
Kubernetes + GitLab 微服务应用自动化部署
Docker 简化了单个服务的部署,Kubernetes 通过强大的容器编排能力使得运维人员可以轻松管理成千上万的容器,这些容器归属于多个服务,而这些服务又组合形成了多个应用。从代码到运行中的应用,需要经历构建、打包、测试和部署等阶段,如果每个步骤都手动执行,无疑会消耗研发人员的大量时间。本文讲解如何使用 GitLab CI/CD 来自动部署微服务应用到 Kubernetes 集群。
背景
笔者最近在负责公司研发中台的建设,以提升公司整体研发效率,其中很重要的一个环节就是解决从代码到运行中服务的部署效率问题。由于公司项目众多,以前都是各个项目各自为阵,每个项目都有自己的开发、测试环境,资源利用率低,浪费严重,并且基本采用传统手动部署方式,部署效率低且容易出错。经过调研,笔者最终选择了 Kubernetes + GitLab 的组合来实现了跨项目资源复用和应自动化部署。无论是开发、测试还是生产环境,每个环境各项目都共享同一个 Kubernetes 集群,复用同一套计算和存储资源。长期没有开发活动的项目可一键从开发和测试环境里下线,以让出资源给其它活跃项目,需要的时候可快速恢复开发和测试环境。对于开发、测试环境,每个项目每天都要部署多次,如果项目采用微服务架构,那么部署次数还会随着微服务数量翻倍,因此自动化部署就显得非常必要。通过使用 GitLab CI/CD,我们做到了在开发人员提交代码后就自动触发代码构建、镜像打包并部署到 Kubernetes 集群。
Kubernetes 微服务应用部署
微服务应用部署架构
先来看一下在 Kubernetes 集群里部署微服务应用的整体架构:
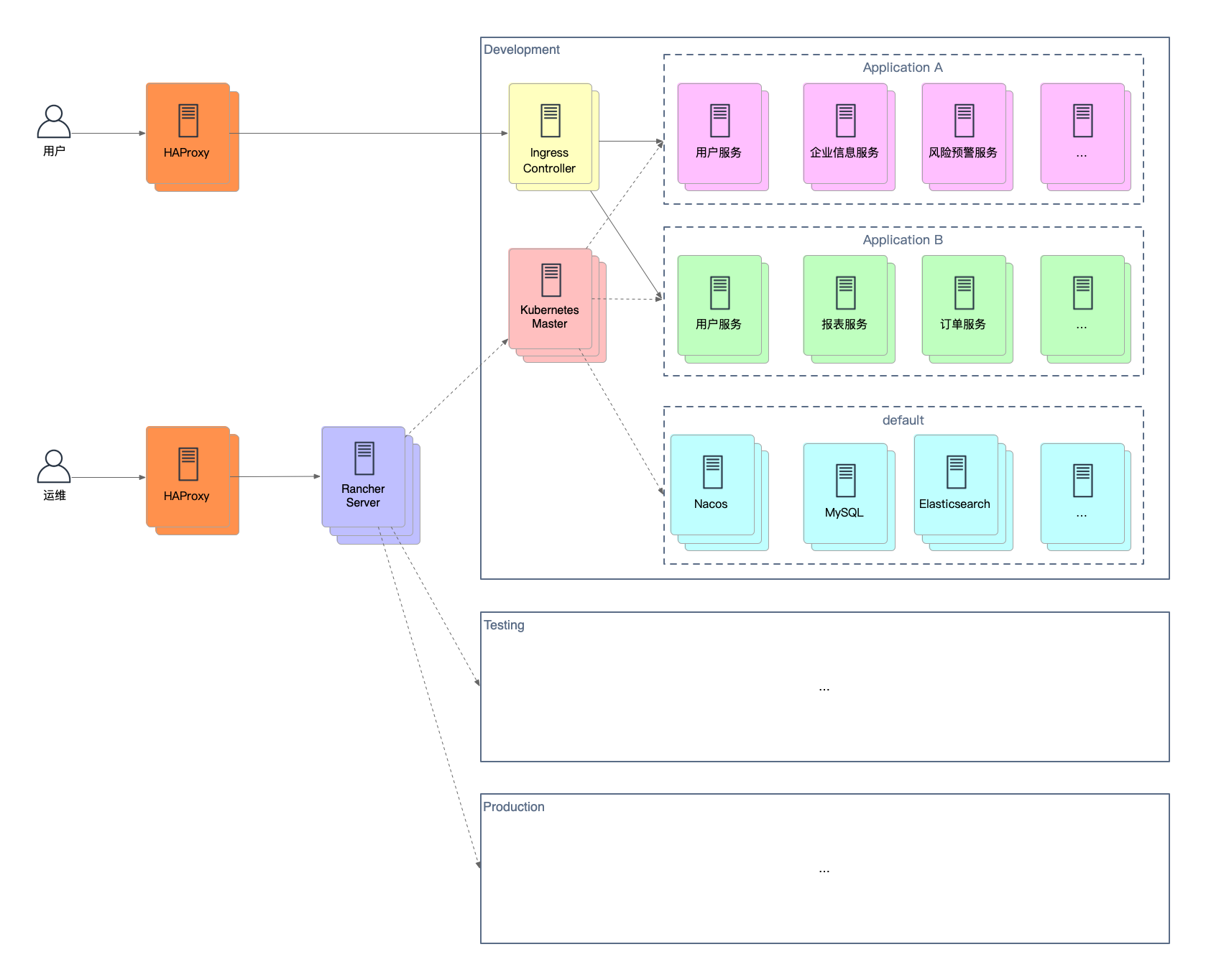
为了简化 Kubernetes 集群的管理,我们使用了 Rancher,一个企业级的 Kubernetes 多集群管理系统。无论是云服务商提供的集群,还是自建集群,均可通过 Rancher 来统一管理。如果是自建集群,还可使用 Rancher 提供的工具来快速创建。
为了实现物理上隔离,不同的环境需要使用独立的 Kubernetes 集群。各个集群在内部结构上比较类似,但会有一些细微差别,比如开发和测试环境 MySQL 是独立部署,而生产环境为了高可用会采用主从部署。各个应用公用的 MySQL、Redis、Elasticsearch 等服务放在 default 命名空间里,每个应用都有其自己的命名空间,以防止命名冲突和限制权限。对外暴露的服务需要为其创建 Ingress 对象,然后 Ingress Controller 会按照 Ingress 的指示在 Kubernetes 集群的所有 Worker 节点上将服务暴露给外部。Worker 节点一般对外不可访问,并且存在多个,为了解决外部网络访问多个 Worker 节点上的暴露服务,还需要使用 HAProxy 这样的负载均衡器来作为外部流量入口并转发请求给某个 Worker 节点。
