推荐
专栏
教程
课程
飞鹅
本次共找到2376条
网络爬虫
相关的信息
Irene181
•
4年前
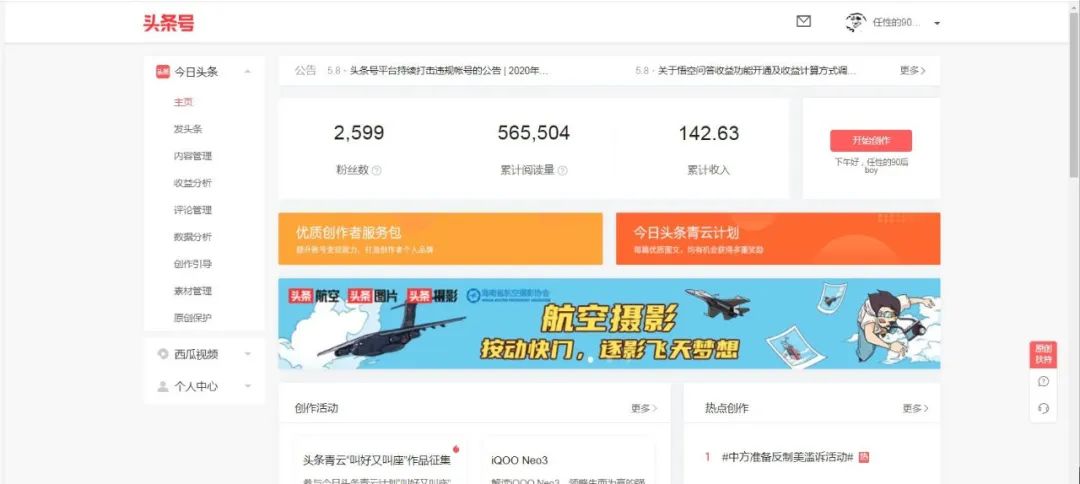
手把手教你用Python网络爬虫获取头条所有好友信息
前言大家好,我是黄伟。今日头条我发觉做的挺不错,啥都不好爬,出于好奇心的驱使,小编想获取到自己所有的头条好友,看似简单,那么情况确实是这样吗,下面我们来看下吧。项目目标获取所有头条好友昵称项目实践编辑器:sublimetext3浏览器:360浏览器,顺带一个头条号实验步骤1.登陆自己的头条号:可以看到2599,不知道谁会是下一个幸运观众了,
Irene181
•
4年前
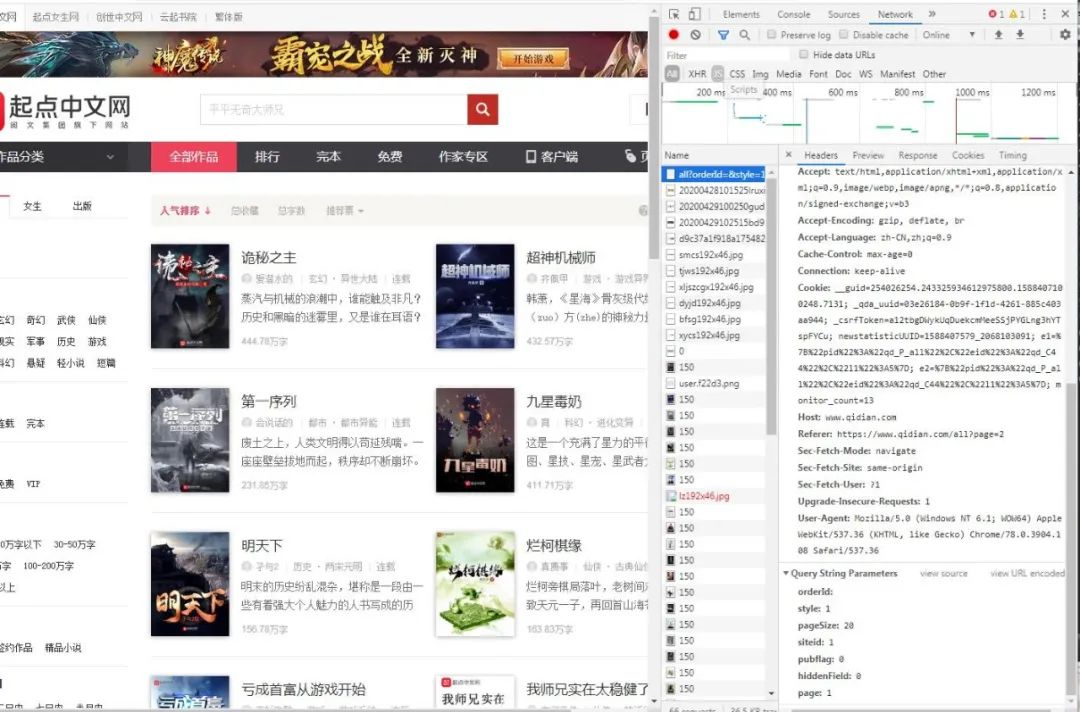
手把手教你用Python网络爬虫实现起点小说下载
今天要跟大家分享一个小说爬取案例起点小说的小说下载。在做这个案例之前,我们需要对其进行分析,1.界面分析,如图:通过分析很容易就找到了我们的get请求参数,然后获取相应页面的小说名和链接:获取到数据之后,我们就随机挑选一篇小说来进行下载,我们选第一篇,然后打开它的文章目录,可以看到是这样的,如图:基本上这篇小说很长,可以看到它卷一和卷二是免费的,后面的收费,
Stella981
•
4年前
Scrapy框架之分布式操作
一、分布式爬虫介绍 分布式爬虫概念:多台机器上执行同一个爬虫程序,实现网站数据的分布爬取。1、原生的Scrapy无法实现分布式爬虫的原因?调度器无法在多台机器间共享:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start\_urls列表中的url。管
Stella981
•
4年前
Selenium使用代理出现弹窗验证如何处理
部分商业网站对爬虫程序限制较多,在数据采集的过程中对爬虫请求进行了多种验证,导致爬虫程序需要深入分析目标网站的反爬策略,定期更新和维护爬虫程序,增加了研发的时间和投入成本。这种情况下,使用无头浏览器例如Selenium,模拟用户的请求进行数据采集是更加方便快捷的方式。同时为了避免目标网站出现IP限制,配合爬虫代理,实现每次请求自动切换IP,能够保证长期稳定
