
工欲善其事必先利其器,我们先搭建好我们的开发环境。
安装配置好Docker
首先,我们需要Docker。毕竟我们的重点并不是在安装配置spark上面,怎么简便,怎么做是最好的啦。不过为了适用尽量多的场景,我们会配置一个单机集群,同时配置Pycharm远程调试。
安装Docker的步骤,网上已经有很多了,我们这里贴一个基于CentOS 8系统的安装方式(用户最好是root,省的权限麻烦):
首先配置国内CentOS8镜像,目前阿里云的CentOS8地址有点问题,需要自己修改一些,所以用清华大学的这个源: https://github.com/hackyoMa/docker-centos/blob/8/CentOS-Base.repo
#删除所有的源
cd /etc/yum.repos.d/
rm -f CentOS-Base.repo CentOS-AppStream.repo CentOS-PowerTools.repo CentOS-centosplus.repo CentOS-Extras.repo
# 新建CentOS-Base.repo文件
vim CentOS-Base.repo
将这个地址(https://github.com/hackyoMa/docker-centos/blob/8/CentOS-Base.repo)的内容复制进去,直接下载替换也行,但是网络有时候会失败。
之后执行:
yum clean all
yum makecache
开始安装Docker:
# 安装必要的工具
yum install yum-utils device-mapper-persistent-data lvm2
# 升级containerd
wget https://download.docker.com/linux/centos/7/x86_64/edge/Packages/containerd.io-1.2.6-3.3.el7.x86_64.rpm
yum install containerd.io-1.2.6-3.3.el7.x86_64.rpm
yum install docker-ce
# 开启自动启动docker
systemctl enable docker
# 启动docker
systemctl start docker
接下来来配置下镜像源:
我们来配置一个离自己比较近一点比较快一点的镜像源来节省时间:
# 文件不存在则新建
vi /etc/docker/daemon.json
文件内容:
{
"registry-mirrors": [
"http://hub-mirror.c.163.com/"
]
}
之后重启docker
systemctl restart docker
安装Docker-Compose
# 下载入PATH
curl -L https://github.com/docker/compose/releases/download/1.25.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
# 增加可执行权限
chmod +x /usr/local/bin/docker-compose
好啦,这样我们的Docker环境就配置好了。接下来,进行Spark的安装。
安装单机Spark-Hadoop集群
我们这里使用gettyimages/spark:2.4.1-hadoop-3.0 和bde2020/hadoop3.1.3作为我们的镜像。由于安装好了docker-compose,我们来编写compose文件来简化部署。
首先创建好目录:
mkdir spark
cd spark
vi docker-compose.yml
编写docker-compose.yml:
version: "2.2"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.1.3-java8
container_name: namenode
volumes:
- ./hadoop/namenode:/hadoop/dfs/name
- ./input_files:/input_files
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
ports:
- 50070:9870
- 8020:8020
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.1.3-java8
container_name: resourcemanager
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.1.3-java8
container_name: historyserver
depends_on:
- namenode
- datanode1
- datanode2
