推荐
专栏
教程
课程
飞鹅
本次共找到10000条
android搜索功能实现
相关的信息
半臻
•
4年前
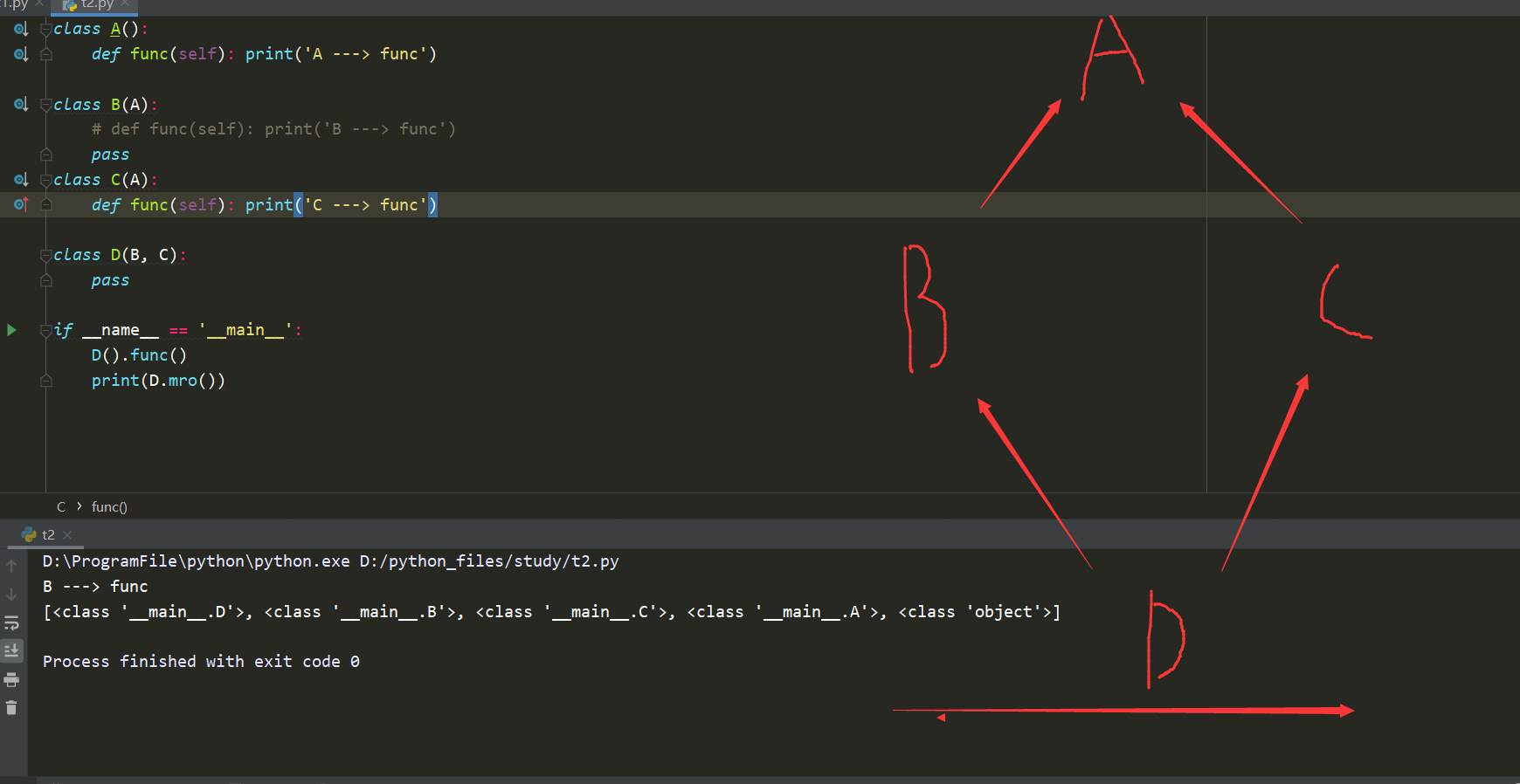
Python基础6——面向对象
14面向对象14.1面向对象基础面向对象是一种编程思想,处理面向对象编程以外,还有面向过程编程三大特征:1.封装2.继承3.多态面向过程与面向对象的区别1.面向过程:自己动手洗衣服,拧衣服、晾衣服2.面向对象:构造一个洗衣机对象,让洗衣机对象完成14.2类和对象类:相同属性和功能的一类事物。人是一个类,张三(
艾木酱
•
3年前
快速入门|使用MemFire Cloud构建Vue3应用程序
MemFireCloud是一款提供云数据库,用户可以创建云数据库,并对数据库进行管理,还可以对数据库进行备份操作。它还提供后端即服务,用户可以在1分钟内新建一个应用,使用自动生成的API和SDK,访问云数据库、对象存储、用户认证与授权等功能,可专注于编写前端应用程序代码,加速WEB或APP应用开发。此示例提供了使用MemFireCloud和Vue3
学python的猫
•
4年前
零基础应该如何开始学习python
随着人工智能时代的到来,Python也在不断发展壮大,越来越多的人选择学Python,只要因为它容易学习,功能又强大还可以跨平台。其实Python作为一门脚本语言,难度上相较于其他语言略微简单点,但是对于没有计算机基础的人来说,也是非常难得,可能安装这一步就会难倒大家!1、Python学习确定方向对于刚入门的人来说,要先把Python基础和进阶学透,再继续往
Python进阶者
•
4年前
盘点那些年我们一起玩过的网络安全工具
大家好,我是IT共享者,人称皮皮。这篇文章,皮皮给大家盘点那些年,我们一起玩过的网络安全工具。一、反恶意代码软件1.Malwarebytes这是一个检测和删除恶意的软件,包括蠕虫,木马,后门,流氓,拨号器,间谍软件等等。快如闪电的扫描速度,具有隔离功能,并让您方便的恢复。包含额外的实用工具,以帮助手动删除恶意软件。分为两个版本,Pro和Free,Pro版
Stella981
•
4年前
Python3 迭代器与生成器
点击上方Z先生点记,加为星标第一时间收到Python技术干货!转自:Python那些事迭代器迭代是Python最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器有两个基本的方
