推荐
专栏
教程
课程
飞鹅
本次共找到5949条
端到端
相关的信息
helloworld_78018081
•
4年前
这可能是目前最全的!java开发手册嵩山版
在这里分享一份mybatis从入门到精通的强力教程,定能够助你一臂之力。Mybatis基本介绍1.ORM和MyBatis1.对象/关系数据库映射(ORM)1.基本映射方式1.流行的ORM框架简介目前流行的编程语言,例如Java、C等,都是面向对象的编程语言;而目前主流的数据库产品,例如Oracle、DB2等,依然是关系数据库。编程语言和底
简
•
4年前
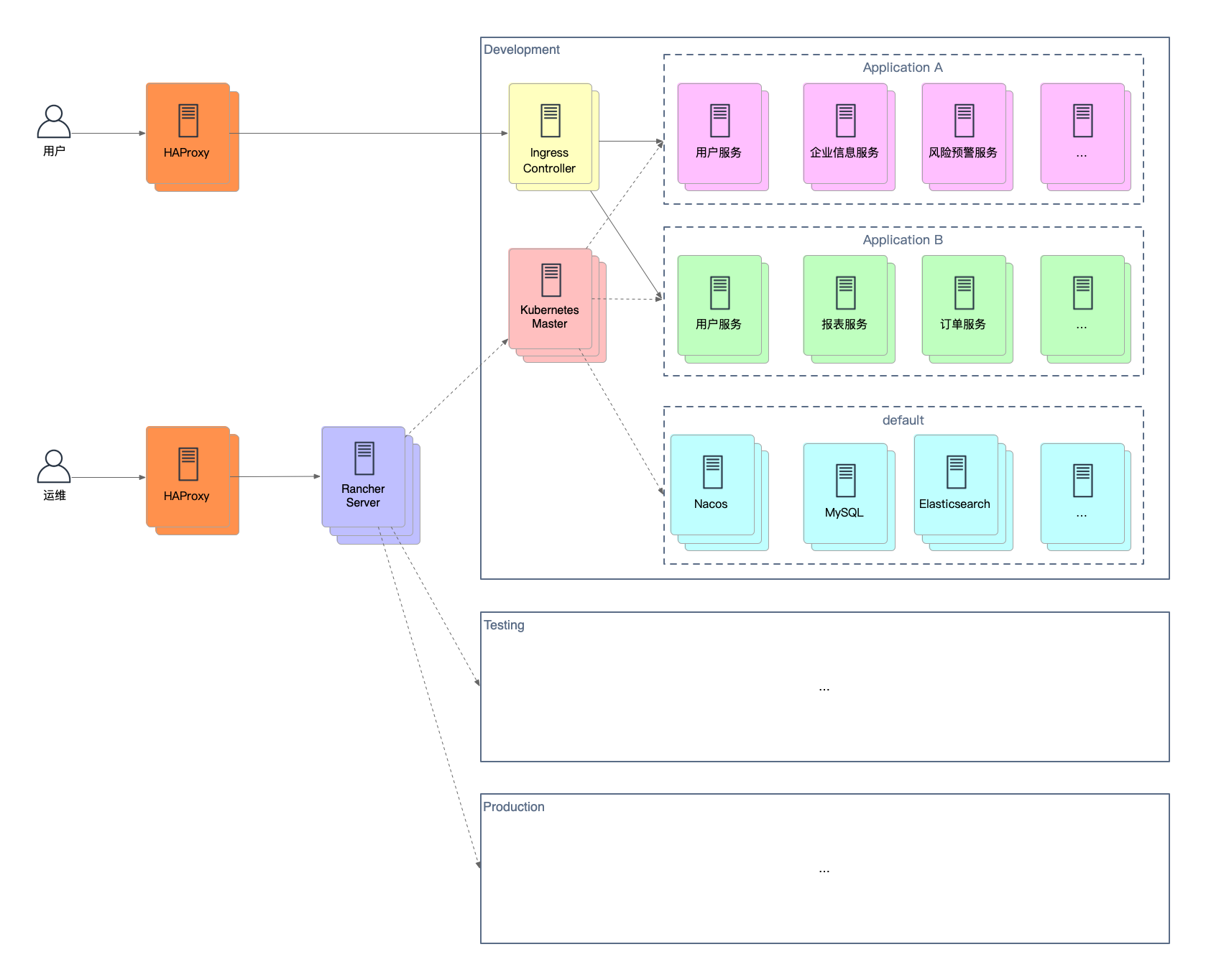
Kubernetes + GitLab 微服务应用自动化部署
KubernetesGitLab微服务应用自动化部署Docker简化了单个服务的部署,Kubernetes通过强大的容器编排能力使得运维人员可以轻松管理成千上万的容器,这些容器归属于多个服务,而这些服务又组合形成了多个应用。从代码到运行中的应用,需要经历构建、打包、测试和部署等阶段,如果每个步骤都手动执行,无疑会消耗研发人员的大量时间。本文讲解
BichonCode
•
5年前
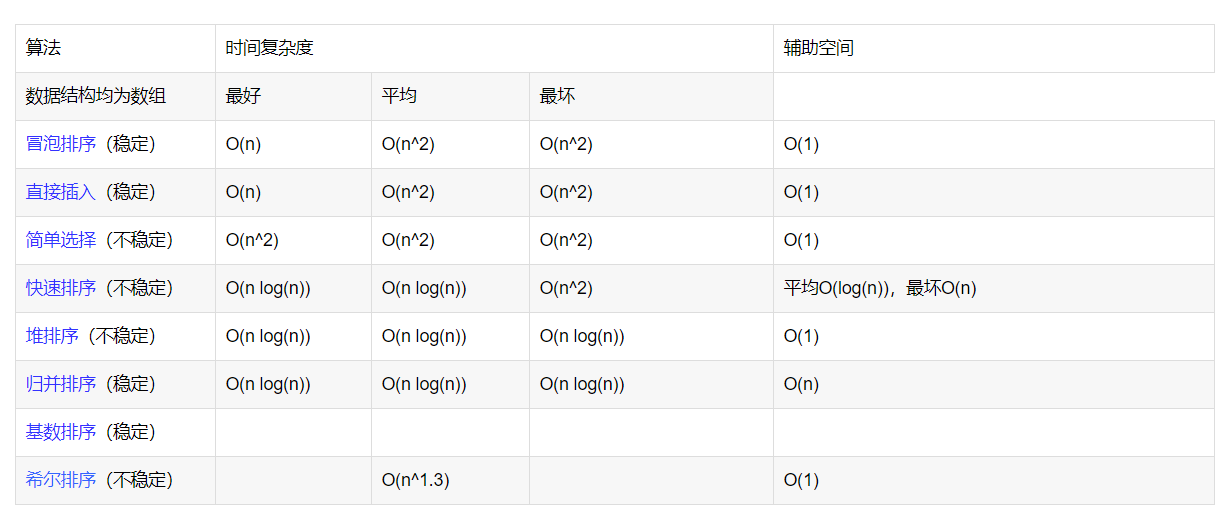
大数据排序
一、如何给100亿个数字进行排序? 1.1解答:1.把这个37GB的大文件,用哈希分成1000个小文件,每个小文件平均38MB左右(理想情况),把100亿个数字对1000取模,模出来的结果在0到999之间,每个结果对应一个文件,所以我这里取的哈希函数是hx%1000,哈希函数取得"好",能使冲突减小,结果分布均匀。2.拆分完了之后
Stella981
•
4年前
Coremail接口存配置读取漏洞POC
Coremail产品诞生于1999年,经过二十多年发展,如今从亿万级别的运营系统,到几万人的大型企业,都有了Coremail的客户。截止2019年,Coremail邮件系统产品在国内已拥有10亿终端用户 ,是目前国内拥有邮箱使用用户最多的邮件系统。Coremail今天不但为网易(126、163、yeah)、移动,联通等知名运营商提供电子邮件整体技术解决
Stella981
•
4年前
Let’s Encrypt & Certbot 浅谈
前言当我们想给网站启用HTTPS,通常需要从证书颁发机构购买证书,并配置到现有的HTTP服务上来实现HTTPS.这里暗藏的痛点是:1.我们需要花钱(买证书)2.证书颁发机构(质量参差不齐,不一定靠谱)3.需要手动添加配置(各类webserver的配置都不大一样)4.证书是会过期滴(意味我们要不断的再来