volumes:
- ./hadoop/historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.1.3-java8
container_name: nodemanager1
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
datanode1:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.1.3-java8
container_name: datanode1
depends_on:
- namenode
volumes:
- ./hadoop/datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.1.3-java8
container_name: datanode2
depends_on:
- namenode
volumes:
- ./hadoop/datanode2:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.1.3-java8
container_name: datanode3
depends_on:
- namenode
volumes:
- ./hadoop/datanode3:/hadoop/dfs/data
env_file:
- ./hadoop.env
master:
image: gettyimages/spark:2.4.1-hadoop-3.0
container_name: master
command: bin/spark-class org.apache.spark.deploy.master.Master -h master
hostname: master
environment:
MASTER: spark://master:7077
SPARK_CONF_DIR: /conf
SPARK_PUBLIC_DNS: 192.168.0.190
links:
- namenode
expose:
- 4040
- 7001
- 7002
- 7003
- 7004
- 7005
- 7077
- 6066
ports:
- "49100:22"
- 4040:4040
- 6066:6066
- 7077:7077
- 8080:8080
volumes:
- ./conf/master:/conf
- ./data:/tmp/data
- ./jars:/root/jars
worker1:
image: gettyimages/spark:2.4.1-hadoop-3.0
container_name: worker1
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker1
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: 192.168.0.190
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8081
ports:
- 8081:8081
volumes:
- ./conf/worker1:/conf
- ./data/worker1:/tmp/data
worker2:
image: gettyimages/spark:2.4.1-hadoop-3.0
container_name: worker2
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker2
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8082
SPARK_PUBLIC_DNS: 192.168.0.190
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8082
ports:
- 8082:8082
volumes:
- ./conf/worker2:/conf
- ./data/worker2:/tmp/data
注意:
- 将SPARK_PUBLIC_DNS这个配置的ip换成你自己想暴露的机器ip
- 对于master,我们额外暴露了49100映射内部ssh的22端口,因为我们想远程调试。
接着,我们来编写hadoop配置:
vi hadoop.env
文件内容:
CORE_CONF_fs_defaultFS=hdfs://namenode:8020
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource___tracker_address=resourcemanager:8031
然后,我们就能启动啦:
