推荐
专栏
教程
课程
飞鹅
本次共找到8916条
数据校验
相关的信息
一只编程熊
•
4年前
ACM金牌选手整理的【LeetCode刷题顺序】
算法和数据结构知识结构图首先,了解算法和数据结构有哪些知识点,在学习中形成大局观,对学习和刷题十分有帮助。下面是我花了一天时间整理的算法和数据结构的知识结构,大家可以看看。<imgsrc"https://tva1.sinaimg.cn/large/008i3skNly1gsbvbwd5u1j30ys0u0tl6.jpg"alt"image202107
CuterCorley
•
4年前
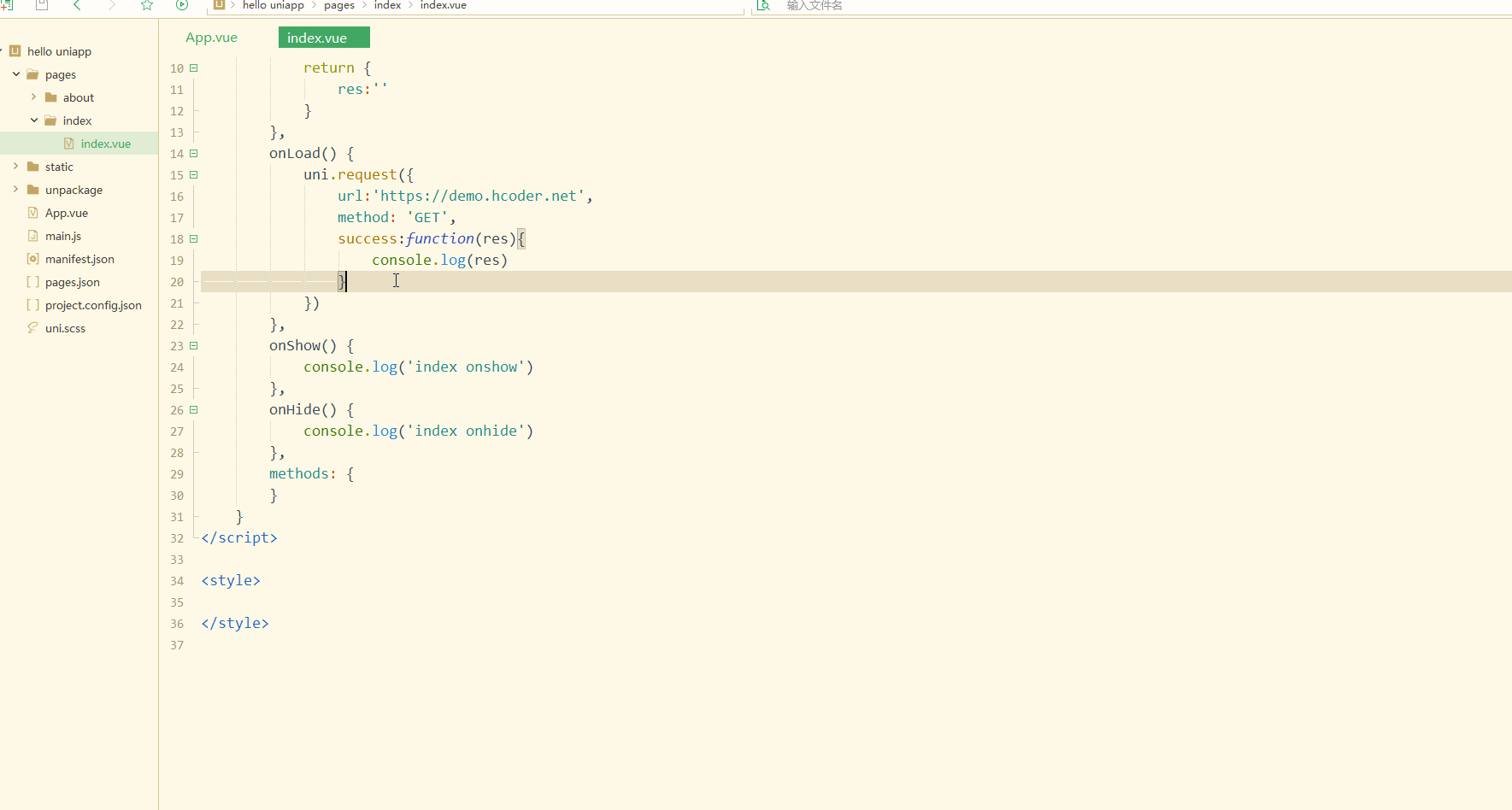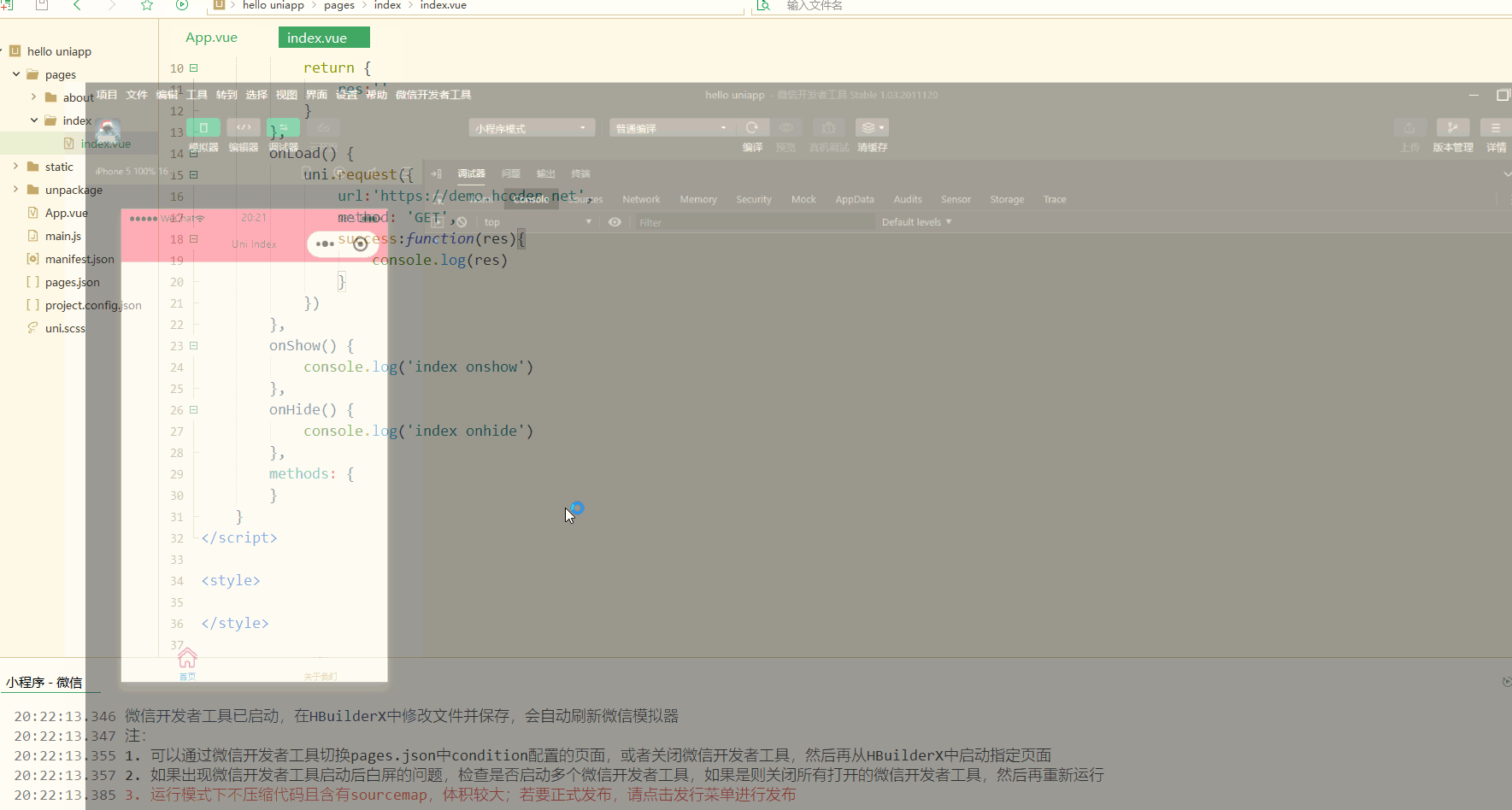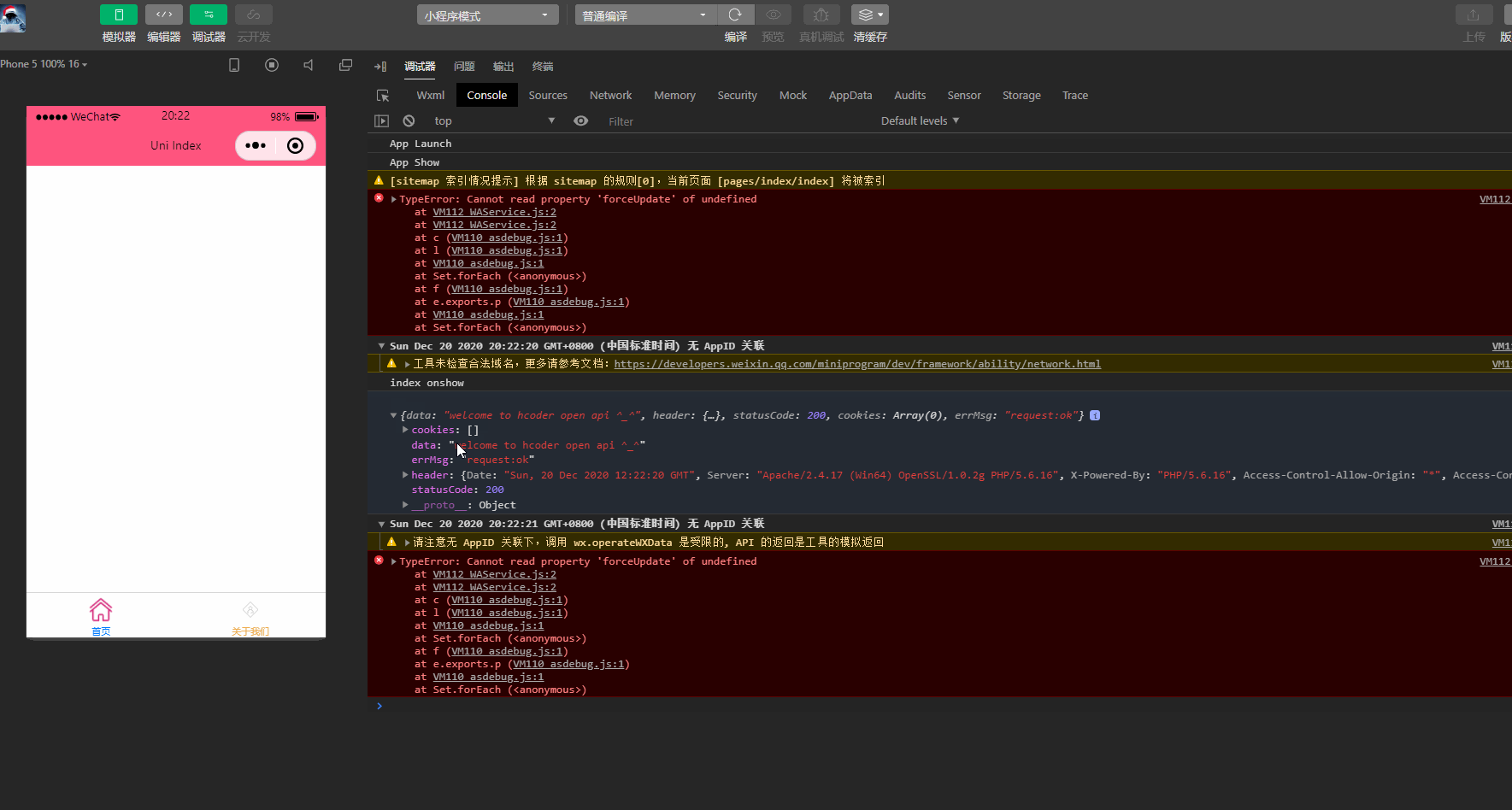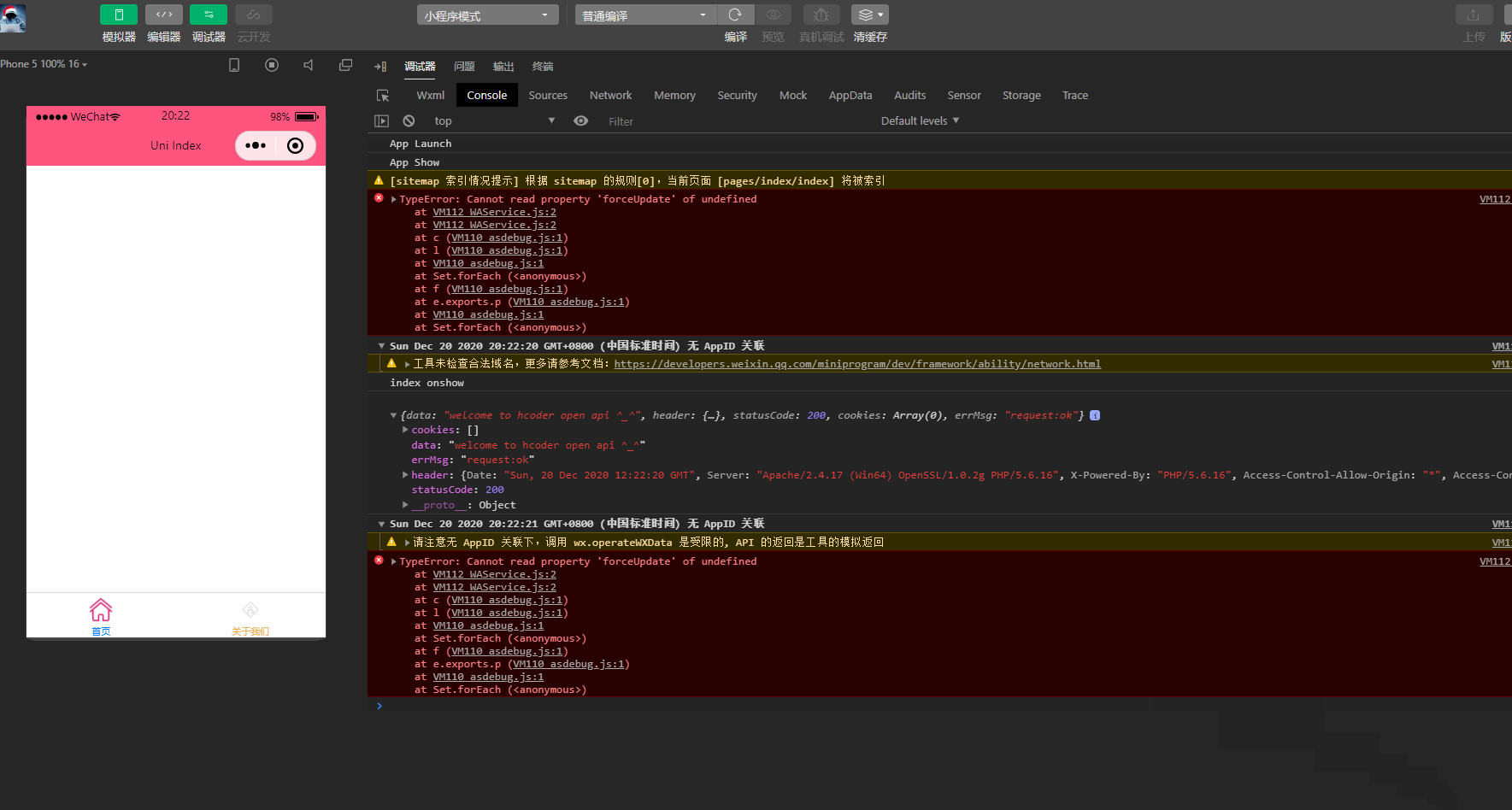
uni-app入门教程(5)接口的基本使用