Stella981
•
4年前
DevOps 5.0版本的150天历程
转载本文需注明出处:微信公众号EAWorld,违者必究。做DevOps产品差不多三年了,中间经历了诸多架构变迁、团队变动、业务目标调整,终于在七月下旬,正式发布了DevOps产品的5.0LA版本。这个版本从三月到七月,历经大概150天,每个阶段都面临着一些痛点,在此与大家简单分享。目录:1\.写在前面:不
Stella981
•
4年前
MyBatis 源码分析
\本文速览本篇文章较为详细的介绍了MyBatis执行SQL的过程。该过程本身比较复杂,牵涉到的技术点比较多。包括但不限于Mapper接口代理类的生成、接口方法的解析、SQL语句的解析、运行时参数的绑定、查询结果自动映射、延迟加载等。本文对所列举的技术点,以及部分未列举的技术点都做了较为详细的分析。全文篇幅很大,需要大家耐
Stella981
•
4年前
S2JH新增WIKI页面:开发基础环境配置说明,基于SSH的企业Web应用开发框架
概要说明以下以我本人实际开发环境为例,简要说明开发环境配置过程,供初学者参考。当然你也完全可以根据熟悉的开发工具和环境可自行参考调整配置。本说明仅对配置过程予以说明,其中涉及到诸如Maven,Git等工具的使用相关请自行通过其他渠道了解。提示说明:以下说明和截图以自己平时使用的Ubuntu14 X64位操作系统环境,Windo
Wesley13
•
4年前
5000多张数据表,如何用SQL迁移到数据仓库?
点击关注上方“SQL数据库开发”,设为“置顶或星标”,第一时间送达干货需求背景最近公司打算集中梳理几大业务系统的数据,希望将各个业务系统中的数据集中到数据仓库中。总共有5000多张数据表,但是好在业务数据量没有像电商那么庞大,也就几十个G。需求分析其实这个需求很简单,就是把这50
Stella981
•
4年前
HTML5中对noscript标签的规定与解释
如果浏览器支持脚本,那么它不会显示出noscript元素中的文本。无法识别<script标签的浏览器会把标签的内容显示到页面上。为了避免浏览器这样做,您应当在注释标签中隐藏脚本。老式的(无法识别<script标签的)浏览器会忽略注释,这样就不会把标签的内容写到页面上,而新式的浏览器则懂得执行这些脚本,即使它们被包围在注释标签中!
1
•••
538
539
540
•••
595