Kubernetes 集群管理
安装 Rancher
Rancher 支持多种安装方式,最简单的就是使用 Docker 在单个节点上运行 Rancher Server,适合集群节点数量不多的场景,比如开发、测试环境。如果集群节点数量较多,建议使用一个 Kubernetes 集群来安装 Rancher 自身。这个集群可以使用 Rancher 提供的 K3S 或 RKE 工具来创建,推荐使用 K3S。K3S 是轻量级的 Kubernetes,易于安装,内存消耗只有原生 Kubernetes 的一半,所有组件打包在一个不到 50MB 的二进制文件中,适合资源较少、功能需求简单的场景。RKE 是经 CNCF 认证过的 Kubernetes 发行版,它简化了 Kubernetes 集群安装的复杂性。具体安装步骤可参考官方文档 Installing Rancher。
创建 Kubernetes 集群
Rancher 除了支持使用其 RKE 工具来创建 Kubernetes 集群,还支持 Google、Amazon、Azure、Alibaba 等云服务商,甚至还可以把现有的集群导入到 Rancher 里来管理。这里我们选择 RKE 方式,在自定义节点上创建 Kubernetes 集群。
在创建 Kubernetes 集群之前需要先准备好节点。Rancher 支持 Ubuntu、CentOS 等常见 Linux 发行版(64-bit x86,ARM64 还处于试验阶段),并且安装好 Docker,Windows 系统只能用于 Worker 节点,并且需要运行 Docker 企业版。各节点之间网络必须是连通的,如果启用了防火墙,需要开放相关端口。由于开放端口较多,建议将各节点加入同一个安全组,然后在每个节点上允许组内其它节点访问任意端口。节点角色分为 etcd、controlplane 和 worker,单个节点可具备一种或多种角色,最好只具备一种。其中 etcd 角色至少有三个节点,controlplane 和 worker 角色建议至少两个节点。
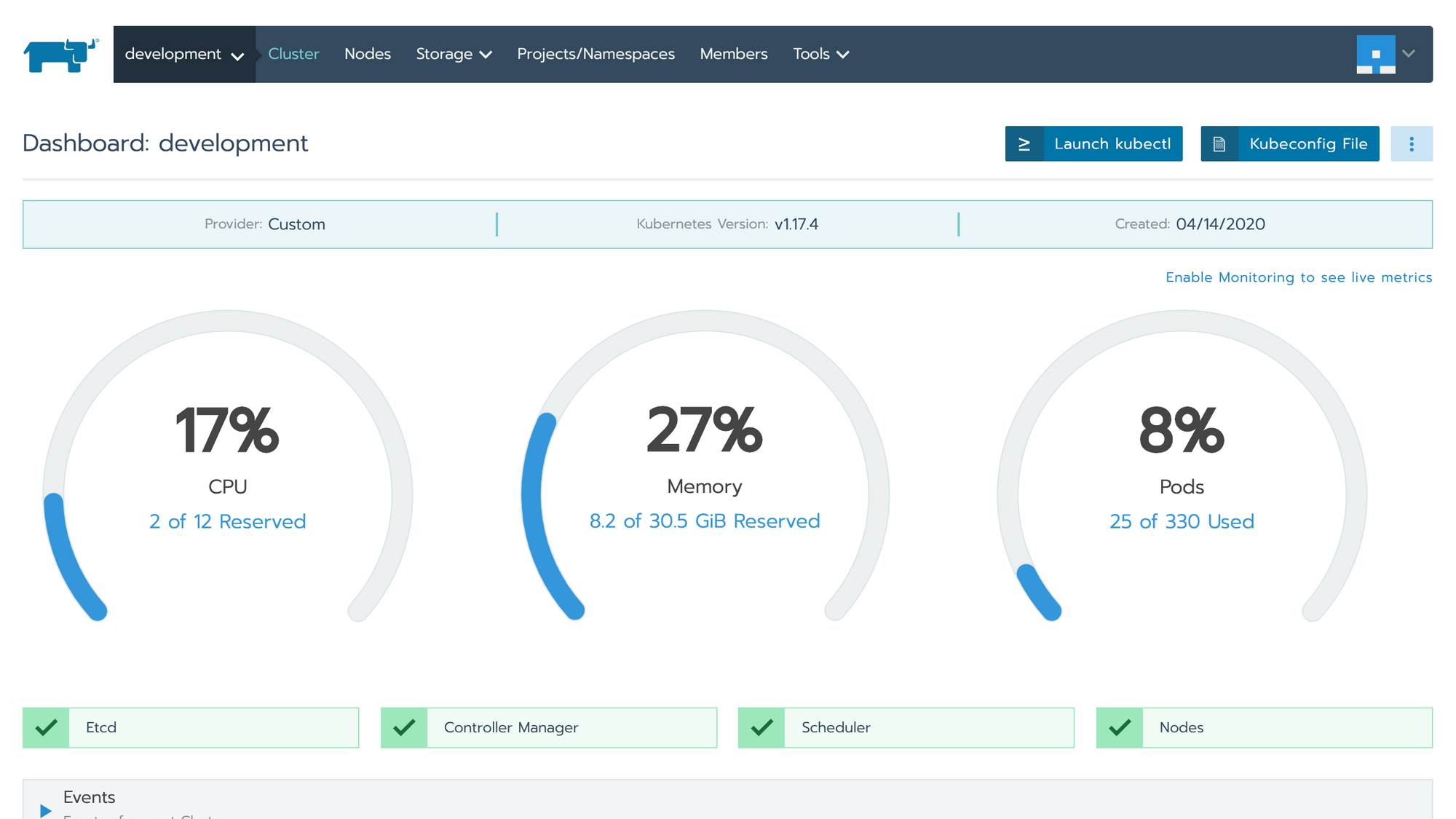
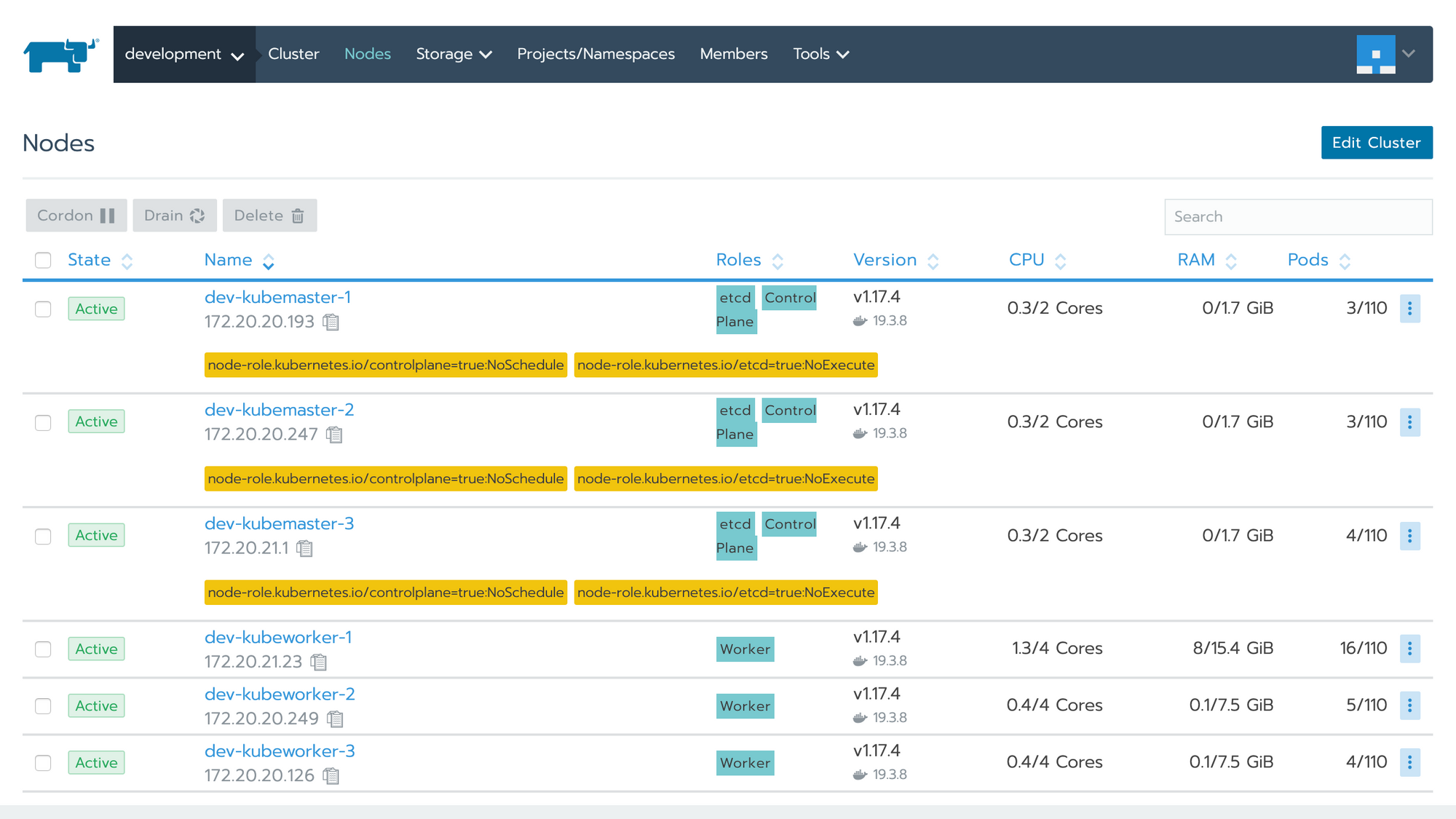