Stella981
•
4年前
JVM参数以及用法
工作以后,发觉真的几乎没有像大学那样空闲的时间,坐下来看看书写写博客了。最近的一篇博客距离现在已经近一个多月了,最近也在复习Java的东西,准备校招,看了看JVM的东西,就当作记笔记。(一)JVM参数:第一类包括了标准参数。顾名思义,标准参数中包括功能和输出的参数都是很稳定的,很可能在将来的JVM版本中不会改变。你可以
Stella981
•
4年前
Linux的Shell编程 Shell程序设计的流程控制
和其他高级程序设计语言一样,Shell提供了用来控制程序执行流程的命令,包括条件分支和循环结构,用户可以用这些命令创建非常复杂的程序。与传统语言不同的是,Shell用于指定条件值的不是布尔运算式,而是命令和字串。1.测试命令test命令用于检查某个条件是否成立,它可以进行数值、字符和文件3个方面的测试,其测试符和相应的功能分别如下。(1)数值
Stella981
•
4年前
Javascript模块化编程(二):AMD规范
七、模块的规范先想一想,为什么模块很重要?因为有了模块,我们就可以更方便地使用别人的代码,想要什么功能,就加载什么模块。但是,这样做有一个前提,那就是大家必须以同样的方式编写模块,否则你有你的写法,我有我的写法,岂不是乱了套!考虑到Javascript模块现在还没有官方规范,这一点就更重要了。目前,通行的Javascript模块规范共
WeiSha100
•
3年前
心理学考试培训系统源码
可用于搭建心理学考试培训系统,源码开放,支持多机构,有网页,微信小程序和APP,私有化部署,有点播,直播,题库,考试,督学,在线支付等功能,经测试完整可用,推荐给有需要的朋友!1、点播:在线点播视频,可上传图文资料,习题,课件等2、直播:对接七牛云端口,弹性带宽,直播可转存为点播课程3、题库:可批量管理上传的题库,随时随地刷题4、考试:多场景考试设置,客观
WeiSha100
•
3年前
开源点播直播刷题考试平台源代码
学习类开源系统源代码,有开发文档,前后台源码,源码可二次开发。私有化部署,内网外网均可部署,支持多个终端,功能有点播,题库,直播,考试,督学,营销等,经搭建测试完整可用。1、点播:在线点播视频,可上传图文资料,习题,课件,视频防盗,课堂交流2、直播:对接七牛云端口,弹性带宽,直播可转存为点播课程3、课后刷题:可批量管理上传的题库,随时随地刷题,并且试题防复
1
•••
988
989
990
•••
1000