推荐
专栏
教程
课程
飞鹅
本次共找到3338条
网页设计
相关的信息
Wesley13
•
4年前
java实现 PageRank算法
PageRank算法是Google的核心搜索算法,在所有链接型文档搜索中有极大用处,而且在我们的各种关联系统中都有好的用法,比如专家评分系统,微博搜索/排名,SNS系统等。 PageRank算法的依据或思想: 1,被重要的网页链接的越多(外链) ,此网页就越重要 2,此网页对外的链接越少越重要 这两个依据不能
Irene181
•
4年前
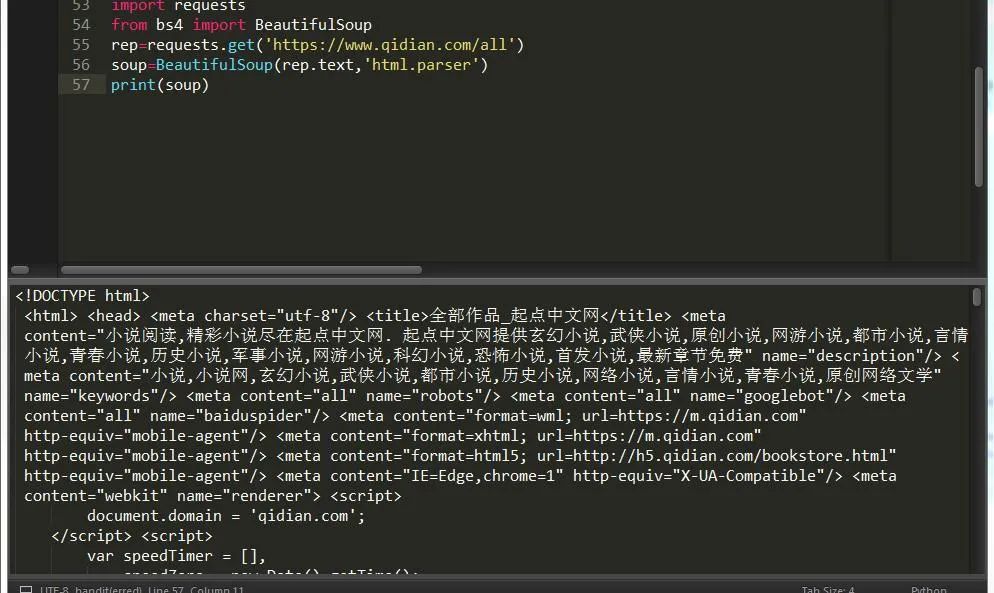
深入解析网页结构解析模块beautifulsoup
大家好,我是Python进阶者,今天给大家分享一个网页结构解析模块beautifulsoup。前言beautifulsoup(以下简称bs),是一款网页结构解析模块,它支持传统的Xpath,css selector语法,可以说很强大了,下面我们就来着重介绍下它的用法。安装bs可以使用pip或者easy\install安装,方便快捷。pip in
Wesley13
•
4年前
UIWebView出现的webViewDidFinishLoad一直没触发的问题的解决方案
可能是由于网页上html不合规范的问题,使得第一种方法加载完网页会不调用webViewDidFinishLoad,但用第二种会调用webViewDidFinishLoad第一种://不调用webViewDidFinishLoadNSURLRequest\req\\NSURLRequestalloc\initWithURL:\N
Ben611
•
4年前
16个 HTML5 框架、模板以及生成工具
网页设计通常需要预先考虑很多因素,而用户给你的时间又特别稀缺,如何提高效率其实是一个比较烦人的问题。一个可行方式就是使用预先准备好的框架和模板,HTML5框架、模板以及生成器是一个万灵丹似的解决方案,可以大大简化很多工作量。这里介绍一些比较实用的工具,
Stella981
•
4年前
Nginx+uwsgi+ssl配置https
使用原始django,太过于笨重和杂多nginx是一个轻量级的web服务器,在处理静态资源和高并发有优势uwsgi是一个基于python的高效率的协议,处理后端和动态网页有优势所以这里采用静态网页交给nginx解析,动态网页交给uwsgi解析,并且nginx配置ssl,即可以使用出高安全,高效率的部署。步骤我
Stella981
•
4年前
HtmlExtractor 1.1 发布,网页信息抽取组件
HtmlExtractor(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fysc%2FHtmlExtractor)是一个Java实现的基于模板的网页结构化信息精准抽取组件,本身并不包含爬虫功能,但可被爬虫或其他程序调用以便更精准地对网页结构化信息进行抽取。
Wesley13
•
4年前
ubuntu 在firefox,网页听不了音乐
Stella981
•
4年前
JavaScript DOM编程艺术(第2版)学习笔记1(1~4章)
第一章一些基本概念HTML(超文本标记语言),构建网页的静态结构,由一系列的DOM组成;CSS(层叠样式表),给网页各部分结构添加样式;JavaScript,通过获取DOM给静态结构加上动作,使用户能够与静态网页进行交互;DOM,一种API(应用程序接口),通过这个接口动态的访问和修改结构或样式。浏
Python进阶者
•
1年前
想获取JS加载网页的源网页的源码,不想获取JS加载后的数据
大家好,我是Python进阶者。一、前言前几天在Python钻石交流群【梦】问了一个Python网络爬虫的问题,这个网站不知道使用了什么反爬手段,都获取不到页面数据。原来的那篇文章竟然爆文了,突破了1.5w的阅读量,欢迎大家围观。不过这里粉丝的需求有点奇怪
1
•••
8
9
10
•••
334