打开 Rancher UI,在 Global -> Cluster 页点击 Add Cluster 按钮来创建一个 Kubernetes 集群。首先需要填写集群名称、成员等信息,然后是添加节点。添加节点时需要先选择一到多种角色,然后拷贝页面显示的命令到节点服务器上执行,即可把该节点添加到集群里。创建完成后的集群显示如下:
安装 Rook Ceph 块存储服务
应用服务一般是无状态的,它们的状态保存在后端存储服务里,比如 MySQL、Elasticsearch 等。为了防止状态丢失,需要将服务状态持久化到存储上保存起来。传统部署方式下,计算和存储位于同一个节点,存储为本地磁盘。而在 Kubernetes 里,需要尽量避免使用节点本地存储,因为这样 Pod 会绑定到特定的节点,导致其无法在不同节点之间进行调度。Kubernetes 通过 PV(Persistent Volume)和 StorageClass 来抽象 Pod 对存储资源的需求。PV 可以使用手动方式预先创建好,也可以通过 StorageClass 来按需动态创建。PV 可以来源于节点本地路径、节点本地磁盘或者云服务商提供的块存储服务,如前所述应尽量避免使用本地存储。为了解决非云服务商环境里的 Kubernetes 集群的存储问题,我们可以选择一些开源方案来在 Kubernetes 集群内提供块存储服务。这里推荐两个,一个是 Rancher 发起的 Longhorn,另外一个是出现得更早的 Rook。相比而言,Rook 要比 Longhorn 更成熟一些,因为其底层使用了 Ceph(也支持其它块存储驱动,不过 Ceph 最为成熟),因此我们选择了 Rook。除了提供块存储服务,Rook Ceph 还能够提供对象存储服务(OSS)和共享文件系统服务(Shared Filesystem)。
在 Kubernetes 集群里安装 Rook Ceph 块存储服务的步骤如下,更多内容可参考官方文档 Ceph Storage Quickstart。
# 克隆代码
git clone --single-branch --branch v1.4.6 https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph
# 创建 Rook CRD 和 Operator
kubectl create -f common.yaml
kubectl create -f operator.yaml
# 确认 rook-ceph-operator 处于 `Running` 状态后再继续后续操作
kubectl -n rook-ceph get pod