飞速低代码平台
•
7个月前
微服务链路关系梳理
微服务关系梳理如下目前如飞速低代码平台等低代码平台都采用微服务架构。推荐几个开源爬虫项目用灵燕智能体平台开发agent时应用,常用到爬虫工具,推荐几款开源爬虫项目:https://gitee.com/AJay13/ECommerceCrawlershttp
小白学大数据
•
1个月前
Python爬虫伪装策略:如何模拟浏览器正常访问JSP站点
一、为何JSP站点需要伪装?反爬虫机制探秘在编写代码之前,理解我们的“对手”至关重要。JSP站点通常通过以下几种方式识别和拦截爬虫:UserAgent检测:这是最基础的检测点。使用Python的requests库默认的UserAgent会直接暴露爬虫身份。
Python进阶者
•
3年前
盘点一个Python网络爬虫过程中中文乱码的问题
大家好,我是皮皮。一、前言前几天在Python黄金交流群有个叫【Mt.Everest】的粉丝问了一个关于Python网络爬虫过程中中文乱码的问题,这里拿出来给大家分享下,一起学习。二、解决过程这个问题其实很早之前,我就写过相关文章,而且屡试不爽。【Python进阶者】解答这里给出了两个思路,照着这个思路去的话,问题不大。事实上并不巧,还是翻车了。【黑
子桓
•
2年前
Mac电脑网络爬虫开发工具 Screaming Frog SEO Spider 激活最新
ScreamingFrogSEOSpider是一款流行的SEO工具,它可以帮助网站管理员和SEO专业人员分析和优化网站。该软件可以在Mac系统上运行,提供多种功能。具体来说,ScreamingFrogSEOSpider可以爬取整个网站,提供详细的SEO分析
Python进阶者
•
1年前
Python网络爬虫的时候json=就是让你少写个json.dumps()
大家好,我是皮皮。一、前言前几天在Python白银交流群【空翼】问了一个Python网络爬虫的问题,提问截图如下:登录请求地址是这个:二、实现过程这里【甯同学】给了一个提示,如下所示:估计很多小伙伴和我一样会有一个疑问吧,为啥这次要用jsondata啊?因
1
•••
12
13
14
•••
238