,一般建议使用requests,它是对urllib的再次封装。那它们两者有什么区别?下面通过案例详细的讲解,了解他们使用的主要区别。二、urllib库简介:urllib库的response对象是先创建http,request对象
Aidan075
•
5年前
2021最全Python入门学习路线
我将在这里带大家快速入门Python,本公众号会专注于Python爬虫、数据分析、数据可视化、办公自动化、Web开发等等然后接下来会给大家一些学习路线(思维导图),方便大家找到适合自己的学习方向。无论你打算做什么,只要是和Python相关的,这个学习路线绝对都是好用的。但我特别不希望有些朋友一上来就学习numpy、pandas、matplotlib相
CuterCorley
•
4年前
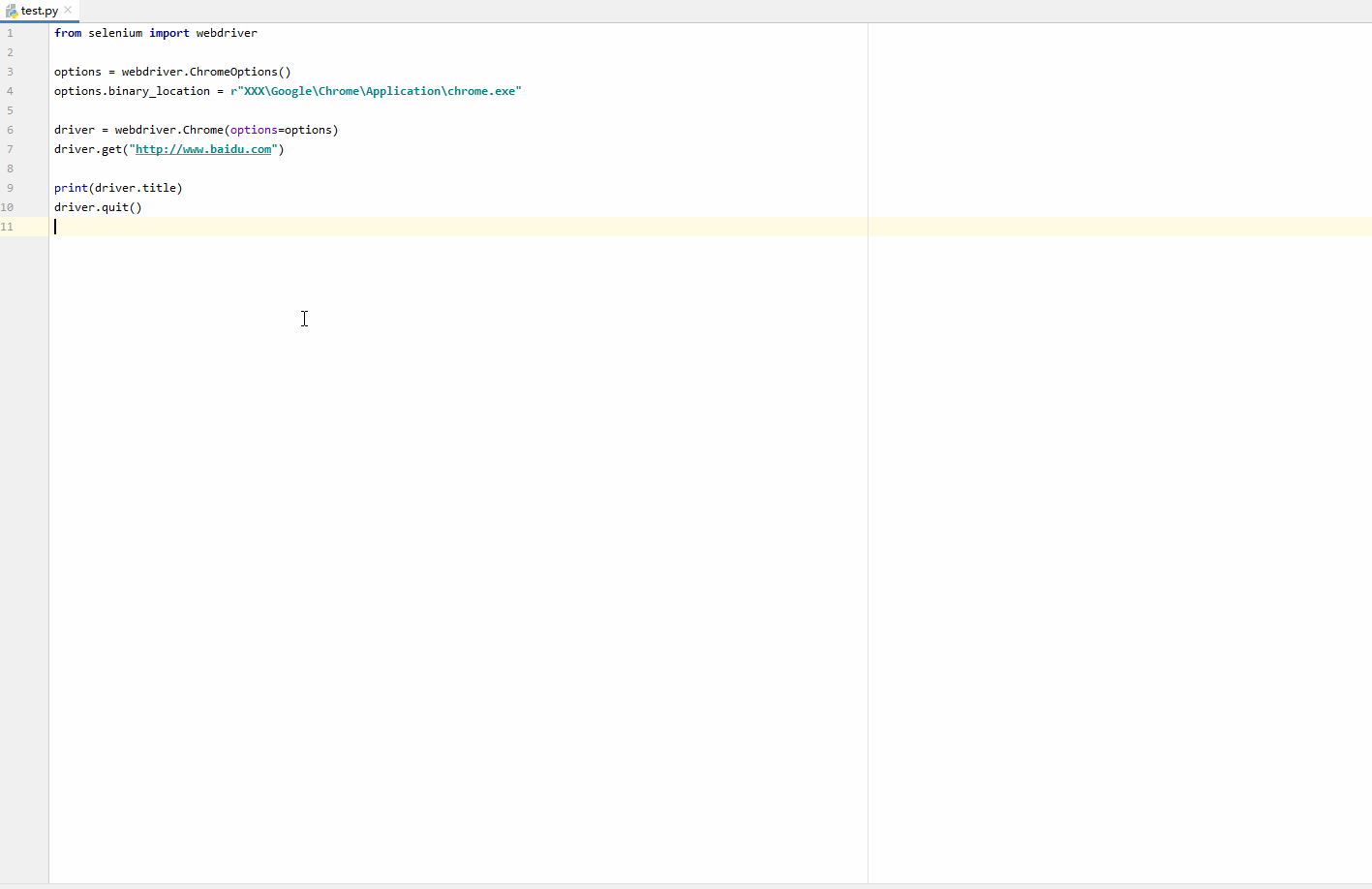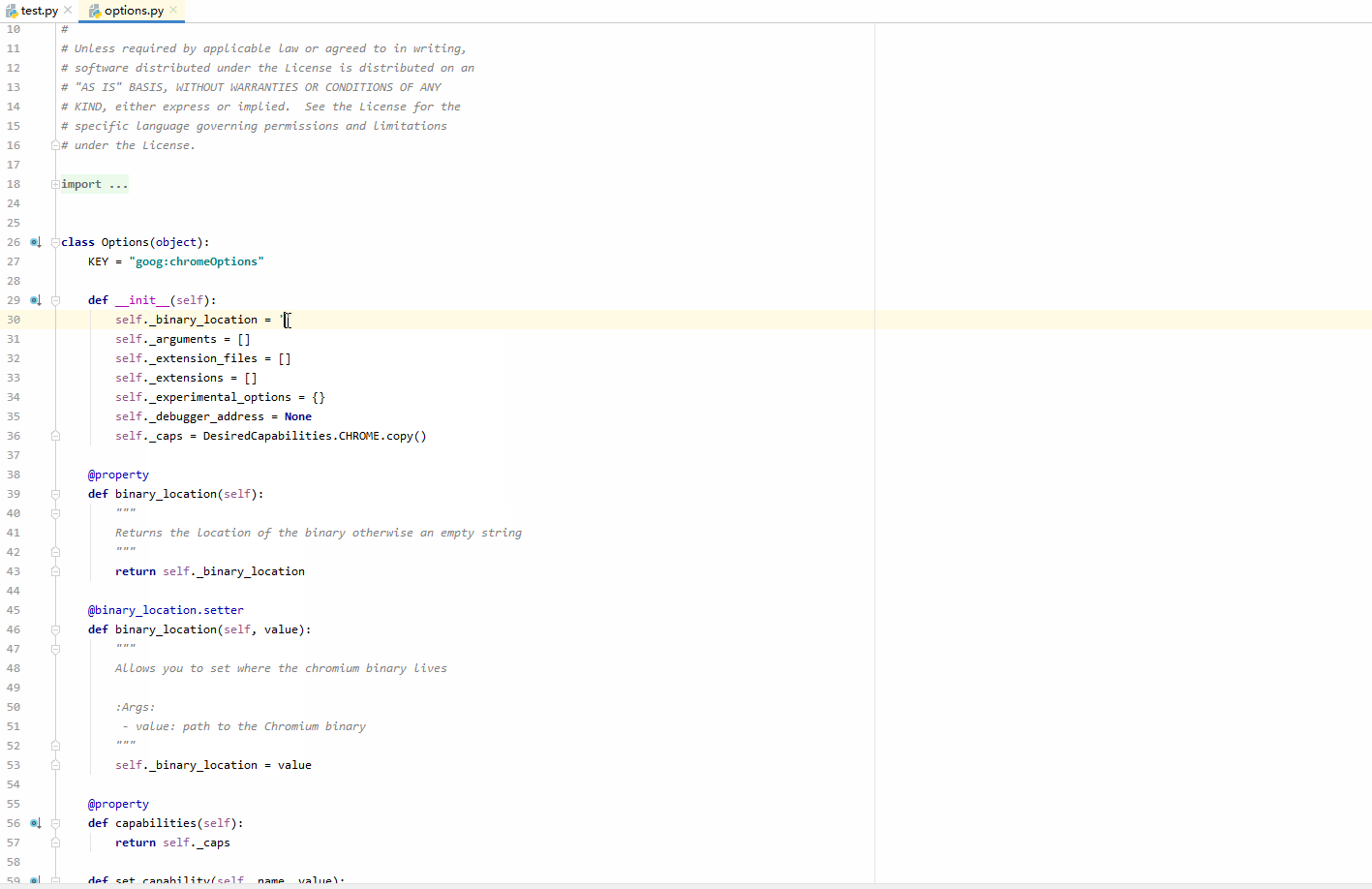