前言本文主要介绍uniapp提供的一些基础接口,包括:网络请求接口,用于通过指定的请求方法,携带特定的数据,向特定的地址请求并返回请求结果;图片处理接口,包括选择、预览、获取信息、保存到本地等接口;文件处理接口,包括文件上传和下载接口;数据缓存接口,包括以同步或异步的方式保存、获取或删除数据的接口。一、网络请求小程序要想正常运转,都需要与服务器端进
Stella981
•
4年前
Linux三剑客之awk详解
第一篇awk简介与表达式实例一种名字怪异的语言模式扫描和处理,处理数据和生成报告。awk不仅仅是linux系统中的一个命令,而且是一种编程语言;它可以用来处理数据和生成报告(excel);处理的数据可以是一个或多个文件;可以是直接来自标准输入,也可以通过管道获取标准输入;awk可
Stella981
•
4年前
Cube的构建过程
Cube的构建方式有两种:全量构建和增量构建。两者的构建过程完全一样,区别在于构建时读取的数据源是全集还是子集。Cube的构建步骤:1.创建临时的Hive平表(从Hive读取数据)。2.计算各维度的不同值,并收集各Cuboid的统计数据。3.创建并保存字典。4.保存Cuboid统计信息。5.创建HTable。6.计算
Stella981
•
4年前
Hive和HBase有哪些区别与联系及适用场景
hiveHive是运行在Hadoop上的一个工具,准确地讲是一个搜索工具。当对海量数据进行搜索时,Hadoop的计算引擎是MapReduce。但是对MapReduce的操作和编程是非常复杂的。于是Hive的存在就让复杂的编程过程简化成了用SQL语言对海量数据的操作。这大大减轻了程序员的工作量。可以说,Hive的存在让海量数据的增删改查更加方便。
Wesley13
•
4年前
MySQL 你可能忽视的选择问题
我们在MySQL入门篇主要介绍了基本的SQL命令、数据类型和函数,在局部以上知识后,你就可以进行MySQL的开发工作了,但是如果要成为一个合格的开发人员,你还要具备一些更高级的技能,下面我们就来探讨一下MySQL都需要哪些高级的技能MySQL存储引擎存储引擎概述数据库最核心的一点就是用来存储数据,数
