推荐
专栏
教程
课程
飞鹅
本次共找到4288条
mysql数据库
相关的信息
九路
•
4年前
如何利用开发者社区提高自己的技术?
如何利用开发者社区提高自己的技术?记得刚从事互联网研发工作时,有一些同事,感觉什么技术都懂,前端,后端,数据库,样样通而且还有一门自己非常擅长的技术,当时是非常的羡慕,心想:啥时候我也能成为别人眼中的技术大牛多好当时月薪几千的我,一定要成为技术大牛,成为月薪过万(当然现在月入过万已经很平常了)尤其是做我们做技术研发的,每个人都想成为技术大牛,都个人都想高薪。
推荐学java
•
4年前
推荐学java——MyBatis高级
补两张知识导图最近的两篇文章和文中缺少了知识结构图,这里补充一下。本节内容是关于MyBatis的高级部分,上节的内容重点是带大家从零开始搭建一个使用MyBatis框架的java项目,并且能使用MyBatis框架完成对数据库中表的增删改查操作;这听起来不难理解,但对于新手要实战一遍,还是需要多加练习,推荐大家通过新建Module的方式来操作。
Stella981
•
4年前
MapReduce 社交好友推荐算法
原理如果A和B具有好友关系,B和C具有好友关系,而A和C却不是好友关系,那么我们称A和C这样的关系为:二度好友关系。在生活中,二度好友推荐的运用非常广泛,比如某些主流社交产品中都会有"可能认识的人"这样的功能,一般来说可能认识的人就是通过二度好友关系搜索得到的,在传统的关系型数据库中,可以通过图的广度优先遍历算法实现,而且深度限定为2,然而在
Wesley13
•
4年前
DDD领域驱动
DDD领域驱动领域驱动模型。模型驱动代码接触到需求第一步就是考虑领域模型,而不是将其切割成数据和行为,然后数据用数据库实现,行为使用服务实现,最后造成需求的首肢分离。DDD让你首先考虑的是业务语言而不是数据,重点不同导致编程世界观不同。具体的问题,具体解决,以后遇到相同的问题,这个问题就成了领域DDD是解决复杂中大型软件的一套行之有效方式,在
李志宽
•
4年前
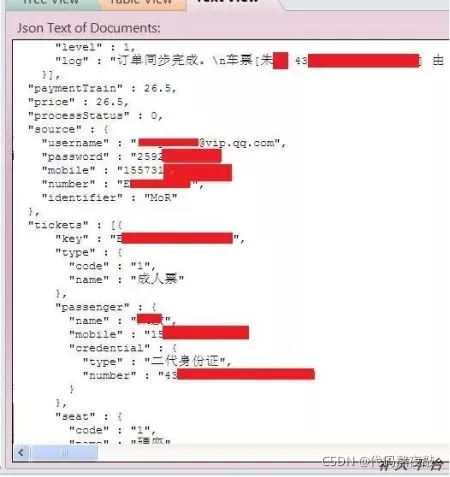
互联网时代 我们每个人都是【小透明】
几年前,我提交了一个漏洞:几百万机票火车票订单用户名明文密码泄露。邮箱,用户身份证,姓名,密码,手机号等重要字段都可以直接明文读取,当时是利用mongodb数据库的未授权访问脚本,稍加修改,批量扫描后发现的漏洞,有国内多家科技媒体跟进报道,搞的我压力也很大,因为数据没有泄露,只是存在漏洞被我提交到360。这种就属于未能遵循简单基础的安全原则,锅可以由商家背。
Stella981
•
4年前
300 分钟撸一个基于 Redis 亿级用户高并发系统
对于618、双十一、春运抢票这种高并发、大流量的场景一般都会用到缓存抗住大并发,市面上缓存框架用的最多的无疑就是Redis了,Redis作为稳居世界排名第一的KV内存数据库,同时也是最受欢迎的分布式缓存中间件,是应对高并发,大流量,低延迟业务场景的不二选择。面试必问!下面这十几道题都是关于Redis大厂面试被问到的,基本都跟Redis架构设计与底层原
Stella981
•
4年前
JVM性能调优详解
前面我们学习了整个JVM系列,最终目标的不仅仅是了解JVM的基础知识,也是为了进行JVM性能调优做准备。这篇文章带领大家学习JVM性能调优的知识。性能调优性能调优包含多个层次,比如:架构调优、代码调优、JVM调优、数据库调优、操作系统调优等。架构调优和代码调优是JVM调优的基础,其中架构调优是对系统影响最大的。性能调优基本上按照以下
Wesley13
•
4年前
Java 并发底层知识,锁获取超时机制知多少?
当我们在使用Java进行网络编程时经常会遇到很多超时的概念,比如一个浏览器请求过程就可能会产生很多超时的地方,当我们在浏览器发起一个请求后,网络socket读写可能会超时,web服务器响应可能会超时,数据库查询可能会超时。而对于Java并发来说,与超时相关的内容主要是线程等待超时和获取锁超时,比如调用Object.wait(long)就会使线程进入等待状并在
Easter79
•
4年前
Spring事务用法示例与实现原理
关于事务,简单来说,就是为了保证数据完整性而存在的一种工具,其主要有四大特性:原子性,一致性,隔离性和持久性。对于Spring事务,其最终还是在数据库层面实现的,而Spring只是以一种比较优雅的方式对其进行封装支持。本文首先会通过一个简单的示例来讲解Spring事务是如何使用的,然后会讲解Spring是如何解析xml中的标签,并对事务进行支持
helloworld_91538976
•
3年前
遥感数字图像处理
遥感数字图像处理的特点:同遥感图像的光学处理(即模拟图像处理)相比,遥感数字图像的计算机处理有很多优点,主要表现在以下几点:1.图像信息损失低,处理的精度高由于数字遥感图像是用二进制表示的,在图像处理时,其数据存储在计算机数据库中,不会因长期存储而损失信息,也不会因处理而损失原有信息。对计算机来说,不管是对4bit还是对8
1
•••
418
419
420
•••
429