# 创建一个 Rook Ceph 存储集群
kubectl create -f cluster.yaml Rook 会使用所有 Worker 节点来创建一个 Ceph 集群,其存储资源包含所有节点上的所有 Raw 设备(没有分区或文件系统)和 Raw 分区(没有文件系统)。
为了方便日后查看和管理 Ceph 集群,建议安装 Rook 提供的 Toolbox,然后可进入 rook-ceph-tools 容器执行各种操作。
# 安装 Toolbox
$ kubectl create -f toolbox.yaml
# 进入 `rook-ceph-tools` 容器,查看 Ceph 集群状态
$ ceph status
cluster:
id: 09ee35d4-2ed2-4c33-b819-50c025a2c59d
health: HEALTH_WARN
mons a,d are low on available space
services:
mon: 3 daemons, quorum a,b,d (age 23h)
mgr: a(active, since 9d)
osd: 6 osds: 6 up (since 3d), 6 in (since 2w)
data:
pools: 2 pools, 33 pgs
objects: 10.99k objects, 42 GiB
usage: 131 GiB used, 2.8 TiB / 2.9 TiB avail
pgs: 33 active+clean
io:
client: 84 KiB/s wr, 0 op/s rd, 3 op/s wr 此外 Ceph 本身也提供了 Dashboard 来方便浏览集群状态,这个 Dashboard 在安装 Ceph 集群的时候已安装好,只需通过 Ingress 对象对外暴露即可。
# 注意先修改 YAML 文件中的域名为自己的,该域名指向 Worker 节点(如有多个可使用 HAProxy 这样的负载均衡器)
kubectl create -f dashboard-ingress-https.yaml 然后在浏览器里打开 Dashboard Ingress 里配置的域名,即可访问 Ceph Dashboard。

前面只是安装好了 Rook Ceph 集群,为了在 Kubernetes Workloads 里使用 Ceph 集群的存储资源,还需要创建 StorageClass。