cat docker-compose.yml && cat hadoop.env && docker-compose up -d
第一次启动,会看到:
Creating namenode ... done
Creating datanode2 ... done
Creating master ... done
Creating datanode1 ... done
Creating datanode3 ... done
Creating nodemanager1 ... done
Creating historyserver ... done
Creating resourcemanager ... done
Creating worker2 ... done
Creating worker1 ... done
我们来看一下进程状态:
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
10c62bce757c gettyimages/spark:2.4.1-hadoop-3.0 "bin/spark-class org…" 59 seconds ago Up 57 seconds 7012-7015/tcp, 8881/tcp, 0.0.0.0:8081->8081/tcp worker1
c5606d316b6f gettyimages/spark:2.4.1-hadoop-3.0 "bin/spark-class org…" 59 seconds ago Up 57 seconds 7012-7015/tcp, 8881/tcp, 0.0.0.0:8082->8082/tcp worker2
f1cab2ef952c bde2020/hadoop-resourcemanager:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" 59 seconds ago Up 57 seconds (healthy) 8088/tcp resourcemanager
be137daa762f bde2020/hadoop-nodemanager:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" 59 seconds ago Up 57 seconds (healthy) 8042/tcp nodemanager1
cbb3af010609 bde2020/hadoop-historyserver:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" 59 seconds ago Up 57 seconds (healthy) 8188/tcp historyserver
5c9636d40e36 gettyimages/spark:2.4.1-hadoop-3.0 "bin/spark-class org…" About a minute ago Up 58 seconds 0.0.0.0:4040->4040/tcp, 0.0.0.0:6066->6066/tcp, 0.0.0.0:7077->7077/tcp, 0.0.0.0:8080->8080/tcp, 7001-7005/tcp, 0.0.0.0:49100->22/tcp master
65bd71c17317 bde2020/hadoop-datanode:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" About a minute ago Up 58 seconds (healthy) 9864/tcp datanode1
27ed1975201e bde2020/hadoop-datanode:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" About a minute ago Up 58 seconds (healthy) 9864/tcp datanode3
7e9c9d9d6ad6 bde2020/hadoop-datanode:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" About a minute ago Up 58 seconds (healthy) 9864/tcp datanode2
a545045bd4af bde2020/hadoop-namenode:2.0.0-hadoop3.1.3-java8 "/entrypoint.sh /run…" About a minute ago Up 59 seconds (healthy) 0.0.0.0:8020->8020/tcp, 0.0.0.0:50070->9870/tcp
