推荐
专栏
教程
课程
飞鹅
本次共找到1203条
nginx集群
相关的信息
菜鸟阿都
•
4年前
liunx服务器web环境搭建从0到1
前几天阿里云推出了新人优惠活动,许多小伙伴都参加了。阿都整理了搭建部署环境的这篇文章帮助同学们去高效的使用服务器。文章中的搭建步骤都是阿都这几年使用并整理的。希望可以帮助到大家。 前言 本文主要讲述搭建web部署环境【nginx、mysql、java】,一般搭建环境有两种方式,一种是从官网上下载文件安装包并上传到服务器【通过xftp】进行安装,另
陈占占
•
3年前
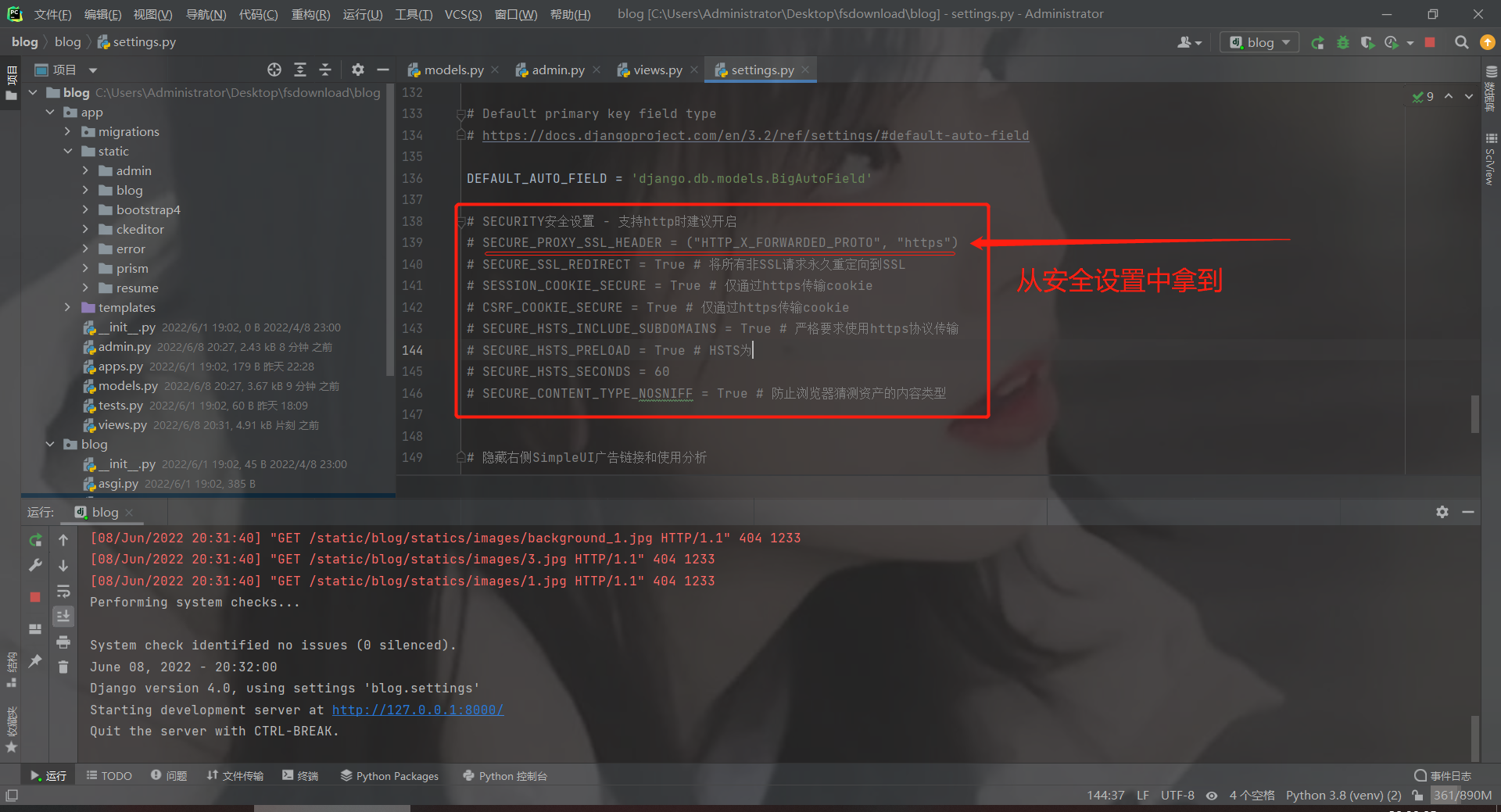
Nginx+uWSGI+Django+SSL(https)安全证书中获取访问的IP地址信息
SECUREPROXYSSLHEADERSSL安全证书中的xforwardedforrequest.META.get("SECUREPROXYSSLHEADER")ifxforwardedfor:useripxforwardedfor.split(',')因为网站服务器会使用ngix等代理https(部署了SSL安全证书)
徐小夕
•
5年前
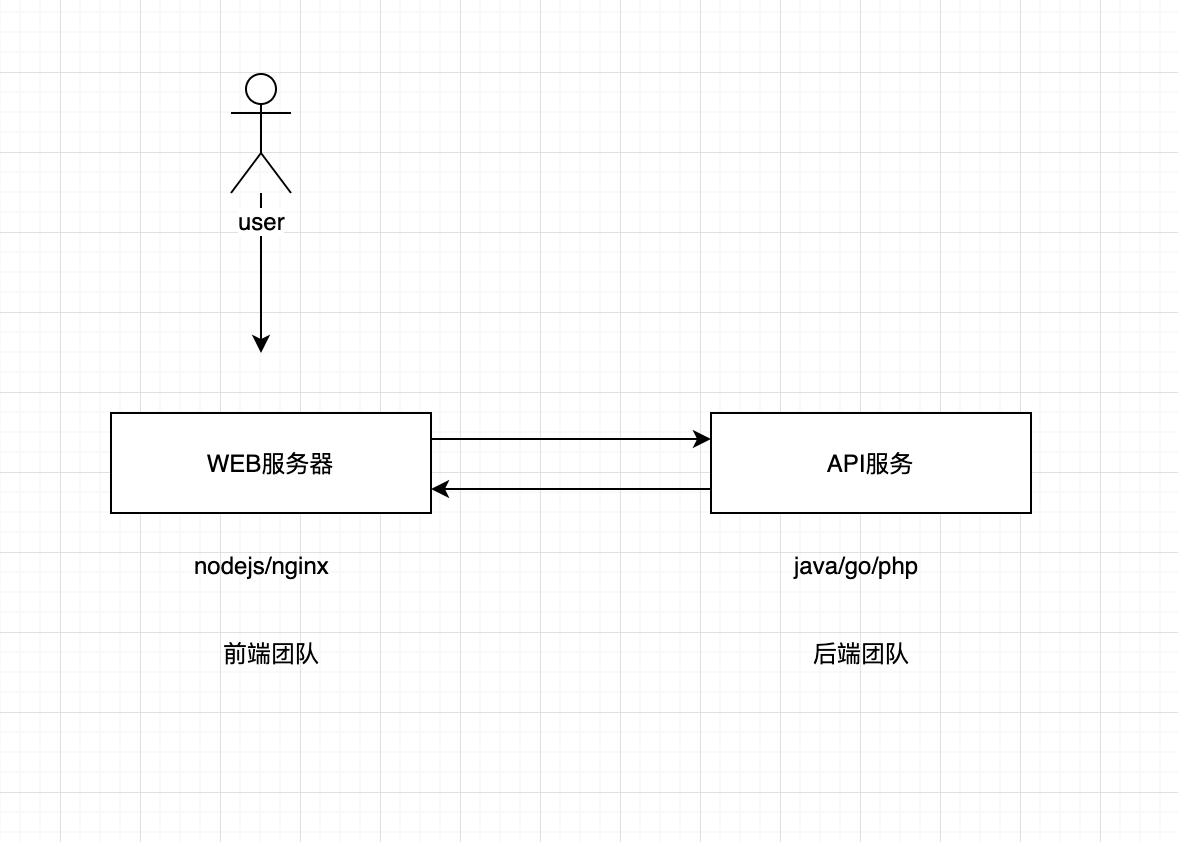
当遇到跨域开发时, 我们如何处理好前后端配置和请求库封装(koa/axios版)
我们知道很多大型项目都或多或少的采用跨域的模式开发,以达到服务和资源的解耦和高效利用.在大前端盛行的今天更为如此,前端工程师可以通过nodejs或者Nginx轻松搭建起web服务器.这个时候我们只需要请求后端服务器的接口即可实现系统的业务功能开发.这个过程中会涉及到web页面向API服务器的跨域访问(由于受到浏览器的同源策略,但是业界已有很多解决方案,