# 创建一个三副本的存储池 CephBlockPool,以及可从该存储池获取资源的 StorageClass
kubectl create -f csi/rbd/storageclass.yaml 创建好的 StorageClass 名为 rook-ceph-block,然后就可以创建 PVC(PersistentVolumeClaim) 来申请存储资源了。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi 部署公共服务
一个应用里除了实现业务逻辑的微服务,还有一些非业务的公共服务,比如数据库、缓存、消息队列、搜索等服务。这些服务跟具体业务无关,可以在多个应用之间共享,但要注意从命名空间上跟应用进行隔离。下面以 MySQL 服务为例:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: registry.prod.bbdops.com/common/mysql:8.0.20
name: mysql
env:
- name: TZ
value: Asia/Shanghai
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql
key: root-password
resources:
requests:
memory: 400Mi
cpu: 0.1
limits:
memory: 4Gi
cpu: 1
ports:
- containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: data
volumes:
- name: data
persistentVolumeClaim:
claimName: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql 上面的 YAML 文件创建了一个名为 mysql 的 MySQL 服务,假设其位于 default 命名空间,其它命名空间里的应用可通过 mysql.default 主机名来访问。
部署和暴露微服务
应用微服务一般没有状态,不需要创建 PVC 对象和挂载 PV,因此其部署比较简单,这里就不举具体例子了。如果某个微服务需要对外暴露,需要为其创建 Ingress 对象。对于有使用网关的微服务架构应用,只需要暴露其网关服务即可,其它微服务可通过网关代理访问,这样可避免创建过多 Ingress 对象。
通过 Nginx Ingress Controller 暴露的服务统一通过 Worker 节点上的 Nginx 来代理访问,如果 Worker 节点对外不可见或者有多个,那么还需在负载均衡器上配置转发。这里以 HAProxy 四层负载均衡为例:
...
