推荐
专栏
教程
课程
飞鹅
本次共找到10000条
python数据挖掘
相关的信息
Irene181
•
4年前
小伙Python爬虫并自制新闻网站,太好玩了
大家好,我又来了,我是银牌厨师豆腐!我们总是在爬啊爬,爬到了数据难道只是为了做一个词云吗?当然不!这次我就利用flask为大家呈现一道小菜。Flask是python中一个轻量级web框架,相对于其他web框架来说简单,适合小白练手。使用Flask爬虫,教大家如何实时展示自己爬下来的数据到网页上。先给大家展示一下这个丑丑的网页↓(给个面子,别笑)演示三
Irene181
•
4年前
一篇文章带你弄懂Python基础之进制和数据类型
大家好,我是Go进阶者,今天给大家分享一些Python基础(进制和数据类型),一起来看看吧一、进制1、什么是进制?进制也就是进位计数制,是人为定义的带进位的计数方法(有不带进位的计数方法,比如原始的结绳计数法,唱票时常用的“正”字计数法,以及类似的tallymark计数)。对于任何一种进制X进制,就表示每一位置上的数运算时都是逢X进一位。十进制是逢十进
Aidan075
•
4年前
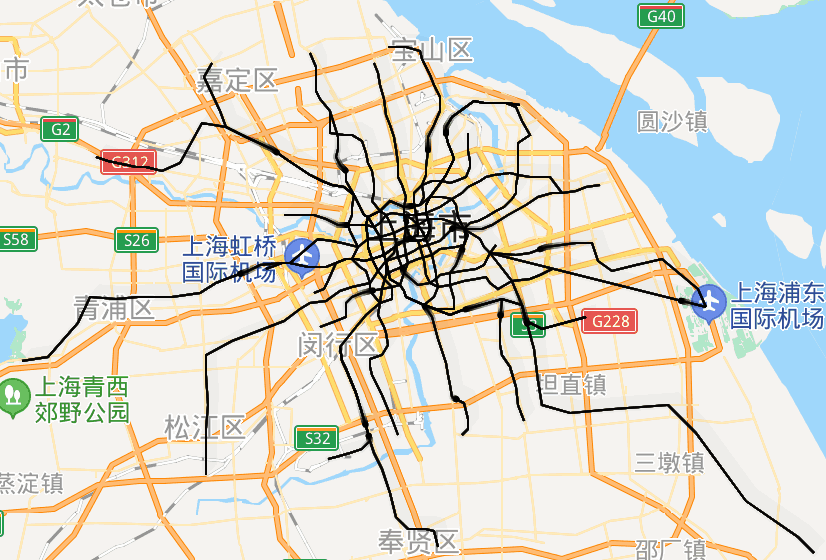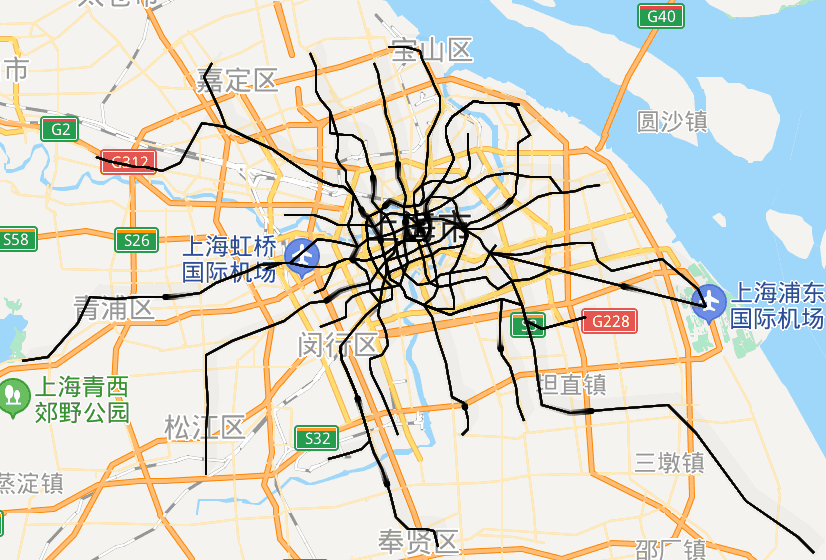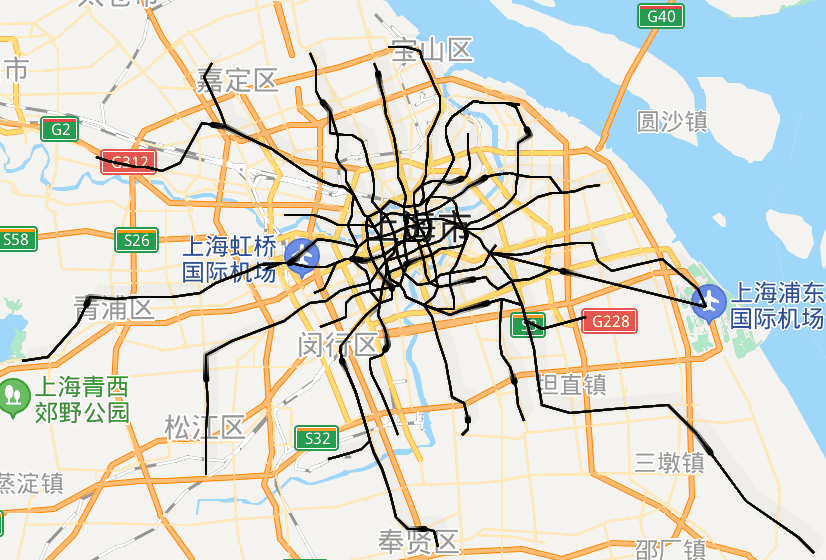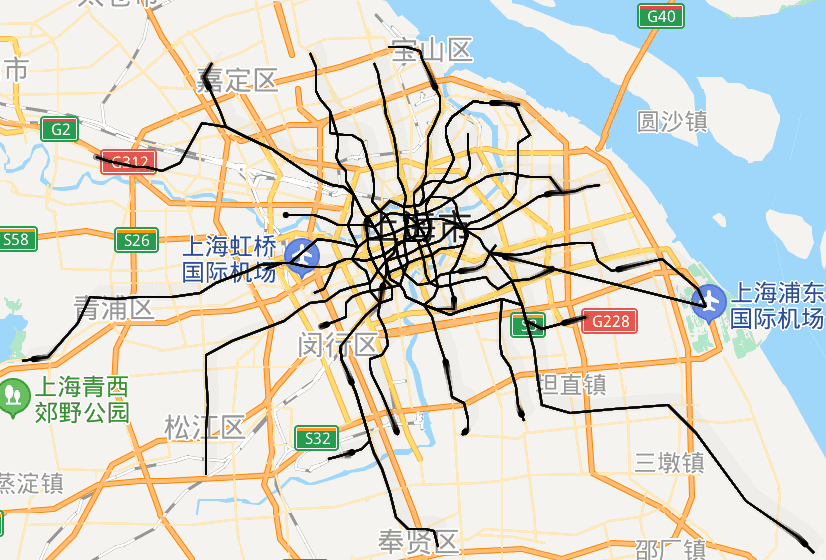
太酷炫了!我用Python画出了北上广深的地铁路线动态图
