推荐
专栏
教程
课程
飞鹅
本次共找到5053条
mysql分表策略
相关的信息
陈占占
•
4年前
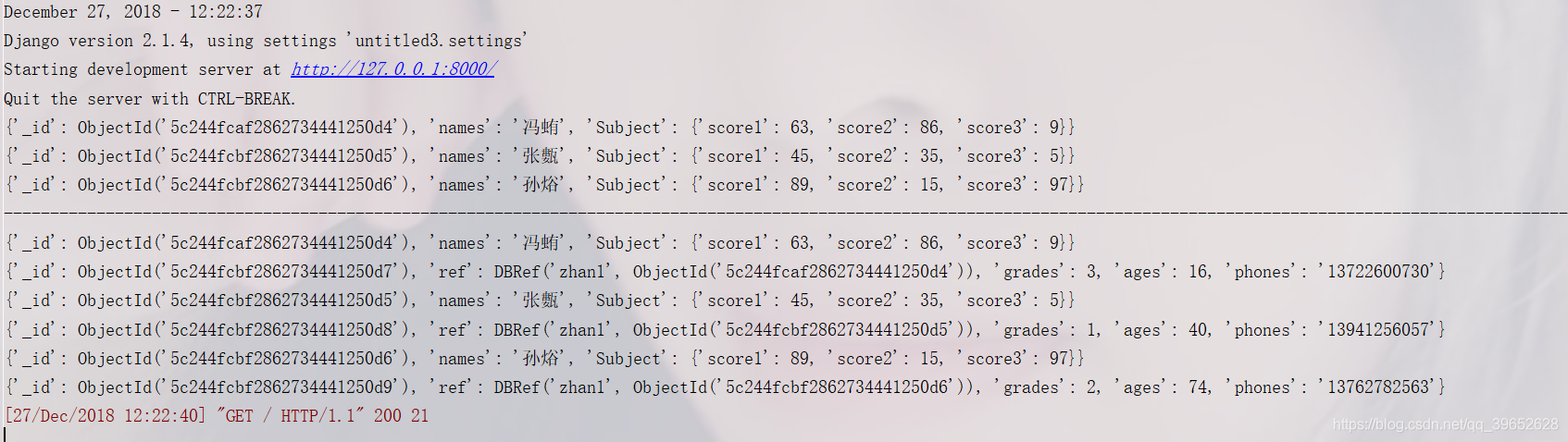
Python Django 循环插入到 MongoDB数据库中
二级标题单对单表关联:开始先循环插入数据到MongoDB中,然后把表1的ID放到表2中,然后就可以通过表2来查看表1了importrandomimportpymongo'''DBRef关联的表'''frombson.dbrefimportDBReffromdjango.httpimportHttpResponsefrombson.obj
Wesley13
•
4年前
mysql 实现 上一行减去下一行
方法1:通过行号来进行加减1.新建表1添加自增行号列(考虑到自增id有丢失数据现象)2.复制上表1为表23.根据表1、表2行号进行where或者leftjoinon的处理\where进行处理的条件为表1表2完全的匹配\leftjoinon处理的条件为 左表完全的匹配设置内存变量
Wesley13
•
4年前
mysql5.5和以上数据库的连接
MySQL 端口:3306 连接方式: mysql5:driver:com.mysql.jdbc.Driver mysql6以上:driver:com.mysql.cj.jdbc.Driver url:jdbc:mysql://localhost:3306/test url:jdbc:mysql:/
Wesley13
•
4年前
Oracle语句总结
1,开始之前先看张图!(http://static.oschina.net/uploads/space/2015/0302/170102_jwKM_2008084.png)A表和B表是数据有重复部分的表,现在如果想获取A表中B表不存在的数据语句有两种:①.使用leftjoin;\假设俩张表中都有共同字段id\selecta.i
Easter79
•
4年前
Springmvc+mybatis+Dubbo+ZooKeeper+Redis+KafKa
开发工具1.EclipseIDE:采用Maven项目管理,模块化。2.代码生成:通过界面方式简单配置,自动生成相应代码,目前包括三种生成方式(增删改查):单表、一对多、树结构。生成后的代码如果不需要注意美观程度,生成后即可用。技术选型(只列了一部分技术)1、后端服务框架:Dubbo、zookeeper、Rest服务缓存:redis
Stella981
•
4年前
SparkSQL的3种Join实现
引言Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。对于Spark来说有3中Join的实现,每种Join对应着不同的应用场景:BroadcastHashJoin:适合一张较小的表和一张大表进行joinShuffleHash
Easter79
•
4年前
Springmvc+mybatis+shiro+Dubbo+ZooKeeper+KafKa
开发工具1.EclipseIDE:采用Maven项目管理,模块化。2.代码生成:通过界面方式简单配置,自动生成相应代码,目前包括三种生成方式(增删改查):单表、一对多、树结构。生成后的代码如果不需要注意美观程度,生成后即可用。技术选型(只列了一部分技术)1、后端服务框架:Dubbo、zookeeper、Rest服务缓存:redis
Wesley13
•
4年前
MYsql客户端图形化工具第一天
客户端图形化工具:SQLyog DML:增删改表中数据(重点) 1.添加数据 \语法: \insertinto表名(列名1,列名2,,,,列名n) values(表1,表2,,表n); \注意: 1.列名和值一一对应
Wesley13
•
4年前
MySQL两千万数据优化&迁移
最近有一张2000W条记录的数据表需要优化和迁移。2000W数据对于MySQL(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.roncoo.com%2Farticle%2Fdetail%2F129594)来说很尴尬,因为合理的创建索引速度还是挺快的,再怎么优化速度也得不到多大提升
京东云开发者
•
2年前
高性能MySQL实战(二):索引 | 京东物流技术团队
我们在上篇:表结构中已经建立好了表结构,这篇我们则是针对已有的表结构和搜索条件为表创建索引。1\.根据搜索条件创建索引我们还是先将表结构的初始化SQL拿过来:CREATETABLEservicelog(idbigintUNSIGNEDNOTNULLAUTO
1
•••
48
49
50
•••
506