推荐
专栏
教程
课程
飞鹅
本次共找到2834条
python正则表达式
相关的信息
Irene181
•
4年前
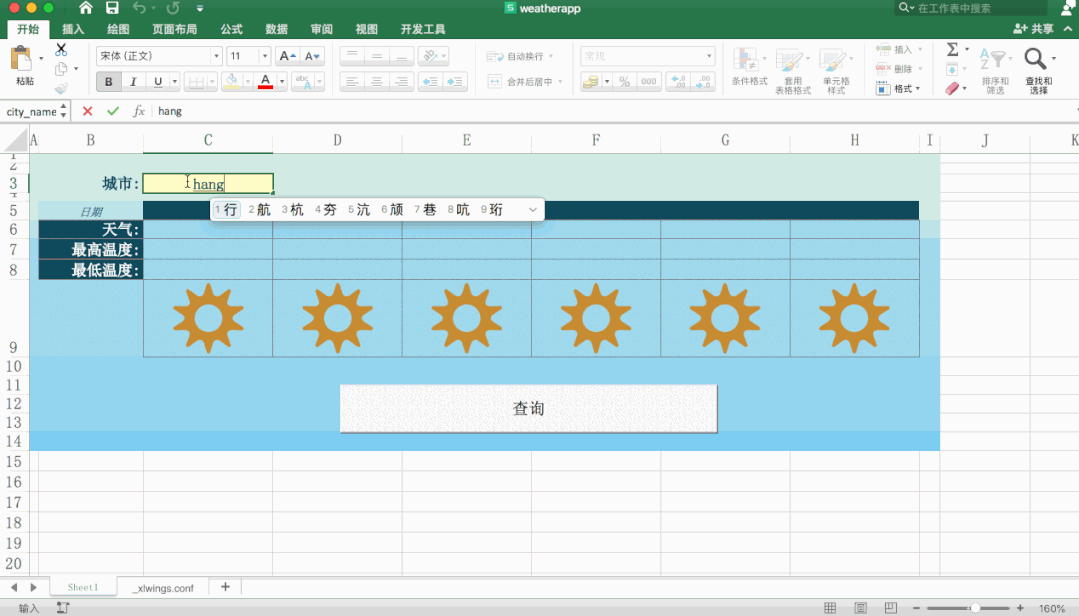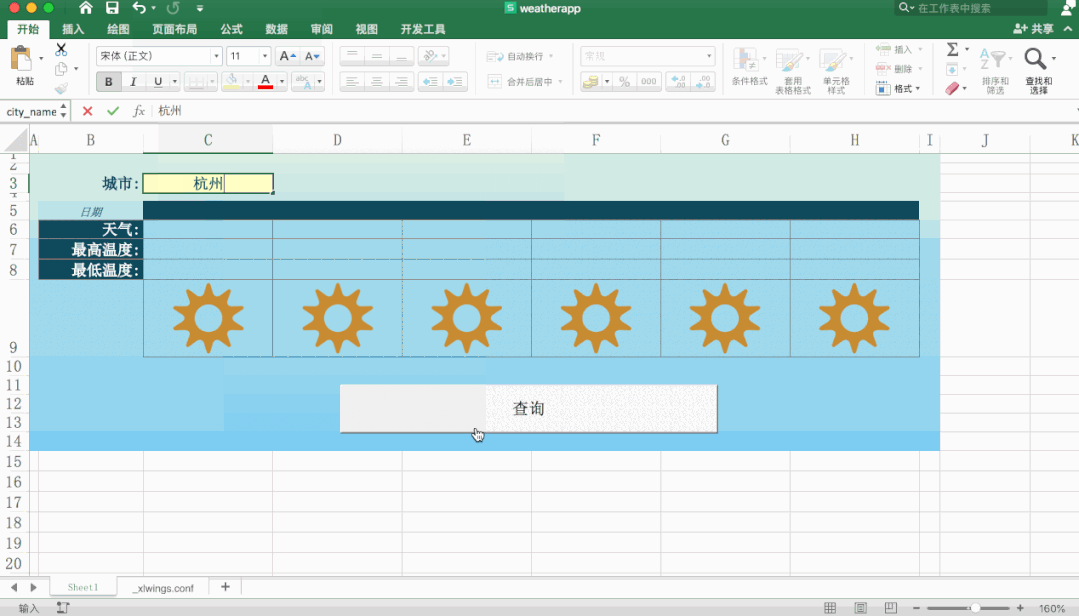