推荐
专栏
教程
课程
飞鹅
本次共找到1350条
概念数据模型
相关的信息
Wesley13
•
4年前
java的可变参数
Java方法中的可变参数类型是一个非常重要的概念,有着非常广泛的应用,今天小编带大家一起去深入的了解java的可变参数使用方式!01、什么是可变参数在Java5中提供了变长参数(varargs),也就是在方法定义中可以使用个数不确定的参数。使用...表示可变长参数,例如1.p
Stella981
•
4年前
Fabric链码开发的8个原则
我相信智能合约(链码)是HyperledgerFabric区块链网络的核心。正确开发链码可以真正发挥一个安全区块链的优势,反之则会带来灾难性的后果。在这篇文章里我不打算探讨HyperledgerFabric链码设计的特定模式的好与坏,而是希望分享我在开发若干HyperledgerFabric概念验证应用过程中总结的一些基本准则。Hyperled
Stella981
•
4年前
Javascript 中的神器——Promise
_摘要:_ 回调函数真正的问题在于他剥夺了我们使用return和throw这些关键字的能力。而Promise很好地解决了这一切回调函数真正的问题在于他剥夺了我们使用return和throw这些关键字的能力。而Promise很好地解决了这一切Promise概念所谓Promise,就是ES6原生提供的一个
Wesley13
•
4年前
MySQL数据库8(二十一)事务
事务安全事务概念l Transactionl 事务:一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务(例如银行账户转账业务,该业务就是一个最小的工作单元)l 一个完整的业务需要批量的DML(insert、update、delete)语句共同联合完成l 事务只和DML语句有关,或者说DML语句才有事务
Wesley13
•
4年前
HTTP第一篇【简单了解HTTP、与HTTP相关的协议】
为什么要学HTTP?我们绝大多数的Web应用都是基于HTTP来进行开发的。我们对Web的操作都是通过HTTP协议来进行传输数据的。HTTP的诞生主要是为了能够让文档之间相互关联,形成超文本可以互相传阅可以说,Http就是Web通信的基础,这是我们必学的。Http基础概念我们学计算机网络的时候