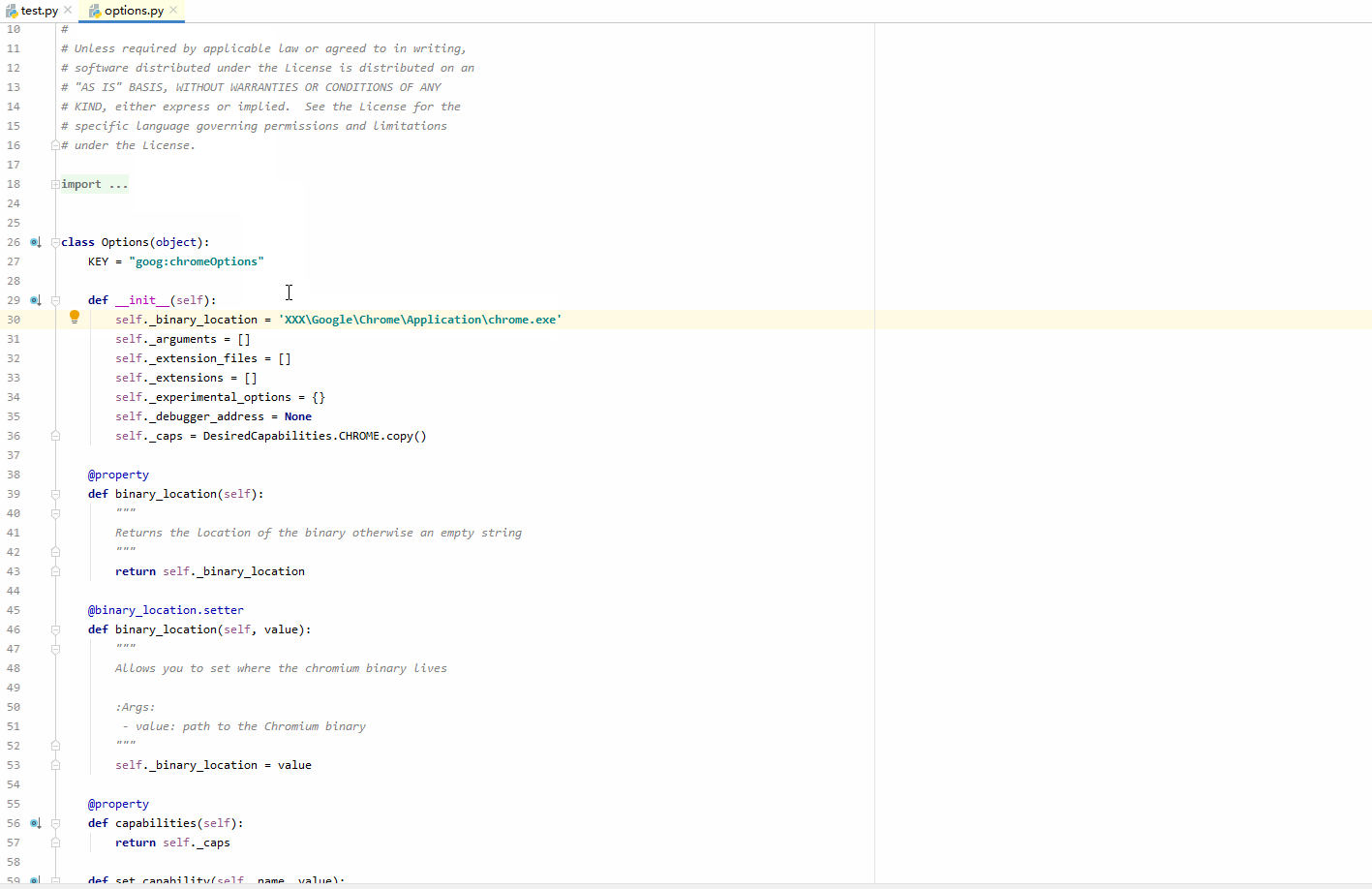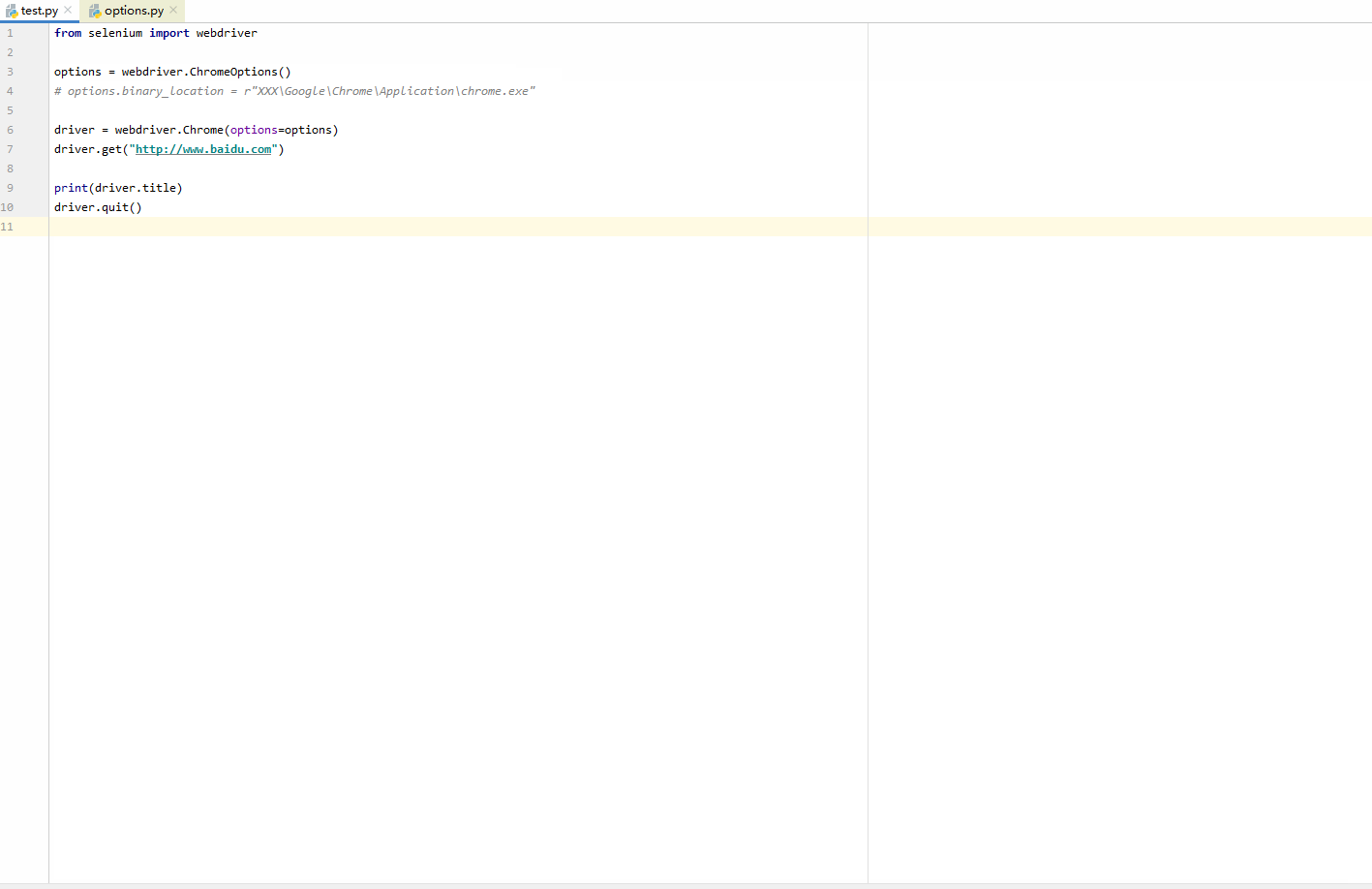
Python爬虫常见异常及解决办法
给大家介绍一门互联网行业认知课,带你一起深入认识互联网这个行业,为将来的就业铺好路。1.selenium.common.exceptions.WebDriverException:Message:unknownerror:cannotfindChromebinary在爬虫时经常会使用selenium实现自动化,来模拟Google访问目
Stella981
•
4年前
Python3爬虫(十八) Scrapy框架(二)
对Scrapy框架(一)的补充Infichu:http://www.cnblogs.com/Infichu/(