大家好,我是小五🐶今天教大家用python制作地铁线路动态图,这可能是全网最全最详细的教程了。坐标点的采集小五之前做过类似的地理可视化,不过都是使用网络上收集到的json数据。但很多数据其实是过时的,甚至是错误/不全的。所以我们最好还是要自己动手,丰衣足食(爬虫大法好)。打开高德地图的地铁网页,http://map.amap.com/subway/ind
黎明之道
•
4年前
python爬虫之数据提取Xpath(爬取起点中文网案例)
(https://blog.csdn.net/sjjsaaaa/article/details/111293732)Xpath详细的Xpath介绍手册——https://www.w3school.com.cn/xpa
Karen110
•
4年前
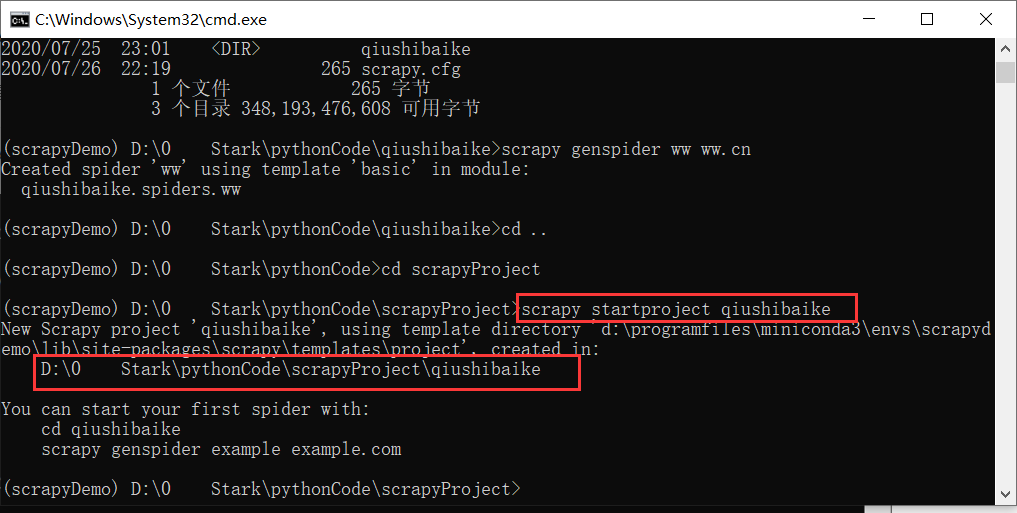
使用Scrapy网络爬虫框架小试牛刀
前言这次咱们来玩一个在Python中很牛叉的爬虫框架——Scrapy。scrapy介绍标准介绍Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的
Stella981
•
4年前
Python中的目录树列表
问题:如何获取Python中给定目录中所有文件(和目录)的列表?解决方案:参考一:https://stackoom.com/question/VO4/Python中的目录树列表(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fstackoom.
Wesley13
•
4年前
MySQL数据库基础——本地文件交互