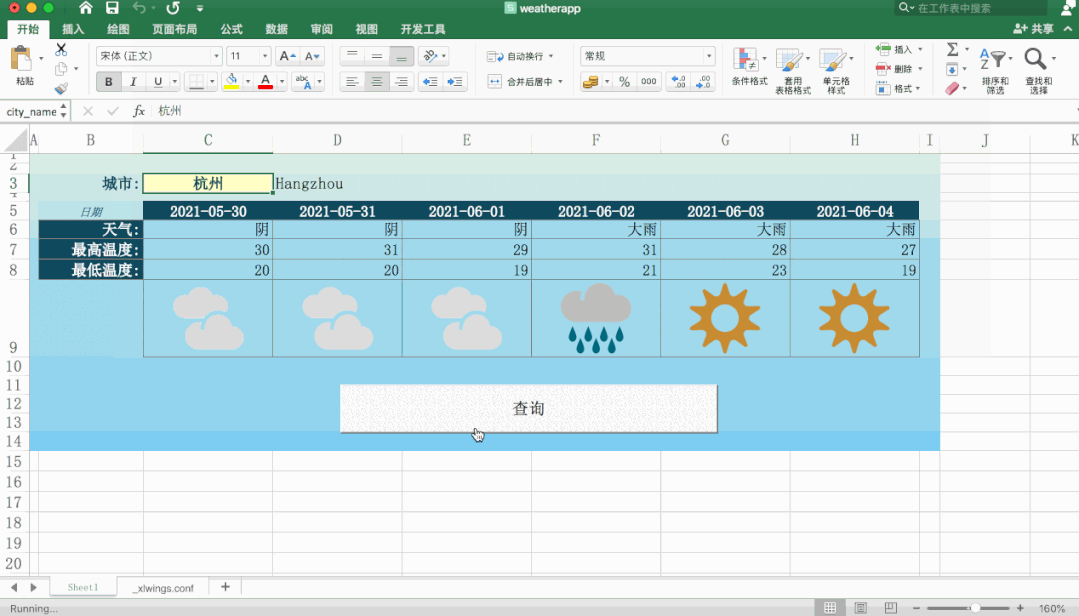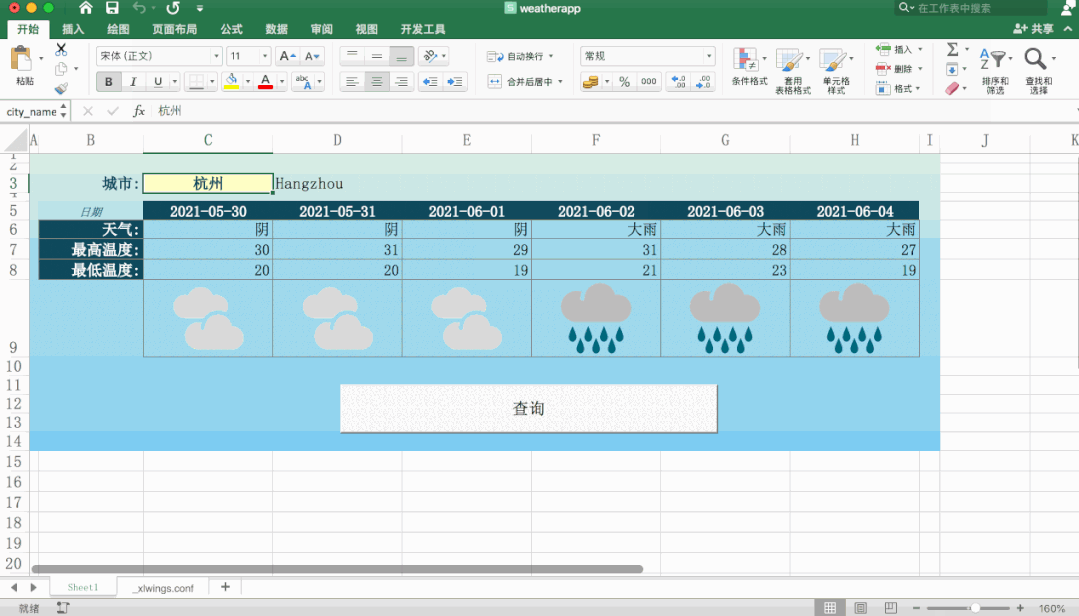
太强了,用Python+Excel制作天气预报表!