Wesley13
•
4年前
JAVA中的栈和堆【转】
原文链接 https://www.cnblogs.com/ibelieve618/p/6380328.htmlJAVA在程序运行时,在内存中划分5片空间进行数据的存储。分别是:1:寄存器。2:本地方法区。3:方法区。4:栈。5:堆。基本,栈stack和堆heap这两个概念很重要,不了解清楚,后面就不用学了。以下是这几天栈和堆的学习记录和心得。得
Stella981
•
4年前
Shell脚本编程——基础篇
Shell脚本概念1、将要执行的命令按顺序保存到一个文本文件2、给该文件可执行权限,便可运行3、可结合各种shell控制语句以完成更复杂的操作Shell脚本应用场景1、重复性操作2、批量事务处理3、自动化运维4、服务运行状态监控5、定时任务执行完善的shell脚本
Easter79
•
4年前
Subversion
第 1 章 基本概念记住Subversion可以管理任何类型的文件集—它并非是程序员专用的。版本库是Subversion的核心部分,是数据的中央仓库。Subversion是一个“集中式”的信息共享系统.版本库以典型的文件和目录结构形式 _文件系统树_来保存信息。Subversion听起来和一般的文件服务器
Wesley13
•
4年前
Java 多线程:volatile关键字
概念volatile也是多线程的解决方案之一。\\volatile能够保证可见性,但是不能保证原子性。\\它只能作用于变量,不能作用于方法。当一个变量被声明为volatile的时候,任何对该变量的读写都会绕过高速缓存,直接读取主内存的变量的值。如何理解直接读写主内存的值:回到多线程生成的原因(Java内存模型与
天翼云开发者社区
•
3年前
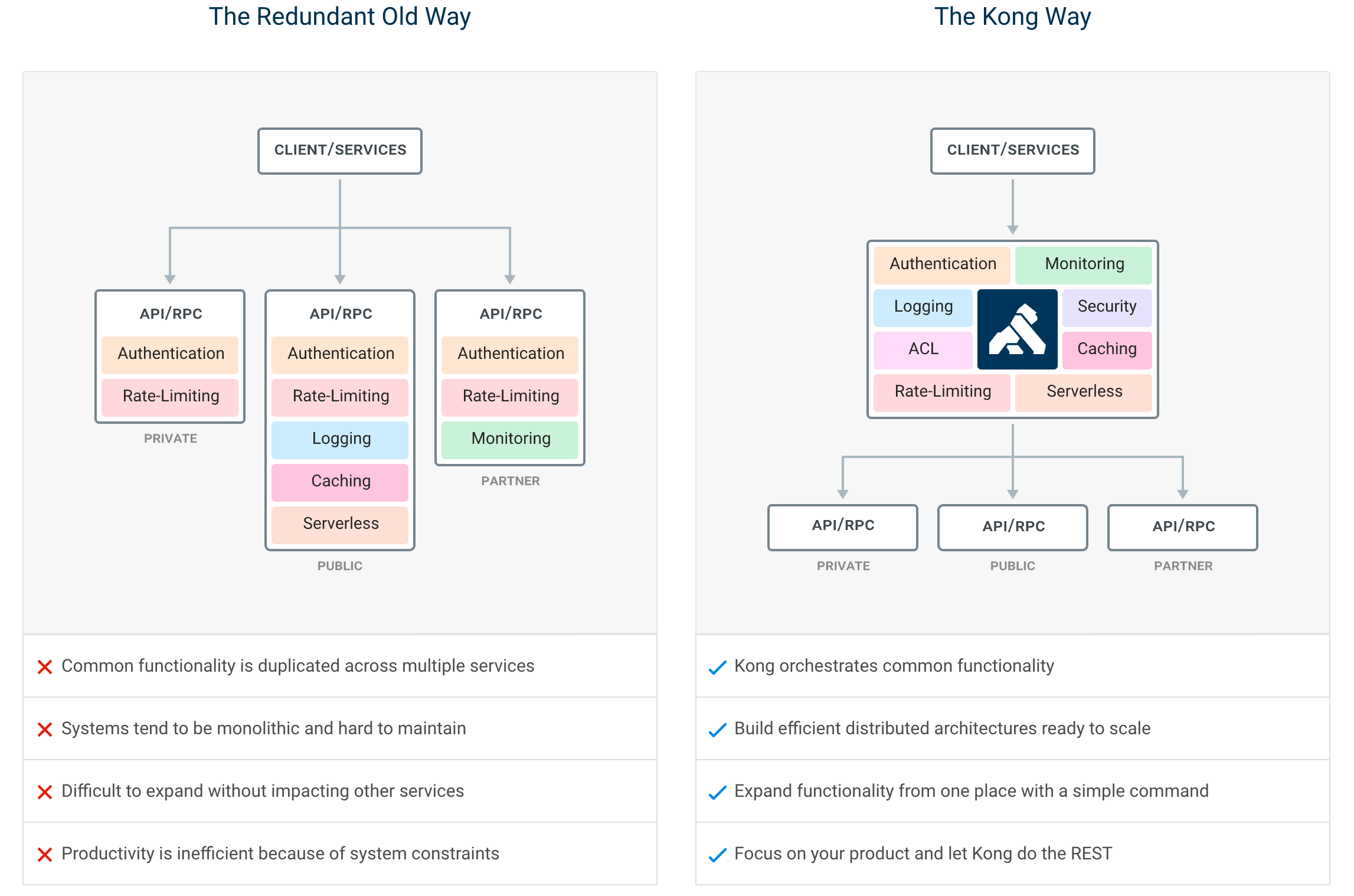
高性能API网关Kong介绍
本文关键词:高性能、API网关、Kong、微服务1.Introduction是随着微服务(Microservice)概念兴起的一种架构模式。原本一个庞大的单体应用(Allinone)业务系统被拆分成许多微服务(Microservice)系统进行独立的维护和部署,服务拆分带来的变化是API的规模成倍增长,API的管理难度也在日益增加,使用API网关发布和管
1
•••
93
94
95
•••
135