全都是up之后,部署就是成功了,如果哪个没有成功,通过
docker logs 名称(例如master)
来看下为何没有成功。
注意当前目录下的文件不能删除或者自行修改与修改权限,是镜像里面的文件出来的,如果操作不当会导致集群重启不成功。
访问下spark:http://192.168.0.114:8080  访问下hdfs:http://192.168.0.114:50070
访问下hdfs:http://192.168.0.114:50070 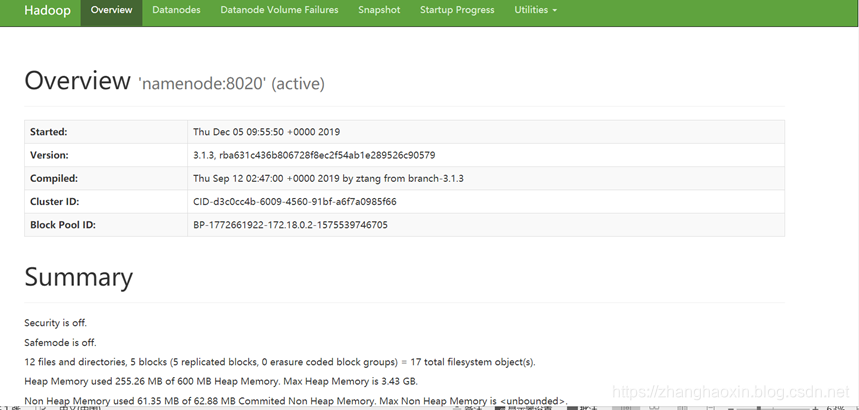
Pycharm远程调试
Pycharm需要是专业版,而不是社区版。社区版是没有这个功能的。
首先,需要对于master允许远程登录。先在master上面安装ssh
#进入容器
docker exec -it master /usr/bash
#更新应用镜像仓库
apt-get update
#安装ssh
apt-get install -y ssh
#安装文本编辑器
apt-get install -y vim
#修改配置
vi /etc/ssh/sshd_config
主要修改PermitRootLogin yes允许root用户登录 为了简单,我们设置root密码:
passwd
之后,master就可以用root和刚刚设置的密码远程登录了。通过49100端口。现在退出master这个容器。
exit
我们来部署python远程调试 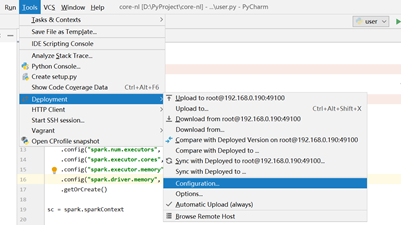
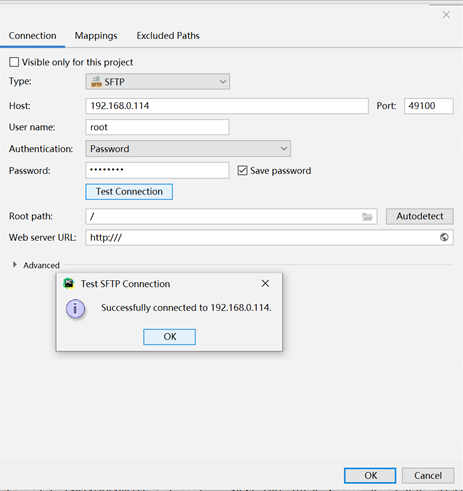
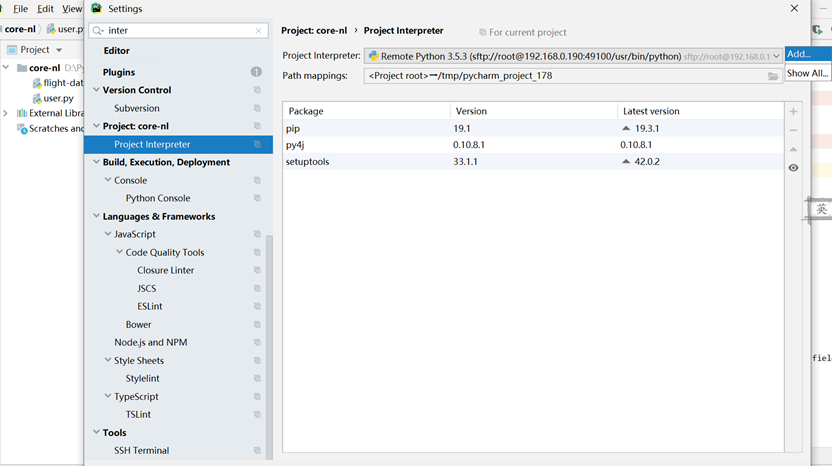
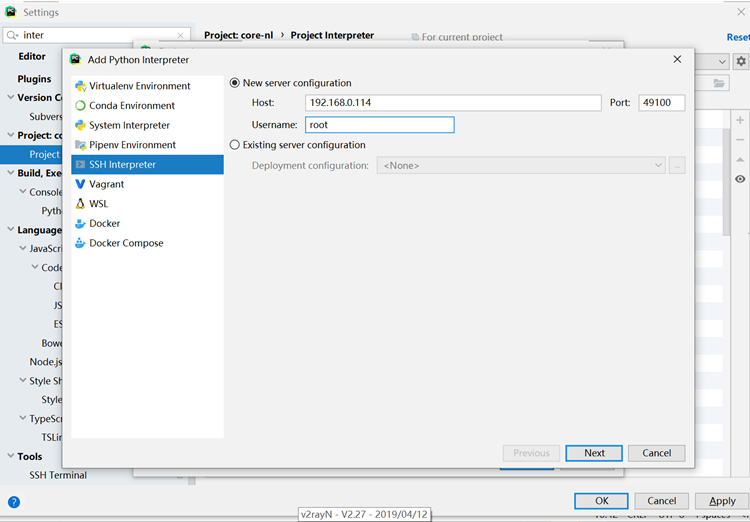
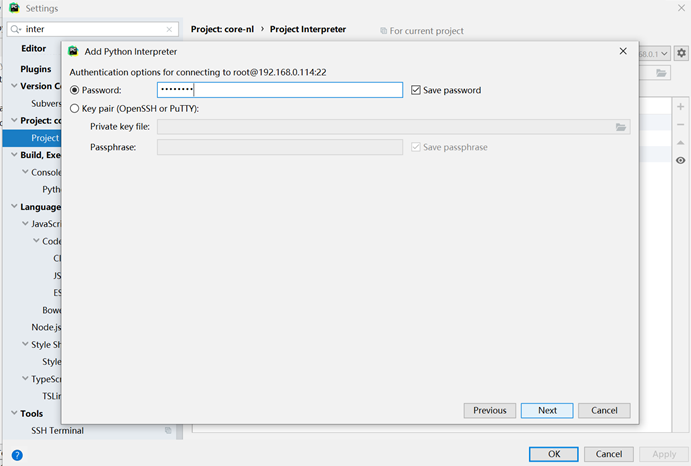
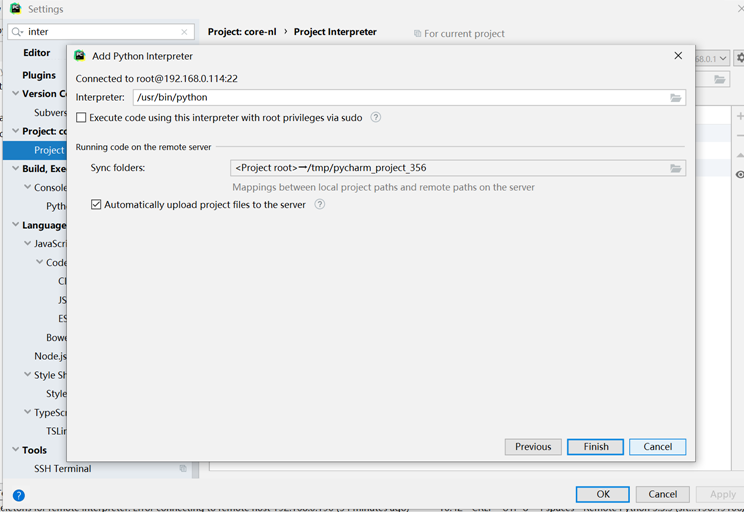
 这样我们就配置好环境了,接下来写一小段代码,测试下test.py:
这样我们就配置好环境了,接下来写一小段代码,测试下test.py:
from pyspark.sql import SparkSession, Row
spark = SparkSession.builder.appName("Hash")\
.config("spark.num.executors", "1") \
.config("spark.executor.cores", "2") \
.config("spark.executor.memory", "600m") \
.config("spark.driver.memory", "600m") \
.getOrCreate()
sc = spark.sparkContext
IDE里面看会有报错,这个问题我们待会解决。我们先来远程运行起来。修改这个文件的运行时候的环境变量。先看看服务器上master的root拥有的环境变量,在机器上执行:
docker exec -it master env
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/hadoop-3.0.0/bin:/usr/spark-2.4.1/bin
HOSTNAME=master
TERM=xterm
MASTER=spark://master:7077
SPARK_CONF_DIR=/conf
SPARK_PUBLIC_DNS=192.168.0.114
LANG=en_US.UTF-8
LANGUAGE=en_US:en
LC_ALL=en_US.UTF-8
PYTHONHASHSEED=0
PYTHONIOENCODING=UTF-8
PIP_DISABLE_PIP_VERSION_CHECK=1
HADOOP_VERSION=3.0.0
HADOOP_HOME=/usr/hadoop-3.0.0
HADOOP_CONF_DIR=/usr/hadoop-3.0.0/etc/hadoop
SPARK_VERSION=2.4.1
SPARK_PACKAGE=spark-2.4.1-bin-without-hadoop
SPARK_HOME=/usr/spark-2.4.1
SPARK_DIST_CLASSPATH=/usr/hadoop-3.0.0/etc/hadoop/*:/usr/hadoop-3.0.0/share/hadoop/common/lib/*:/usr/hadoop-3.0.0/share/hadoop/common/*:/usr/hadoop-3.0.0/share/hadoop/hdfs/*:/usr/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/usr/hadoop-3.0.0/share/hadoop/hdfs/*:/usr/hadoop-3.0.0/share/hadoop/yarn/lib/*:/usr/hadoop-3.0.0/share/hadoop/yarn/*:/usr/hadoop-3.0.0/share/hadoop/mapreduce/lib/*:/usr/hadoop-3.0.0/share/hadoop/mapreduce/*:/usr/hadoop-3.0.0/share/hadoop/tools/lib/*