listen kubernetes-nginx
mode tcp
balance roundrobin
# nginx
bind *:80
bind *:443
server dev-kubeworker-1 dev-kubeworker-1 check
server dev-kubeworker-2 dev-kubeworker-2 check
server dev-kubeworker-3 dev-kubeworker-3 check
... 本地开发环境访问 Kubernetes 开发集群服务
微服务架构虽然有很多好处,但同时也会造成一些麻烦,其中一个就是会增加开发人员搭建本地开发环境的难度。为了开发和调试一个微服务,需要同时启动一堆依赖的微服务和数据库、缓存等公共服务。为了简化本地开发环境搭建,可以让本地正在开发的微服务直接访问 Kubernetes 集群里的服务,这样本地只需启动正在开发中的服务。
前面已学会如何使用 Ingress 对象来暴露 HTTP 服务,如果是 MySQL 这样的 TCP 服务,Nginx Ingress Controller 也是支持的。只需要在 Nginx Ingress Controller 所在命名空间 ingress-nginx 里创建如下的 ConfigMap 对象即可:
apiVersion: v1
kind: ConfigMap
metadata:
name: tcp-services
data:
3306: "default/mysql:3306" Nginx Ingress Controller 会在每个 Worker 节点上启动一个 hostNetwork 类型的 Pod,这样 Pod 直接使用宿主机网络,其监听端口在宿主机上可访问,比如可以通过访问 Worker 节点的 3306 端口来访问 MySQL 服务。如果 Worker 节点对外不可见或者有多个,同样可以在 HAProxy 负载均衡器上配置转发:
...
listen kubernetes-tcp
mode tcp
balance roundrobin
# mysql
bind *:3306
server dev-kubeworker-1 dev-kubeworker-1 check
server dev-kubeworker-2 dev-kubeworker-2 check
server dev-kubeworker-3 dev-kubeworker-3 check
... 应用微服务也可以采取类似的方式来暴露,为了减少配置 Nginx Ingress Controller,可在部署微服务时直接为其创建一个 NodePort 类型的服务。
apiVersion: v1
kind: Service
metadata:
name: user
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30010
selector:
app: user 如果使用了 HAProxy,则同样需要配置端口转发。如果应用有多个微服务需要暴露,可为其分配一个端口范围(比如 30010-30019),然后利用 HAProxy 的端口范围转发来减少配置工作。
...
# app1
bind *:30010-30019
... GitLab CI/CD
介绍
GitLab 从开源 SCM(Source Code Management)开始,但很快发展成为完整的 DevOps 解决方案,提供的功能包括项目管理、私有容器注册和构建环境(包括 Kubernetes)。GitLab CI/CD 由 GitLab Runner 驱动,在自包含的环境中执行 CI/CD 流水线中的每个步骤。可以通过 gitlab-ci.yml 清单完成 CI/CD 配置,该清单支持一些高级配置,包括逻辑条件运算和导入其他清单,或者使用 Auto DevOps,无需配置即可自动创建流水线。
创建 Runner
为了能够执行流水线中的任务(Job),需要先创建至少一个 Runner。Runner 可以是所有项目共享的(Shared),也可以为某个组(Group)或某个项目(Project)创建。
首先,在要运行 Runner 的机器上安装 gitlab-runner 工具,支持多种方式,推荐 Repositories 方式,具体可参考 Install GitLab Runner。
其次,为所有项目,或某个组,或某个项目创建一个 Runner,创建前请在系统、组或项目的 Settings -> CI/CD 页里获取授权 Token。Runner 的类型可以是 shell、docker、kubernetes 等。其中 shell 类型直接在本地运行构建任务,配置简单并且容易实现构建缓存,docker 类型在本地启动容器来运行构建任务,隔离性好但实现构建缓存比较麻烦,性能上也较差,推荐更简单易用的 shell 类型。
配置流水线(Pipeline)
下面我们以自动构建和部署一个 Java Spring Boot 服务为例来讲解如何配置流水线。在项目根目录下创建一个名为 .gitlab-ci.yml 的文件,内容如下(每个任务的具体内容后面会讲到):
stages:
- build
- package
- deploy
maven-build:
...
docker-build:
...