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.cnblogs.com%2FInfichu%2F)Scrapy优点: 提供了内置的HTTP
Stella981
•
4年前
Python:黑板课爬虫闯关第四关
第四关地址:http://www.heibanke.com/lesson/crawler\_ex03/!(https://img2018.cnblogs.com/blog/753333/201810/75333320181029092812424811751371.png)一开始看到的时候有点蒙,不知道啥意思,说密码需要找出来但也没说怎么找啊
Python进阶者
•
1年前
为啥chrome查看到网页,只有5000多行,应该有1万多行才对
大家好,我是皮皮。一、前言前几天在Python白银交流群【磐奚鸟】问了一个Python网络爬虫处理的问题,这里拿出来给大家分享下。二、实现过程这里【惜君】给了一个指导,可能网站有限制数据量。这里【瑜亮老师】发现了问题所在,如下图所示:数据方面确实存在,顺利
Python进阶者
•
3年前
盘点一个Python网络爬虫过程中中文乱码的问题
大家好,我是皮皮。一、前言前几天在Python黄金交流群有个叫【Mt.Everest】的粉丝问了一个关于Python网络爬虫过程中中文乱码的问题,这里拿出来给大家分享下,一起学习。二、解决过程这个问题其实很早之前,我就写过相关文章,而且屡试不爽。【Python进阶者】解答这里给出了两个思路,照着这个思路去的话,问题不大。事实上并不巧,还是翻车了。【黑
Python进阶者
•
2年前
推荐一个下载股票相关数据的库——tuhsare
大家好,我是皮皮。一、前言这个事情还得从前几天在Python白银群【厚德载物】问了一个Python股票网络爬虫的问题说起,因为这个股票数据抓取的问题,引发了大家激烈的探讨,以致于后来大佬们纷纷参与进来。图片二、实现过程这里【袁学东】分享了一个tushare
Python进阶者
•
2年前
提供一个网站的相关截图,麻烦提供一个思路如何爬取网站相关数据
大家好,我是皮皮。一、前言前几天在Python钻石交流群【空】问了一个Python网络爬虫的问题,一起来看看吧。给大家提供一个网站的相关截图,麻烦你们提供一个思路如何爬取网站相关数据,下图这里是数据区。页面数据存储在这里的json里。二、实现过程常规来说,
Python进阶者
•
2年前
页面的json数据浏览器无法访问,还有什么别的办法获取数据?
大家好,我是皮皮。一、前言前几天在Python钻石流群【空】问了一个Python网络爬虫的问题,一起来看看吧。问题描述:请教一个问题,页面的json数据浏览器无法访问,还有什么别的办法获取数据图片如下:这个问题看上去有点怪怪的。二、实现过程看上去代码倒是很
1
•••
11
12
13
•••
294