推荐
专栏
教程
课程
飞鹅
本次共找到117条
pandas
相关的信息
Irene181
•
4年前
手把手教你用pandas处理缺失值
导读:在进行数据分析和建模的过程中,大量的时间花在数据准备上:加载、清理、转换和重新排列。本文将讨论用于缺失值处理的工具。缺失数据会在很多数据分析应用中出现。pandas的目标之一就是尽可能无痛地处理缺失值。作者:韦斯·麦金尼(WesMcKinney)译者:徐敬一来源:大数据DT(ID:hzdashuju)pandas对象的所有描述
Irene181
•
4年前
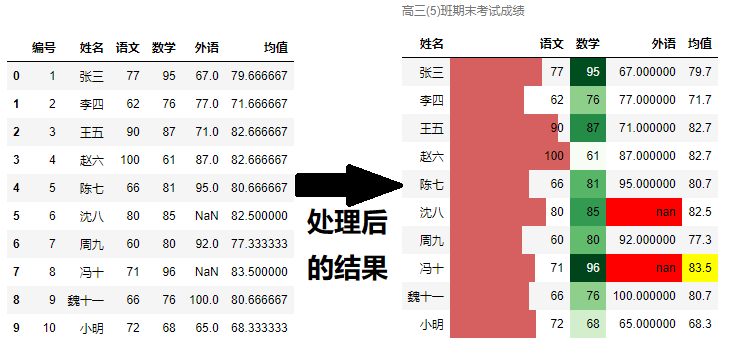
再见,Excel!一行Pandas代码,即可实现漂亮的 “条件格式”!
本文概述Pandas是数据科学家做数据处理时,使用最多的工具。对比Excel,我们可以发现:Pandas基本可以实现所有的Excel的功能,并且比Excel更方便、简洁,其实很多操作我们在过去的文章中,或多或少都讲述过。但是在数据框上,完成各种“条件格式”的设置,帮助我们更加凸显数据,使得数据的展示更加美观,今天还是头一次讲述。上图左表展示的是某班级
Irene181
•
4年前
手把手教你用pandas处理缺失值
导读:在进行数据分析和建模的过程中,大量的时间花在数据准备上:加载、清理、转换和重新排列。本文将讨论用于缺失值处理的工具。缺失数据会在很多数据分析应用中出现。pandas的目标之一就是尽可能无痛地处理缺失值。作者:韦斯·麦金尼(WesMcKinney)译者:徐敬一来源:大数据DT(ID:hzdashuju)pandas对象的所有描述
Karen110
•
4年前
总结了pandas提取数据的15种方法,统统只需1行代码,真香!
pandas是python数据分析必备工具,它有强大的数据清洗能力,往往能用非常少的代码实现较复杂的数据处理今天,鸟哥总结了pandas筛选数据的15个常用技巧,主要包括5个知识点:1.比较运算:、<、、、<、!2.范围运算:between(left,right)3.字符筛选:str.contains(pattern或字符串,naFalse)4.逻辑运算:&
Karen110
•
4年前
再见 for 循环!pandas 提速 315 倍!
来源:Python数据科学作者:东哥起飞上一篇分享了一个从时间处理上的加速方法「」,本篇分享一个更常用的加速骚操作。for是所有编程语言的基础语法,初学者为了快速实现功能,依懒性较强。但如果从运算时间性能上考虑可能不是特别好的选择。本次东哥介绍几个常见的提速方法,一个比一个快,了解pandas本质,才能知道如何提速。下面是一个例子,数据获取方式见文末。
Stella981
•
4年前
DataFrame与shp文件相互转换
因为习惯了使用pandas的DataFrame数据结构,同时pandas作为一个方便计算和表操作的数据结构具有十分显著的优势,甚至很多时候dataFrame可以作为excel在使用,而在用python操作gis的shp文件时很不顺畅,不太符合使用习惯,故写了一个DataFrame与arcgis地理文件相互转换的函数,这个处理起来可以节约大量的思考时间。S
Stella981
•
4年前
Python笔记:用read_html()来抓取table格式的网页数据
read\_html()的基本语法及其参数:pandas.read_html(io,match'.',flavorNone,headerNone,index_colNone,skiprowsNone,attrsNone,parse_datesFalse,thousands',',encodingNone,
Stella981
•
4年前
Hive安装与配置详解
pandas和SQL数据分析实战https://study.163.com/course/courseMain.htm?courseId1006383008&share2&shareId400000000398149(https://www.oschina.net/action/GoToLink?urlhtt
Python进阶者
•
2年前
盘点一个pandas读取excel数据并处理的小需求
大家好,我是皮皮。一、前言前几天在Python最强王者群【wen】问了一个pandas数据处理的问题,一起来看看吧。通过pandas读取excel数据,其中两列是交易的备注信息,对A列数据筛选并把结果输出到C列。如果A列中有二、实现过程这里【东哥】给了一个
Python进阶者
•
2年前
导入的xls文件,数字和日期都是文本格式,到df3都正常,但df4报错,什么原因?
大家好,我是皮皮。一、前言前几天在Python最强王者交流群【斌】问了一个Pandas数据处理的问题,一起来看看吧。我之前用过xls,现在练习pandas:目前导入的xls文件,数字和日期都是文本格式,到df3都正常,但df4报错,df4是算加权平均。下图
1
2
3
4
•••
12