Easter79
•
4年前
springboot+vue前后端分离,nginx代理配置 tomcat 部署war包详细配置
1.做一个小系统,使用了springbootvue基础框架参考这哥们的,直接拿过来用,链接https://github.com/smallsnailwh/interest前期的开发环境搭建就不说了,太多了,自己找吧。2.发布部署将开发好的前端vue代码执行npmrunbuild默认会生成dist文件夹(里面都是一些js文件)in
Stella981
•
4年前
Linux系统:centos7下搭建Nginx和FastDFS文件管理中间件
本文源码:GitHub·点这里(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fcicadasmile%2Flinuxsystembase)||GitEE·点这里(https://gitee.com/cicadasmile/linuxsystem
Stella981
•
4年前
Linux下自动化部署ASP.NET CORE 3.1(Docker+Jenkins+Nginx)
原文:Linux下自动化部署ASP.NETCORE3.1(DockerJenkinsNginx)(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fwww.cnblogs.com%2Fzhoumeng0736%2Farchive%2F2020%2F01%2F04%2F121498
Stella981
•
4年前
Openshift 4.3环境的离线Operatorhub安装
这几天在客户环境中搞Operatorhub的离线,因为已经安装了OpenShift4.3的集群,所以目标是只将考核的ServiceMesh和Serverless模块安装上去即刻,因为前期工作关系,我曾在离线的4.2环境安装过类似组件,所以稍作准备就出发了,但这几天遇到的问题和坑确实不少,4.3和4.2相比在离线方面有很大的改进,但又埋了另外一些坑,本文算
Stella981
•
4年前
Nginx+Tomat8负载后,利用Redis实现Tomcat8的session共享
网上相应的文章应该都介绍,这里只特别记录下笔者在实操的过程出现的问题。此文件只针对tomcat8版本,之前版本可略过。tomcat8中的context.xml文件修改,增加以下配置。Java代码 <ValveclassName"com.radiadesign.catalina.session.RedisSessionHandl
Stella981
•
4年前
Akka
在实际应用中,集群环境里共用一些数据是不可避免的。我的意思是有些数据可以在任何节点进行共享同步读写,困难的是如何解决更改冲突问题。本来可以通过分布式数据库来实现这样的功能,但使用和维护成本又过高,不值得。分布式数据类型distributeddata(ddata)正是为解决这样的困局而设计的。akka提供了一组CRDT(ConflictFreeReplic
天翼云开发者社区
•
6个月前
以“息壤”一体化智算服务平台夯实新质生产力,助力千行百业实现高质量发展!
全国一体化算力网建设是国家战略和时代需求。一是满足爆发的算力需求。人工智能大模型、量子计算等前沿技术催生算力需求指数级增长,通过国产算力集群化供给,可满足前沿技术算力缺口。二是要破解国内算力资源与需求的结构性矛盾。国内算力存在区域失衡,东部算力需求大,但能
1
•••
110
111
112
•••
121