推荐
专栏
教程
课程
飞鹅
本次共找到486条
pcm编码
相关的信息
Wesley13
•
4年前
java读取中文文本文件乱码问题
今天遇到的问题是这样:用java读取一个中文文本文件,但读取到的却是乱码,之前一直没有问题,查清楚后,原来是因为今天是用的windows的记事本来编辑的文件,因编码方式是的不同而导致了乱码,解决方法就是设置编码方式为“UTF8”,设置方法如下:FilefilenewFile("文件路径");Readerreader
勾勾今天学习了吗
•
4年前
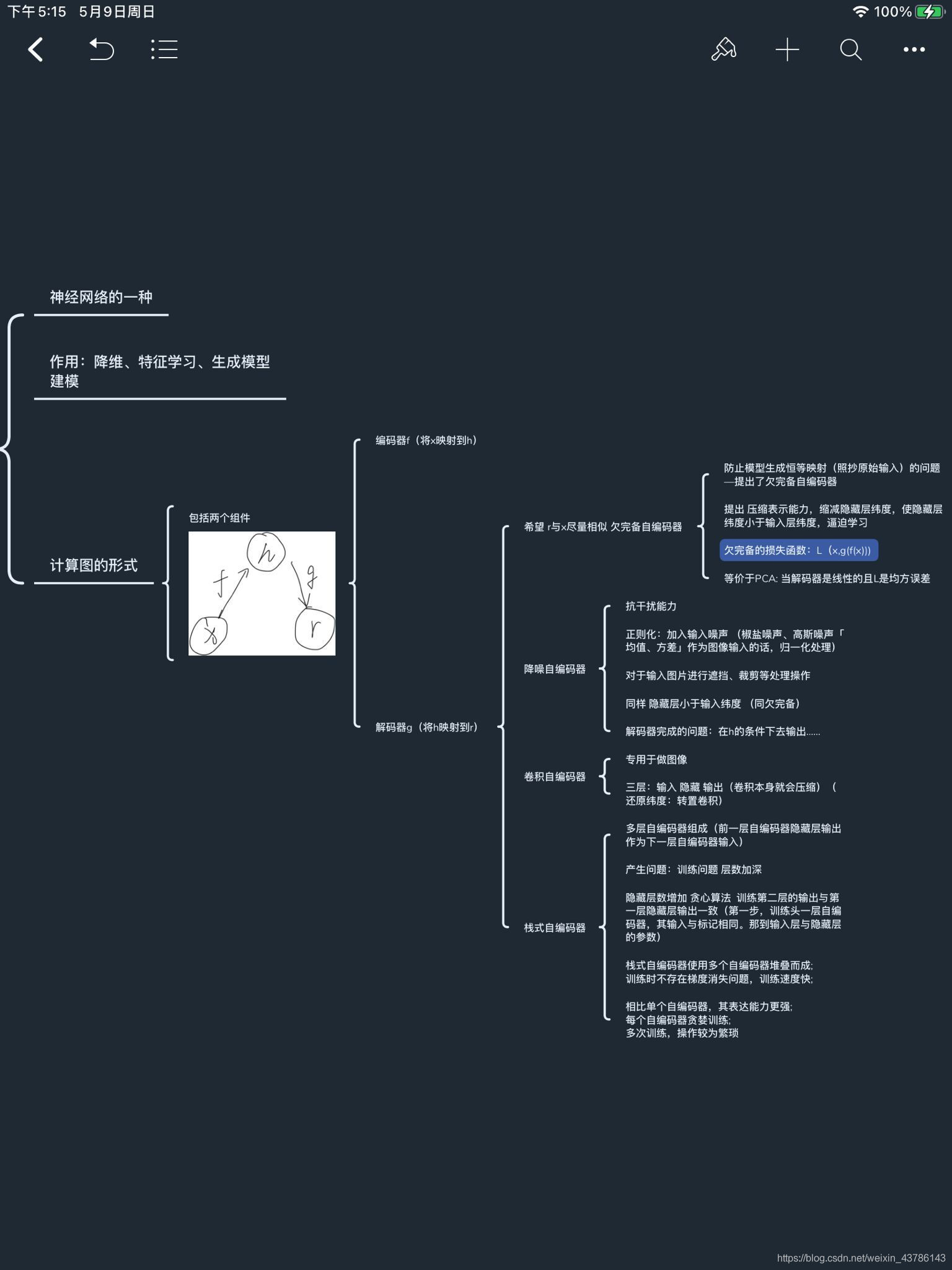
Pytorch构建栈式自编码器实现以图搜图任务(以cifar10做数据集)
(Pytorch构建栈式自编码器实现以图搜图任务)本文旨在使用CIFAR10数据集,构建与训练栈式自编码器,提取数据集中图像的特征;基于所提取的特征完成CIFAR10中任意图像的检索任务并展示效果。搞清楚pytorch与tensorflow区别pytorchpytorch是一种python科学计算框架作用:无缝替换numpy,通过G
Stella981
•
4年前
Google Java 代码规范
1.(1)简介本文档用于Java编程语言的Google源代码编码标准的完整定义。Java源文件定义为Google风格。于其他编程风格指南一样,所涉及的问题不止包含代码格式美化,还包括其他类型的约定或者编码标准。但是本文档主要关注普遍遵循的严格规则,并避免提供意义不明的可执行建议(无论任何方式)。1.1.
Stella981
•
4年前
Netflix:我们是如何评估Codec性能的?
Netflix会定期评估现有和即将推出的视频编解码器,不断优化视频编码技术以提供更高质量的服务。本文介绍了视频编码器性能评估中的几项重要元素以及如何从传统与自适应流媒体两种视角进行编解码器性能对比。本文来自Netflix技术博客,LiveVideoStack进行了翻译。文/JoelSole,LiweiGuo,AndreyNorkin
Wesley13
•
4年前
mysql中Incorrect string value乱码问题解决方案
