你是否遇到过类似以下错误?
java.sql.SQLException: Incorrect string value: '\xF0\x9F\x92\x9C' for column 'content' at row 1.
产生这种异常的原因在于,mysql中的utf8编码最多会用3个字节存储一个字符,如果一个字符的utf8
编码占用4个字节(最常见的就是ios中的emoji表情字符),那么在写入数据库时就会报错。
mysql从5.5.3版本开始,才支持4字节的utf8编码,编码名称为utf8mb4(mb4的意思是max bytes 4),这种编码方式最多用4个字节存储一个字符。
要想证明这个问题,可以执行以下sql:
select * from
information_schema.CHARACTER_SETS
where CHARACTER_SET_NAME like 'utf8%'
结果如图:

因此,要解决上述异常的发生,需要使用utf8mb4编码。
解决数据库编码后,还需要解决客户端Connection连接对象使用的编码问题。
调用创建的Connection对象执行以下sql:
conn.createStatement().execute("SET names 'utf8mb4'");
如果项目中使用了DataSource数据源,只需要对数据源进行相关配置即可,这里以apache的DBCP数据源为例讲解,在spring框架下配置如下:
<!-- 数据源 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"></property>
<property name="url" value="jdbc:mysql://${${data-source.prefix}.data-source.host-name}:3306/${${data-source.prefix}.data-source.db-name}?characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&maxReconnects=10&allowMultiQueries=true" />
<property name="username" value="${${data-source.prefix}.data-source.username}" />
<property name="password" value="${${data-source.prefix}.data-source.password}" />
<property name="maxActive" value="150" />
<property name="maxIdle" value="2" />
<property name="testOnBorrow" value="true" />
<property name="testOnReturn" value="true" />
<property name="testWhileIdle" value="true" />
<property name="validationQuery" value="select 1" />
<!-- 此配置用于在创建Connection对象时执行指定的初始化sql -->
<property name="connectionInitSqls">
<list>
<value>set names 'utf8mb4'</value>
</list>
</property>
</bean>
以下解释引用自mysql参考手册:
SET NAMES 'charset_name'
SET NAMES显示客户端发送的SQL语句中使用什么字符集。
因此,SET NAMES 'utf8mb4'语句告诉服务器:“将来从这个客户端传来的信息采用字符集utf8mb4”。它还为服务器发送回客户端的结果指定了字符集。(例如,如果你使用一个SELECT语句,它表示列值使用了什么字符集。)
SET NAMES 'x'语句与这三个语句等价:
mysql> SET character_set_client = x;
mysql> SET character_set_results = x;
mysql> SET character_set_connection = x;
执行完此sql语句后,通过此连接对象后续创建的Statement都会成功地执行了。
讲到这里,问题已经得到完美解决,但是我又联想到一个新的问题:
jvm虚拟机运行时,内存中的字符串采用utf-16编码,对于ios中的emoji表情这种用4字节utf-8编码存储的字符,在java运行时又是怎样存储的呢?
于是,我找了一个emoji字符(4个字节的值分别为0xf0,0x9F,0x92,0x9c),做了以下试验。
byte[] bytes = new byte[] { (byte) 0xf0, (byte) 0x9F, (byte) 0x92, (byte) 0x9c };
String s = new String(bytes, Charset.forName("utf-8"));
System.out.println("length:"+s.length());
for (int i=0;i<s.length();i++) {
int ch = s.charAt(i);
System.out.println("0x"+Integer.toHexString(ch));
}
执行结果如下:
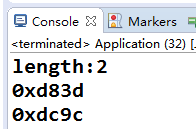
由结果可以看出,unicode值(也叫codePoint码点,后面介绍API会用到)大于0xffff的单个字符,jvm内部占用2个char的长度(也就是4个字节)存储。
所有大于0xffff的字符,全都在UTF编码表的辅助平面内(域辅助平台对应的是基础平面,简称BMP)。因此对于String中的某个char,是基础平面字符,还是辅助平面字符的一部分,也很好做出判断。下面介绍java.lang.Character中的一些API:
以下描述中,码点即是字符的unicode值
Character中API
描述
isValidCodePoint(int codePoint):boolean
判断输入码点是否是有效的,所有属于UTF定义平面的码点都是有效的
isBmpCodePoint(int codePoint):boolean
判断输入码点是否属于基础平面,即:0x0000~0xffff
isSupplementaryCodePoint(int codePoint):boolean
判断输入码点是否属于辅助平面,即:码点>0xffff
isSurrogate(char ch):boolean
判断输入的字符是否辅助平面字符的一部分
获取String中某个字符的码点也很容易,调用String.codePointAt(int index):int即可。
最后,关于unicode、UCS-2、UCS-4、UTF-8、UTF-16编码之间的关系,请读者自行百度。文章太多了,在此就不多做介绍了。
参考资料:
- mysql utf8mb4与emoji表情:
http://my.oschina.net/wingyiu/blog/153357
- 关于 MySQL UTF8 编码下生僻字符插入失败/假死问题的分析