推荐
专栏
教程
课程
飞鹅
本次共找到3215条
mysql集群
相关的信息
Peter20
•
4年前
【MySQL笔记】正确的理解MySQL的MVCC及实现原理
MVCC多版本并发控制如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!!首先声明,MySQL的测试环境是5.7前提概要什么是MVCC什么是当前读和快照读?当前读,快照读和MVCC的关系MVCC实现原理隐式字段undo日志ReadView(读视图)
Prodan Labs
•
4年前
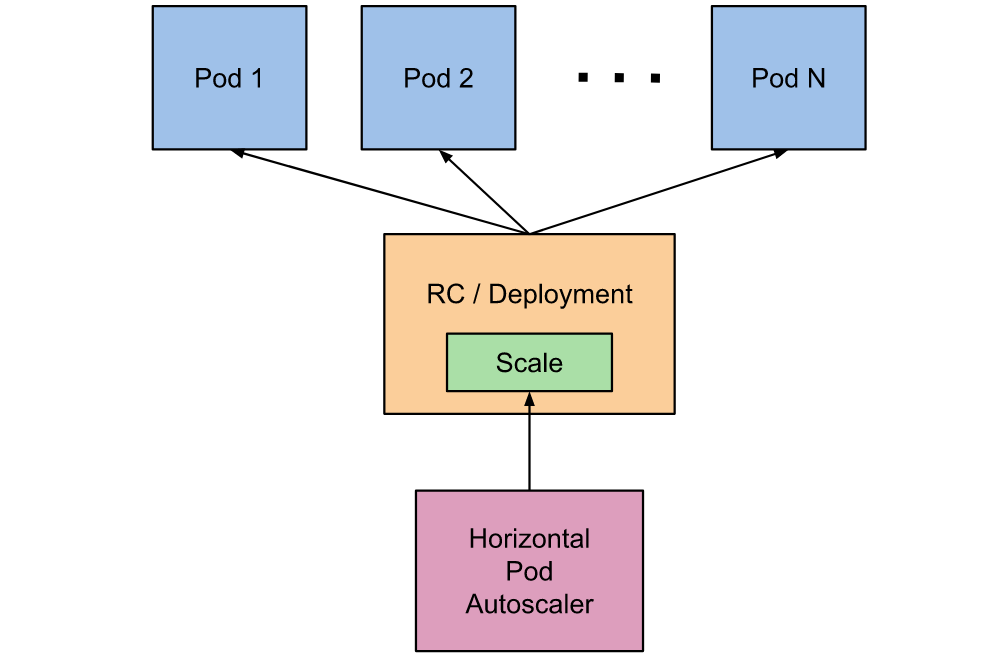
Kubernetes Pod 自动扩容 — HPA
Kubernetes增强了应用服务的横向扩容能力,在应对线上应用服务的资源使用率在高峰和低谷的时候,我们需要能够自动去感知应用的负载变化去调整Pod的副本数量,削峰填谷,提高集群的整体资源利用率和应用的服务质量。为此,Kubernetes1.2版本中引入HorizontalPodAutoscaling(HPA),它与kubectlsc
Wesley13
•
4年前
Mysql —— linux下使用c语言访问mySql数据库
在Linux编写完c代码运行出现没有找到mysql.h是因为没有指定头文件的位置和库文件的位置。命令:gcc\I/usr/include/mysqlXXXX.c\L/usr/lib/mysqllmysqlclientoXXXXXXXX.c:你要编译的文件;XXXX:编译完的文件名;(详解:需要在gcc编译时指定头文件地
Wesley13
•
4年前
MongoDB副本集部署
简述:副本集合(ReplicaSets),是一个基于主/从复制机制的复制功能,但增加了自动故障转移和恢复特性。一个集群最多可以支持7个服务器,并且任意节点都可以是主节点。所有的写操作都被分发到主节点,而读操作可以在任何节点上进行。环境:CentOS5.5x64md0110.0.0.11md0210.0.0.12
Stella981
•
4年前
Hadoop之Mapreduce详解
1、什么是Mapreduce Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;2、Mapreduce框架结构及核心运行机制
Wesley13
•
4年前
ELK
一、基本概念1Node与ClusterElastic本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个Elastic实例。单个Elastic实例称为一个节点(node)。一组节点构成一个集群(cluster)。2IndexElastic会索引所有字段,经过处理后写入一个反向索引
Stella981
•
4年前
Facebook Canopy 初探
原创声明:本文系作者原创,谢绝个人、媒体、公众号或网站未经授权转载,违者追究其法律责任。GoogleDapper首先简单回顾一下Google的Dapper,2010年Google发布Dapper的论文系统阐述了在复杂的、大规模分布式集群环境下如何进行系统的跟踪以及问题的分析与定位。通过产生一个全局唯一
Stella981
•
4年前
Kubernetes Autoscaling是如何工作的?
KubernetesAutoscaling是如何工作的?这是最近我们经常被问到的一个问题。所以本文将从KubernetesAutoscaling功能的工作原理以及缩放集群时可以提供的优势等方面进行解释。什么是Autoscaling想象用水龙头向2个水桶里装水,我们要确保水在装满第一个水桶的80%时,开始注入第二个水桶。解决方法很简单
Stella981
•
4年前
Docker 最常用的镜像命令和容器命令
本文列出了Docker使用过程中最常用的镜像命令和容器命令,以及教大家如何操作容器数据卷,实现容器数据的备份。熟练练习这些命令以后,再来一些简单的应用部署练习,大家就可以学习Docker的镜像构建、备份恢复迁移、镜像仓库、网络、集群等等更多的内容。镜像相关命令 官方文档:https://docs.docker.com/r
天翼云开发者社区
•
2年前
浅谈HPC中的Lustre
Lustre体系结构是一个为集群设计的存储体系结构。其核心组件是运行在Linux操作系统上、支持标准的POSIXUNIX文件系统接口、并遵循GPL2.0许可的Lustre文件系统。据IDC的统计,Lustre是在HPC领域应用最广的文件系统,世界上最快的50个超算网站有60%都使用Lustre。
1
•••
154
155
156
•••
322