大家好,我是小F~今天给大家介绍一个PythonExcel的实战项目,非常有趣。主要使用xlwings和requests这两个Python库,以及Office的Excel。xlwings处理表格,requests则是请求数据。先从Excel中获取城市信息,然后请求接口,获取到天气信息,再返回给Excel。具体操作可以看下图~
Karen110
•
4年前
盘点Python列表生成式的三种方法
一、前言列表生成式即ListComprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。二、案例分析三种方法要生成list\1,2,3,4,5,6,7,8,9,10\可以用list(range(1,11))。print(list(range(1,11)))如果要生成\1x1,2x2
Stella981
•
4年前
Docker学习8
前言相信不少小伙伴之前在用docker运行jenkins容器构建的时候,发现没有python3环境遇到了不少麻烦,导致无法运行测试脚本,但不要紧,安装就好了。接下来我们说用docker运行jenkins 构建自动化测试脚本。一、jenkins新建项目1、createnewjobs:输入项目名称后,选择自由风格
Wesley13
•
4年前
MySQL DBA的工作日常
导读作者:田帅萌(邮箱:tplinux@163.com,欢迎交流)知数堂MySQLDBA班第9期优秀学员,Python运维开发班第5期学员,现任职知数堂助教又到了一年换坑最频繁的季节,很多童鞋在跑路(当然不是删库跑路!(https://oscimg.oschina.net/oscnet/64201376c910468
Stella981
•
4年前
Graphviz install the Windows for Scyther
1、在Pycharm中使用Scyther工具的时候需要导入graphviz 直接在Interpreter上安装的售后会报错,如果在IDE上无法支架安装的库可以试图在控制台上安装,控制台上无法安装的库直接下载后复制到对应python的库文件中加载。!(https://img2018.cnblogs.com/blog/1276904
各大电商API接口——>19970108118
•
6个月前
反向海淘跨境代购”业务的平台或系统,并无缝对接淘宝/1688的官方API数据接口
反向海淘跨境代购”业务的平台或系统,并无缝对接淘宝/1688的官方API数据接口
摘星星的猫
•
1年前
保护关键数据:企业利用HTTP代理进行高级加密的方法
在数字化和互联网技术迅猛发展的当代,企业面对的网络安全威胁也日益严峻。本文将探讨如何通过利用HTTP代理加密技术来加强企业的网络防御,并提高其数据保护能力。一、应对内部和外部网络安全挑战虽然传统的防火墙系统为企业提供了基本的数据流监控和管理,它们依旧无法完
敏捷开发
•
1年前
关于开源软件的七大错误认知(下)
关于开源软件的七大错误认知系列。
各大电商API接口——>19970108118
•
6个月前
利用京东商品详情 ID(即 SKU ID)获取商品详细信息
利用京东商品详情ID(即SKUID)获取商品详细信息,可通过京东开放平台官方API或非官方接口(逆向解析)实现。以下是两种方式的示例展示,包含代码实现与数据解析
各大电商API接口——>19970108118
•
6个月前
micro关键字搜索全覆盖商品,通过API接口提供实时数据
micro关键字搜索全覆盖商品,通过API接口提供实时数据
1
•••
194
195
196
•••
284