Stella981
•
4年前
Dicom关键概念
数据格式 DICOM将信息分组到datasets中,这意味着胸部X射线图像的文件实际上包含文件中的患者ID,因此图像永远不会被错误地与该信息分开。类似的,JPEG等图像格式也可以使用嵌入式tags中。 DICOM数据对象由许多属性组成,包括名字,ID等,还有一个包含图像像素数据的特殊属性。单个DICOM对象只能包含一个包含像素数
Wesley13
•
4年前
ARTS打卡计划第5周
在项目开发过程中,我们经常会遇到树形数据结构的设计,例如菜单树,地区树和类别树等等。一般而言,我们需要把数据库中记录全取出来,然后构建树(注意的是,最好是一次性取出来,如果是ajax按需拉数据则不需要)。下面分享了递归和非递归两种方式:packagetest.tree;importjava.util.ArrayLis
Easter79
•
4年前
TimescaleDB比拼InfluxDB:如何选择合适的时序数据库?
https://www.itcodemonkey.com/article/9339.html时序数据已用于越来越多的应用中,包括物联网、DevOps、金融、零售、物流、石油天然气、制造业、汽车、太空、SaaS,乃至机器学习和人工智能。虽然当前时序数据库仅局限于采集度量和监控,但是软件开发人员已经逐渐明白,他们的确需要一款时序数据库,真正设计用于运行多种工
Stella981
•
4年前
Redis常见面试题
redis介绍 Nginx是一个高性能的HTTP和反向代理服务器,及电子邮件代理服务器,同时也是一个非常高效的反向代理、负载平衡 Redis是一个开源的使用ANSIC语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、KeyValue数据库,并提供多种语言的API的非关系型数据库。传统数据库遵循ACI
1
•••
326
327
328
•••
892