推荐
专栏
教程
课程
飞鹅
本次共找到1165条
百度搜索
相关的信息
Stella981
•
4年前
Discuz如何自主控制弹框的显示
本文实现功能:控制弹框的显示与否功能使用场景在之前的一篇文章写道,discuz实现自动注册登录。但是我们又不想让那个提示信息出来。在网上大概的搜索了一下,有的说后台可以设置,但是咔咔到后边瞅了一眼,它那个设置只是针对于固定的一些场景。那么我们自己可以来写一个适合我们项目的显示方式弹框实现剖析
Stella981
•
4年前
Hadoop云计算的初步认识
在说Hadoop之前,作为一个铁杆粉丝先粉一下Google。Google的伟大之处不仅在于它建立了一个强悍的搜索引擎,它还创造了几项革命性的技术:GFS,MapReduce,BigTable,即所谓的Google三驾马车。Google虽然没有公布这几项技术的实现代码,但它发表了详细的设计论文,这给业界带来了新鲜气息,很快就出现了类似于Google三驾马车的开
胖大海
•
3年前
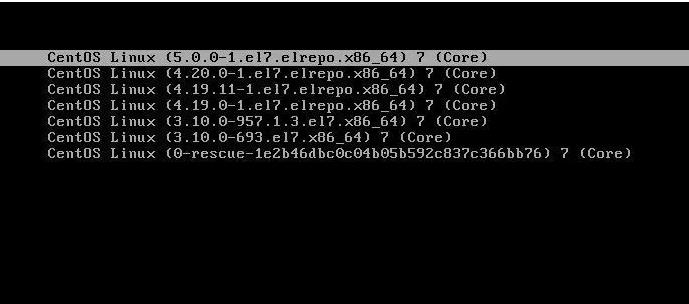
Linux centos7 删除多余内核
Linux下可能会存在有多个内核的情况,通过某一内核启动会出现无法登录的情况,这时我们就要选择可以正常登录的内核,成功进入系统后,将多余的内核删除。检查系统中的内核 使用yumremove或rpme删除无用内核 然后可以继续搜索验证一下这样多余的内核就删除了,千万一定要注意删错了系统就打不开了,如果大家缺乏机器练手的话可以去3A服务器看看!
小白学大数据
•
2年前
python如何分布式和高并发爬取电商数据
随着互联网的发展和数据量的不断增加,网络爬虫已经成为了一项非常重要的工作。爬虫技术可以帮助人们自动地从互联网上获取大量数据,并且这些数据可以应用于各种领域,如搜索引擎、数据分析和预测等。然而,在实际应用中,我们面临的一大难题就是如何高效地爬取大量数据。分布
菜园前端
•
2年前
什么是分而治之?
原文链接:什么是分而治之?在我们前面有学习过一系列数据结构、以及相关的一些算法,包含排序、搜索算法。而本次学习的分而治之它不是数据结构,也不是一种算法,而是算法设计中的一种方法,可以理解为是一种思想。我们可以利用这种思想去设计很多种算法。分而治之是将一个问
不是海碗
•
2年前
通用文字识别OCR 之实现自动化办公
随着技术的发展,通用文字识别(OCR)已经成为现代办公环境中不可或缺的工具之一。OCR技术可以将印刷或手写文本转换为可编辑或可搜索的数字文本,极大地提高了办公效率并实现了自动化办公。本文将深入探讨OCR技术在实现自动化办公方面的应用,包括文档处理、数据提取、自动化填表等方面的实例。
绣鸾
•
2年前
Paste 4 for Mac(剪切板管理工具)
是一款专门为剪切板管理而设计的应用程序。它旨在帮助用户更有效地管理剪切板内容并提高工作效率。Paste可以自动记录您复制或剪切的内容,并将其存储在应用程序内。它提供了一个直观的界面,让您可以轻松浏览、搜索和访问剪贴内容的历史记录。您可以使用Paste来复制
程序员小五
•
1年前
融云IM干货丨【 IM 服务】为什么聊天室自动销毁了?怎样能让聊天室一直存在?
聊天室自动销毁的原因通常与设置的自动销毁机制有关。根据搜索结果,聊天室具有自动销毁机制,如果聊天室在指定时间内(默认1个小时)没有人说话,且没有人加入聊天室时,服务端会把聊天室内所有成员踢出聊天室并销毁聊天室。这种“不活跃”是指连续时间段内无成员进出且无新
京东云开发者
•
1年前
「零售数据通道」数据炼金术:千亿级流量资产湖仓架构转型
作者:京东零售陈美航0前言在流量领域的转化分析、搜索推广算法及AI等数据分析应用场景中,流量资产的质量直接影响到业务的监测和运营。作为流量资产的基石,流量数仓在应对快速变化和多样化的业务需求时,如何在提高效率、优化用户体验和控制成本方面做到最佳?本文将方案
京东云开发者
•
5个月前
让大模型更懂用户,算法工程师的成长升级之旅
在京东,技术从不是冰冷的代码,而是连接消费者与美好生活的桥梁。在京东零售,我用大模型赋能智能导购、搜索等电商场景,工作期间发表4篇顶会论文,提交专利8篇,并入选北京亦麒麟优秀人才。这些写进顶会论文的技术突破、藏在专利证书里的创新方案,都化作了消费者指尖上的
1
•••
100
101
102
•••
117