.kubernetes-deploy:
...
kubernetes-deploy-development:
...
kubernetes-deploy-testing:
...
kubernetes-deploy-production:
... 其中 stages 定义本流水线将顺序执行 build(构建)、package(打包) 和 deploy(部署) 三个阶段(Stage),每个阶段可并行执行多个任务(Job)。
在流水线配置文件中可通过 $ 来引用变量,变量名通常为大写,单词之间以 _ 分隔。变量可在流水线中通过 variables 指令来定义,也可在组或项目的 Settings -> CI/CD 页里定义,这样就不用暴露在配置文件中。GitLab 预定义了许多环境变量,具体可查阅 Predefined environment variables reference。
构建
maven-build:
stage: build
tags:
- java
variables:
MAVEN_OPTS: "-Dmaven.test.skip=true"
MAVEN_CLI_OPTS: "-s .m2/settings.xml --batch-mode"
script:
- mvn $MAVEN_CLI_OPTS package
artifacts:
paths:
- target/*.jar 任务 maven-build 属于阶段 build,它使用 maven 镜像来编译 Java 代码并打包为 Jar 包。
打包
docker-build:
stage: package
tags:
- java
variables:
DOCKER_IMAGE_NAME: registry.prod.bbdops.com/canghai/user
script:
- docker build -t $DOCKER_IMAGE_NAME:$CI_COMMIT_SHORT_SHA -t $DOCKER_IMAGE_NAME:$CI_COMMIT_REF_NAME -t $DOCKER_IMAGE_NAME:latest .
- docker push $DOCKER_IMAGE_NAME:$CI_COMMIT_SHORT_SHA
- docker push $DOCKER_IMAGE_NAME:$CI_COMMIT_REF_NAME
- docker push $DOCKER_IMAGE_NAME:latest 任务 docker-build 属于阶段 package,它负责将构建阶段得到的 Jar 包打包为 Docker 镜像。Docker 镜像构建所用的 Dockerfile 位于项目根目录下,内容如下:
FROM openjdk:8u252
ENV TZ Asia/Shanghai
WORKDIR /app
ADD target/user-1.0-SNAPSHOT.jar app.jar
EXPOSE 8080
CMD ["java", "-Djava.security.egd=file:/dev/./urandom", "-jar", "app.jar"] 部署
.kubernetes-deploy:
stage: deploy
tags:
- java
before_script:
- sed -i 's/$CI_COMMIT_SHORT_SHA/'"$CI_COMMIT_SHORT_SHA"'/' deployment.yml
kubernetes-deploy-development:
extends: .kubernetes-deploy
only:
refs:
- dev
script:
- sed -i 's/$SPRING_PROFILES_ACTIVE/dev/' deployment.yml