从这一篇开始,大概会花四五篇的内容篇幅,归纳整理一下之前学过的SQL数据库,一来可以为接下来数据分析工作提前巩固基础,二来把以前学的SQL内容系统化、结构化。今天这一篇仅涉及MySQL与本地文本文件的导入导出操作,暂不涉及主要查询语言以及MySQL与R语言和Python的交互。平台使用NavicatPremium(当然你也可以使用MySQL自带的w
可莉
•
4年前
10 个“疯狂”的 Python 项目创意
↑ 关注星标 ,每天学Python新技能后台回复【大礼包】送你Python自学大礼!(https://oscimg.oschina.net/oscnet/f55965ed8fec4332b094fc9d6da70e9c.png)剧照| 女王的棋局作者|JuanCruzMa
Stella981
•
4年前
Python+Selenium之HTMLTestRunner
下载HTMLTestRunner模块下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html保存路径:将下载的HTMLTestRunner.py文件复制到Python安装路径下的Lib目录验证:在Python交互模式下引入HTMLTestRunner模块,如系统没有报错,则说明添
京东云开发者
•
2年前
玩转服务器之环境篇:PHP和Python环境部署指南 | 京东云技术团队
前几篇文章中讲解了如何搭建docker和JavaWeb环境的方法,本篇文章来教大家搭建一个好的PHP和Python环境,可以帮助开发和运行PHP和Python应用程序,使其更加高效和稳定。
1
•••
84
85
86
•••
1000