HOME=/root
我们只需要将SPARK,PYTHON还有HADOOP相关的环境变量复制出来就好,这里是:
MASTER=spark://master:7077
SPARK_CONF_DIR=/conf
SPARK_PUBLIC_DNS=192.168.0.114
PYTHONHASHSEED=0
PYTHONIOENCODING=UTF-8
PIP_DISABLE_PIP_VERSION_CHECK=1
HADOOP_VERSION=3.0.0
HADOOP_HOME=/usr/hadoop-3.0.0
HADOOP_CONF_DIR=/usr/hadoop-3.0.0/etc/hadoop
SPARK_VERSION=2.4.1
SPARK_PACKAGE=spark-2.4.1-bin-without-hadoop
SPARK_HOME=/usr/spark-2.4.1
SPARK_DIST_CLASSPATH=/usr/hadoop-3.0.0/etc/hadoop/*:/usr/hadoop-3.0.0/share/hadoop/common/lib/*:/usr/hadoop-3.0.0/share/hadoop/common/*:/usr/hadoop-3.0.0/share/hadoop/hdfs/*:/usr/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/usr/hadoop-3.0.0/share/hadoop/hdfs/*:/usr/hadoop-3.0.0/share/hadoop/yarn/lib/*:/usr/hadoop-3.0.0/share/hadoop/yarn/*:/usr/hadoop-3.0.0/share/hadoop/mapreduce/lib/*:/usr/hadoop-3.0.0/share/hadoop/mapreduce/*:/usr/hadoop-3.0.0/share/hadoop/tools/lib/*
在test.py的run/debug configuration上面,粘贴这些环境变量,就好。  然后看一下master容器上面pyspark的PYTHONPATH是啥:
然后看一下master容器上面pyspark的PYTHONPATH是啥:
#进入master容器
docker exec -it master /bin/bash
vim /usr/spark-2.4.1/bin/pyspark
找到PYTHONPATH:
export PYTHONPATH="${SPARK_HOME}/python/:$PYTHONPATH"
export PYTHONPATH="${SPARK_HOME}/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH"
再加上这两个作为PYTHONPATH环境变量:
PYTHONPATH=/usr/spark-2.4.1/python:/usr/spark-2.4.1/python/lib/py4j-0.10.7-src.zip
这样就可以远程调试了。我们来看下:  通过把pyspark加入PYTHONPATH,来引入依赖。这样貌似对于IDE不太友好,所以,还是远程安装相应的版本的pyspark依赖吧, 在master容器内执行:
通过把pyspark加入PYTHONPATH,来引入依赖。这样貌似对于IDE不太友好,所以,还是远程安装相应的版本的pyspark依赖吧, 在master容器内执行:
pip install pyspark==2.4.1
本地刷新下远程python编译器依赖,就能看到:  这样,IDE也就好啦。
这样,IDE也就好啦。
远程图形界面
这需要X11转发,但是很遗憾,目前Pycharm并没有支持,不过呢,也提上日程啦~~ Pycharm的X11规划:https://intellij-support.jetbrains.com/hc/en-us/community/posts/360003435280-X11-Forwarding-in-PyCharm 目前来看,群众们比较迫切的需要这个功能了,感觉明年应该有戏,哈哈
网上有通过Xming接受X11转发的方案,但是个人感觉不好,如果真的想画图,我会把数据跑完,下载本地之后,本地做图。











