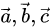推荐
专栏
教程
课程
飞鹅
本次共找到301条
物理数据模型
相关的信息
Karen110
•
4年前
人工智能数学基础-线性代数1:向量的定义及向量加减法
一、向量1.1、向量定义向量也称为欧几里得向量、几何向量、矢量,指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量对应的量叫做数量(物理学中称标量),数量(或标量)只有大小,没有方向。1.在物理学和工程学中,几何向量更常被称为矢量。2.一般印刷用黑体的小写
亚瑟
•
4年前
云原生监控系统 Prometheus 入门
Prometheus介绍主要特性之所以Prometheus现在这么受欢迎,主要是因为它具备如下特性:多维度数据模型灵活的查询语言不依赖任何分布式存储常见方式是通过拉取方式采集数据也可通过中间网关支持推送方式采集数据通过服务发现或者静态配置来发现监控目标支持多
kelly
•
4年前
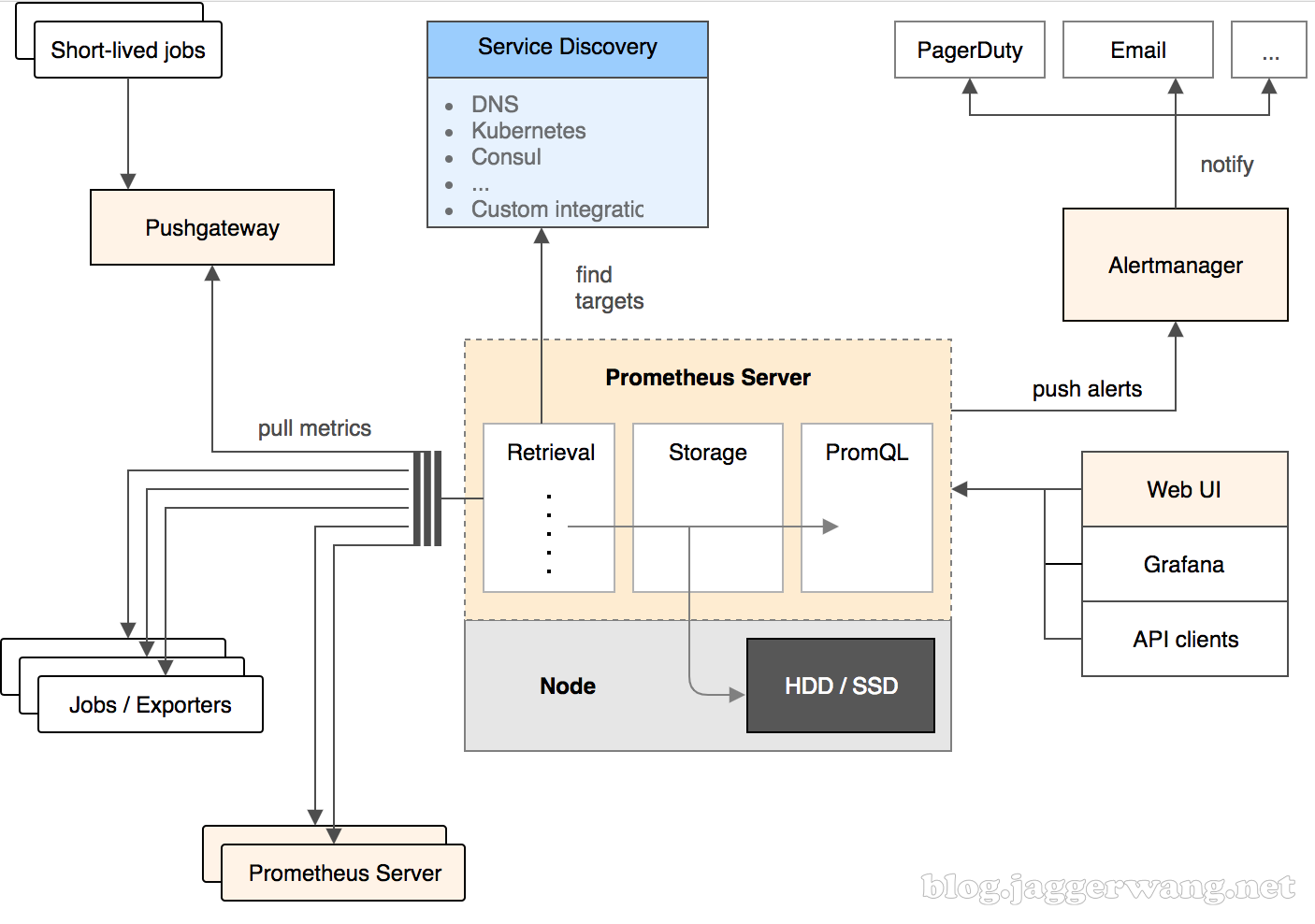
磁盘读写与数据库的关系
一磁盘物理结构(1)盘片:硬盘的盘体由多个盘片叠在一起构成。(https://imghelloworld.osscnbeijing.aliyuncs.com/ca8257beee4683c9331279708f8136d1.
