推荐
专栏
教程
课程
飞鹅
本次共找到4065条
js获取当前url
相关的信息
liam
•
3年前
5分钟快速上线Web应用和API(Vercel)
上周有个童鞋问我如何快速搭建一个Web应用,想拿来练手,就不考虑购置服务器。我推荐了前段时间很火的Vercel,接下来我带你5分钟上手!Vercel你可以理解为一个部署工具,支持部署静态网页和Node服务,部署后你还可以访问它自带生成的域名https。不仅仅如此,除了他的亲儿子Nextjs之外,它还提供了很多模版支持,譬如:Nuxt.js:Vue的
Caomeinico
•
4年前
小程序手动实现路由拦截
小程序中并没有像vuerouter一样的路由拦截功能,所以需要自己手动实现,下面就把具体的实现方法分享出来供大家参考。具体实现思路与vue相同,定义一个全局的token变量,进入某一个页面的时候判断是否存在这个token是否存在,存在则正常跳转,不存在则跳转到登录页面。创建一个工具文件夹,创建一个routers.js,封装路由拦截的具体代码如
Souleigh ✨
•
5年前
Vuex 4 正式发布:打包现在与 Vue 3 一致
Vuex是一个专门为Vue.js应用程序开发的状态管理模式。Vuex采用集中式存储管理应用的所有组件组件的状态。换句话说,Vuex就是帮开发者存储多个组件共享的数据,方便开发者对其读取的更改的工具。Vuex4正式版本现已发布。Vuex4的改进重点是兼容性。Vuex4支持Vue3,并提供了与Vuex3完全相同的
马丁路德
•
4年前
微信小程序 - 页面间传值
小程序页面间传值大家晚上好,说晚上好是因为是在晚上写的,说这句话是因为这句话开篇不那么突然。那么小程序的页面间传值,在我使用这段时间里,我就非常的主观的把它们分为wx.navigateTo和非wx.navigateTo的,因为wx.navigateTo有一个事件参数event,我从当前页跳转到下一页,如果需要能返回,我都用的wx.naviga
专注IP定位
•
4年前
IP地理定位之数据驱动广告矩阵
网络与数字媒体广告的存在为品牌能够更好的传播与发展起到了良好的推动作用,当前,我们处在全面数字化的大环境下,运用“ip地理定位技术”可以有效提升用户CTR。CTR(ClickThroughRate)即点击通过率,是指网络广告的点击到达率,通俗来讲就是:该广告的实际点击次数除以广告的展现量。数字化依然是大势所趋,越来越多的品牌下沉深耕、垂类与数字化升级,给广告
Stella981
•
4年前
Mycat全局Sequence详解
Mycat全局Sequence详解在分布数数据库设计环节,将一个大表切分成各个子表,并且存储到各个数据节点上,如何保持一条数据记录的全局唯一性是一个关键性问题。mycat提供了一种全局sequence的机制,并且提供了多种实现方案。该文将对Mycat这一块进行讨论,以理清mycat这一块的设计思路。mycat当前提供了master分支提供了三种全局s
Stella981
•
4年前
JavaScript 位运算笔记
之前一直以为,在js的位运算中,双精度浮点数在内部会先被转成32位整数,再执行位运算,然后再转为64位数值,因此效率极低。今天实验发现,对浮点执行位运算只会导致数值不准确,而不会导致效率低下,相比乘法,左移位要快66%(其实就是浮点运算与整数运算的差距)。以下结果在IE7~IE10上测试得出技巧1:移位运算比乘除法快(当因数是2的幂数)
Stella981
•
4年前
Javascript高级编程学习笔记(57)—— 事件(1)事件流
事件JS与HTML的交互是通过事件实现的而事件指的就是:文档或浏览器窗口特定的交互瞬间可以通过侦听器来预定事件,以便在事件发生时执行相应的代码这种模式也是设计模式中的观察者模式事件流有了事件,也就有了事件流的概念事件流故名思意:也就是事件的流向,所以事件流描述的是从页面中接收事件的顺序虽然事件流描述的都是事件的流
个推技术实践
•
3年前
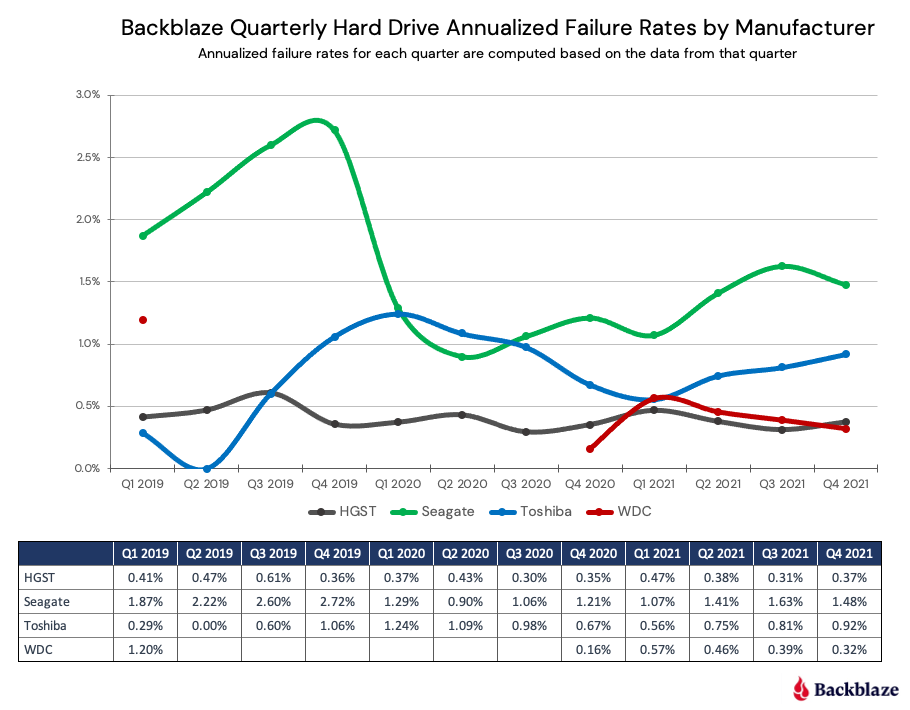
个推技术 | Hadoop3.0时代,怎么能不懂EC纠删码技术
根据云存储服务商Backblaze发布的2021年硬盘“质量报告”,现有存储硬件设备的可靠性无法完全保证,我们需要在软件层面通过一些机制来实现可靠存储。一个分布式软件的常用设计原则就是面向失效的设计。作为当前广泛流行的分布式文件系统,HDFS需要解决的一个重要问题就是数据的可靠性问题。3.0以前版本的Hadoop在HDFS上只能采用多副本冗余的方式做数据备份
天翼云开发者社区
•
3年前
天翼云加码边缘计算,让普惠算力触手可及!
8月25日,亚太内容分发大会暨CDN峰会在京召开。大会汇集CDN产业领军企业,聚焦产业前沿科技突破,共同探讨边缘计算发展趋势与创新应用。天翼云科技有限公司高级研发经理张其栋出席“边缘计算论坛”并发表主题演讲,分享了天翼云边缘计算的发展规划与实践案例。天翼云科技有限公司高级研发经理张其栋当前,边缘计算发展势头强劲,Gartner预计到2025年将有超过75%的
1
•••
341
342
343
•••
407