你是否遇到过类似以下错误?java.sql.SQLException:Incorrectstringvalue:'\\xF0\\x9F\\x92\\x9C'forcolumn'content'atrow1.产生这种异常的原因在于,mysql中的utf8编码最多会用3个字节存储一个字符,如果一个字符的utf8编码占用4个字节
Stella981
•
4年前
Android NDK 吐槽集(不定期更新)
AndroidNDK对于wchar\_t和wcs的支持就是一堆屎.别想轻易使用UTF16编码.相比Win上的C开发对于各种字符编码支持美若天堂,以前居然没发现.强制wchar\_t编译为2字节,wcs系函数不正确,还要自己实现.编译器难道就不能提示下不兼容或者什么的?对于各种wcs系的printf的缺失,
Stella981
•
4年前
RedisTemplate操作命令
字符串操作redis储存的字符串都是以二进制的形式存在!字符串类型的内部编码有3种:int:8个字节的长整型。embstr:小于等于39个字节的字符串。raw:大于39个字节的字符串。Redis会根据当前值的类型和长度决定使用哪种内部编码实现。命令操作返回值set(K
Stella981
•
4年前
Djang1.8+Python2.0迁移到Django2.0+Python3.6注意事项(转)
Djang1.8Python2.0迁移到Django2.0Python3.6注意事项参考:https://blog.csdn.net/weixin\_40475396/article/details/829715411\.编码unicod
Stella981
•
4年前
Elasticsearch 横向扩容以及容错机制
写在前面的话:读书破万卷,编码如有神\参考内容:《Elasticsearch顶尖高手系列快速入门篇》,中华石杉\
Stella981
•
4年前
Android依赖注入应用
依赖注入(DI)是一种设计模式,允许在运行时或编译时移除或改变硬编码的依赖性。使用依赖注入库可以减少编码量、把精力专注在更有价值的地方、降低维护成本。Android程序通常使用注解(Annotation,例如@Click)实现“声明式编程”和依赖注入。注:“声明式编程”告诉机器在什么地方做什么事(Where
1
•••
15
16
17
•••
49