Stella981
•
4年前
Linux服务器性能查看分析调优
转自https://www.cnblogs.com/acelee/p/6628079.html一linux服务器性能查看1.1cpu性能查看1、查看物理cpu个数:cat/proc/cpuinfo|grep"physicalid"|sort|un
Stella981
•
4年前
GraphQL 使用介绍
!(https://oscimg.oschina.net/oscnet/9d854df9aa4e01f403bbb6ae4c9da2afbdf.jpg)GraphQL是Fackbook的一个开源项目,它定义了一种查询语言,用于描述客户端与服务端交互时的数据模型和功能,相比RESTfulAPI主要有以下特点:根据需要返回数据
Stella981
•
4年前
Kafka 和 DistributedLog 技术对比
因为两者都是处理日志,数据模型也类似,所以这篇文章主要从技术角度讨论ApacheKafka与DistributedLog的不同点。我们会尽量做到客观,但由于我们不是ApacheKafka的专家,因此我们可能会对ApacheKafka存在误解。如果发现有错,也请大家直接指出。首先,让我们简单地介绍一下Kafka和Distribu
Stella981
•
4年前
MongoDB索引存储BTree与LSM树(转载)
1、为什么MongoDB使用B树,而不是B树MongoDB是一种nosql,也存储在磁盘上,被设计用在数据模型简单,性能要求高的场合。性能要求高,我们看B树与B树的区别:_B树内节点不存储数据,所有data存储在叶节点导致查询时间复杂度固定为logn。
Wesley13
•
4年前
IOTA架构下的数据采集
!(https://oscimg.oschina.net/oscnet/up8a9d22568bf3799937776d063b2635bf708.JPEG)导读IOTA架构是基于IOTA和AI时代背景下的大数据架构模式,其整体技术结构的核心是贯穿于整体业务始终的数据模型,具有提高整体的预算效率的作用。IOTA架构这一概念由易观首次提出,并
Wesley13
•
4年前
MySQL关于用户关注粉丝表的设计方案
一、数据结构分析用户关注粉丝是一个多对多的数据模型,分析对象的数据特征,我们给每个用户设计一个关注者属性和粉丝属性,用于存储用户的关注者id和粉丝id,如用户1:$arr1\'follow''\2,3,4\,'fans'\4,5,6\,\二、用户逻辑关系梳理
taskbuilder
•
1年前
TaskBuilder内设置任擎服务器
TaskBuilder内设置任擎服务器在使用TaskBuilder进行软件开发时,必须要先连接到任擎服务器(后续文档所说的服务器如果不特别注明,皆指任擎服务器)才能继续操作,因为使用TaskBuilder开发所需的数据模型、后台服务和前端页面等文件都存放在
1
•••
9
10
11
•••
31