推荐
专栏
教程
课程
飞鹅
本次共找到2692条
环境
相关的信息
芝士年糕
•
3年前
关于windows杀死某个端口号进程的方法
背景有些时候我们需要强制杀死某个端口号的进程,以释放被占用的端口号,那么我们可以通过以下方法处理。环境:3A服务器搭建的windows系统步骤1:打开终端winr的方式,打卡运行框,输入cmd按下回车,打开终端步骤2:查找被占用的端口号的pid号比如我们要查找8080端口的pid号,那么在终端中输入netstatano|findstr8080,找到
Wesley13
•
4年前
Redis集群原理、搭建
在实际的生产过程中,单服的redis存在单点的问题,redis通常需要集群的环境。相比单服的redis,集群有以下些好处:1.容错性解决在单服redis的单点问题。在一个或多个节点出现宕机的情况下,集群内部通过投票的机制能够快速的进行选举和不停机的情况下进行服务持续提供。2.扩展性相比单
Aidan075
•
4年前
Jupyter Notebook最强指南,没有之一
(文末有福利)Python语言是一种强大而简洁的编程语言。据IEEESpectrum消息,Python在2020年继续蝉联最受欢迎的编程语言第一名。对于刚接触Python的新手来说,配置一个容易上手又适合自己的开发环境无疑是成功掌握这门编程语言的第一步。对于PythonIDE的比较和推荐,各路高手也说法不同,其中被推荐频率最高的当属Pycharm、V
桃浪十七丶
•
4年前
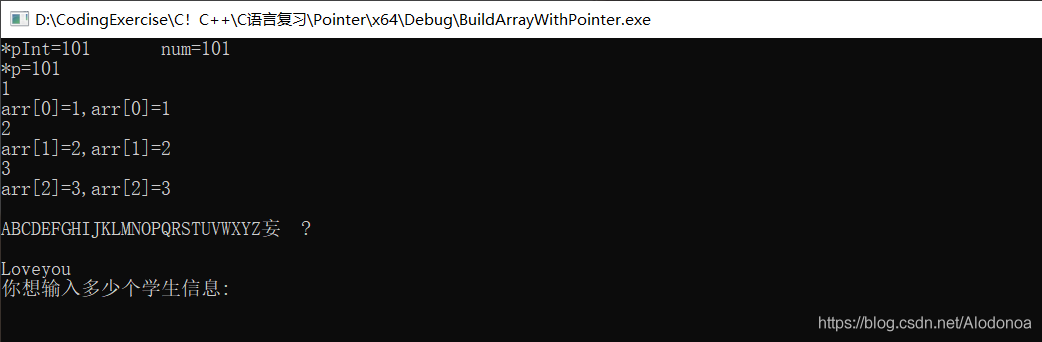
C语言中指针及其应用高级篇(用指针实现数组的扩增)
一、一级指针与一维数组把指针充当变量的用法,在C/C的数据结构学习中广为应用,这种用法学习起来是比较简单的。先看代码。这里的代码,有string.h头文件包含的函数,和scanf,这两者在正常的写法中不用加“s”,这篇随笔所及代码的运行环境是VisualStudio2017,编译器会把scanf等函数增强,因此为了正常运行,会加上“s”.cdefine
Wesley13
•
4年前
vsan的容量设备故障和缓存设备故障分析
容量设备故障解析:磁盘故障可能是任何存储环境中最常见的故障了,vsan也不例外。磁盘组是vSAN的管理结构,其中包括一个缓存设备和一个或多个容量设备,其容量设备的磁盘多为SATA盘。一台主机可以为VSAN提供最多5个磁盘组:每个磁盘组需要1个SDD以及最少1个、最多6个HDD。每个主机的最多HDD数为5x630。每个
Stella981
•
4年前
RabbitMQ 消息中间件搭建详解
1.RabbitMQ简介消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包
Wesley13
•
4年前
SGX 侧信道攻击综述
IntelSGX技术是一种新的基于硬件的可信计算技术。该技术通过CPU的安全扩展,对用户空间运行环境(enclave)提供机密性和完整性保护。即使是攻击者获得OS,hypervisor,BIOS和SMM等权限,也无法直接攻击enclave。因此,攻击者不得不通过侧信道的攻击方法来间接获取数据(比如隐私数据,加密密钥等等)。得益于enclave的强安
Wesley13
•
4年前
Oracle审计--AUD$占用空间较大处理方案
Oracle11G以后,数据库默认是开启审计功能的,因此有时候我们忘记了关闭该功能导致SYSTEM表空间暴满,但由于关闭审计功能需要重启数据库,此类操作生产环境下是不允许的,因此我们需要找出哪类审计产生的较多,然后单独的进行关闭;我们可以通过如下方法查找:如果你发现AUD$这个表比较大了,检查下是哪种审计占的空间:SQLselectact
Wesley13
•
4年前
MySQL Cluster实现SQL&NoSQL组合使用
在MySQLCluster集群,应用数据均保存在数据节点。因此不仅MySQL实例可以对其进行访问,通过NDB的API其他应用也可以访问数据。 利用这个特性,开发者可以实现以下功能:1.进行跨应用的复杂查询2.简单的Key/Value绕过SQL层实现快速读写3.微秒级的实时响应利用以上功能,通过灵活配置应用环境,可提高生产效率和灵活性,在不改动数据库结
天翼云开发者社区
•
2年前
切实保障用户权益!天翼云加入“云服务用户权益护航计划”
今天是一年一度的315国际消费者权益日,该节日的设立旨在提醒人们关注消费者权益问题,促进公平、公正、透明的市场环境,保护消费者的合法权益。始终高度重视消费者权益保护,致力为用户提供安全可靠的上云服务。近日,由中国信息通信研究院与中国通信标准化协会联合主办的
1
•••
239
240
241
•••
270