- kubectl apply -f deployment.yml -n canghai --kubeconfig=$HOME/.kube/development-config.yml
kubernetes-deploy-testing:
extends: .kubernetes-deploy
only:
refs:
- test
script:
- sed -i 's/$SPRING_PROFILES_ACTIVE/test/' deployment.yml
- kubectl apply -f deployment.yml -n canghai --kubeconfig=$HOME/.kube/testing-config.yml
kubernetes-deploy-production:
extends: .kubernetes-deploy
only:
refs:
- master
when: manual
script:
- sed -i 's/$SPRING_PROFILES_ACTIVE/prod/' deployment.yml
- kubectl apply -f deployment.yml -n canghai --kubeconfig=$HOME/.kube/production-config.yml 部署阶段包含三个任务,不过三个任务同时只会执行其中一个,根据当前提交代码的分支来决定要执行哪一个,从而部署到对应的 Kubernetes 集群。隐藏任务 .kubernetes-deploy 将三个任务的公共部分提取了出来,以避免重复。Kubernetes 部署文件 deployment.yml 的内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: user
spec:
replicas: 1
selector:
matchLabels:
app: user
template:
metadata:
labels:
app: user
spec:
imagePullSecrets:
- name: bbd-docker-registry
containers:
- image: registry.prod.bbdops.com/canghai/user:$CI_COMMIT_SHORT_SHA
name: user
env:
- name: spring.profiles.active
value: $SPRING_PROFILES_ACTIVE
- name: eureka.instance.hostname
value: user
resources:
requests:
memory: 200Mi
cpu: 0.1
limits:
memory: 2Gi
cpu: 1
ports:
- containerPort: 8080
name: user
---
apiVersion: v1
kind: Service
metadata:
name: user
spec:
ports:
- port: 8080
selector:
app: user 其中用到了 GitLab 预定义的环境变量 CI_COMMIT_SHORT_SHA,这里需要我们自己使用 sed 命令来替换为对应的变量值,只有 GitLab CI 配置文件里的变量才会自动替换。如果是私有 Registry,还需创建存放访问 Registry 的帐号密码的 Kubernetes Secret 对象 bbd-docker-registry,否则拉取镜像会失败。
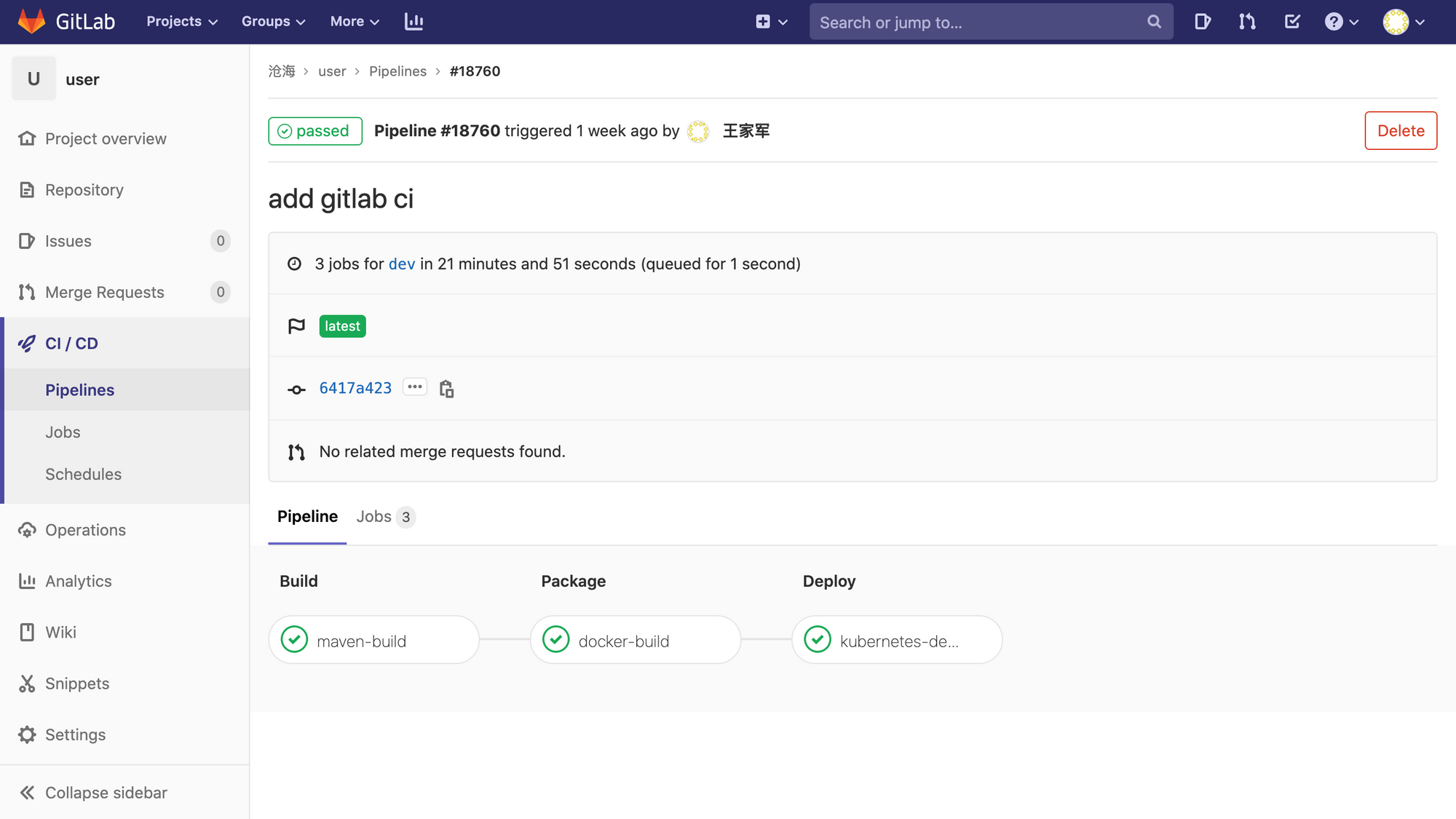
至此,GitLab 流水线就配置完成,下面是其实际执行效果:

本文转自 https://blog.jaggerwang.net/kubernetes-gitlab-microservice-application-auto-deploy/,如有侵权,请联系删除。












