推荐
专栏
教程
课程
飞鹅
本次共找到3326条
数据库工程师
相关的信息
仲远
•
2年前
Navicat Premium for Mac(多连接数据库管理工具)
NavicatPremium16forMac是Mac平台上的一款可以多重连接的数据库管理工具。与旧版本相比,Navicat16带来了许多UI/UX改进。我们致力于提供专业的UX设计,以提高可用性和可访问性。因此,你能够以前所未有的速度完成复杂的工作。
陈占占
•
4年前
Python爬虫-爬取图片并且存储到MySQL数据库中
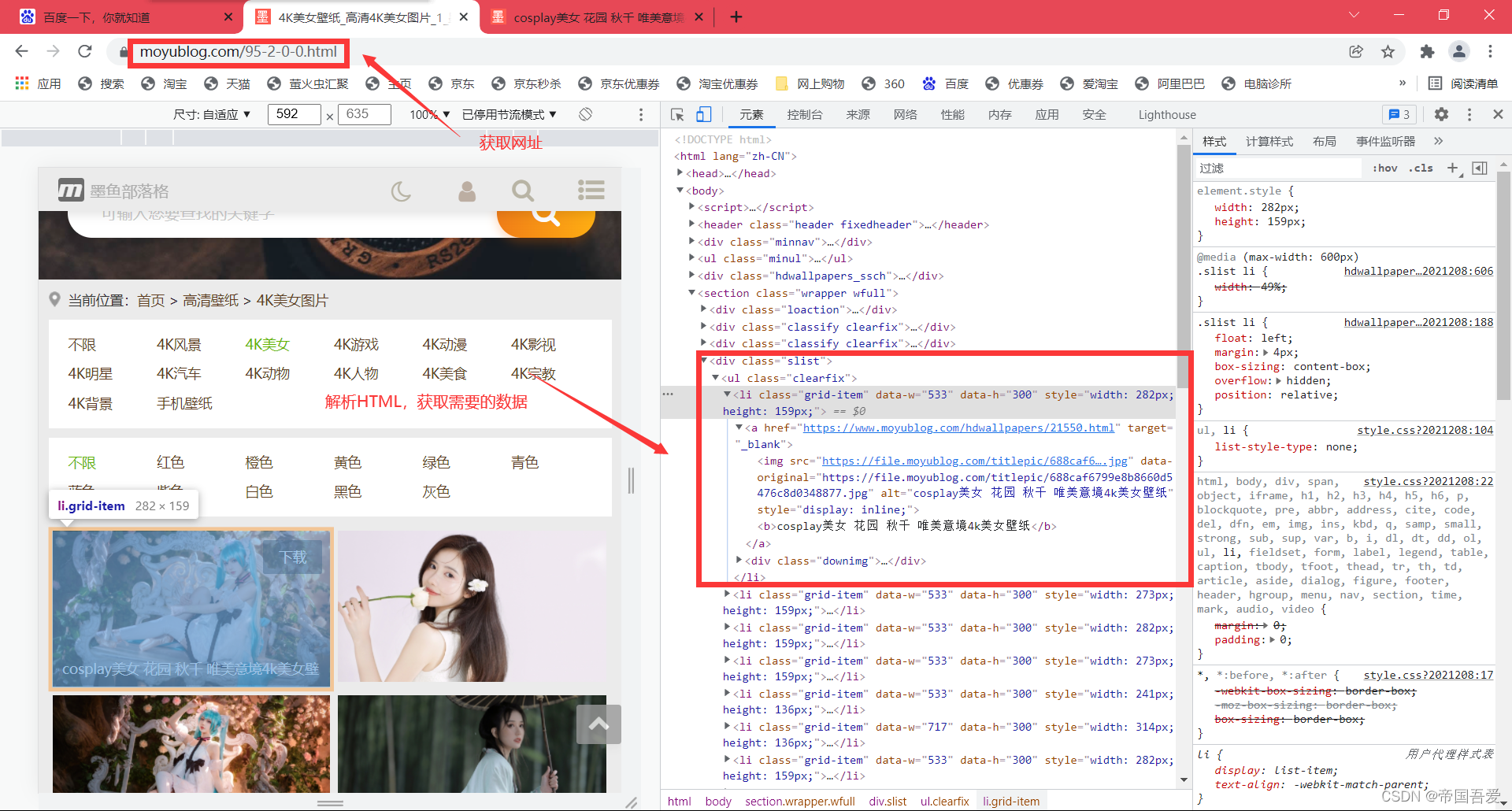
一、获取网址,解析网址(1)、for循环获取不同页的数据(2)、获取a标签中的网址(原因:外面图片分辨率太小,进入图片对应的网址寻找分辨率大点的图片)url网址https://www.moyublog.com/95200.htmlforiinrange(1):strvaluestr(i)页数url"htt
Stella981
•
4年前
Linux系统:Centos7下搭建PostgreSQL关系型数据库
本文源码:GitHub·点这里(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fcicadasmile%2Flinuxsystembase)||GitEE·点这里(https://gitee.com/cicadasmile/linuxsystem
Stella981
•
4年前
PingCAP 开源分布式数据库 TiDB 论文入选 VLDB
8月31日9月4日,第46届VLDB会议以线上直播的方式举行(原定于日本东京召开),PingCAP团队的论文《TiDB:ARaftbasedHTAPDatabase》入选VLDB2020,成为业界第一篇RealtimeHTAP分布式数据库工业实现的论文。PingCAP联合创始人、CTO黄东旭获邀在会上
Wesley13
•
4年前
ubuntu14.04直接用命令行安装mysql数据库
今天在Ubuntu(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.linuxidc.com%2Ftopicnews.aspx%3Ftid%3D2)14.04下安装MySQL,本来是去官网下载安装包来安装的,可是安装之后却不能用,估计是要配置吧,在网上搜了很多的资料,结果还是失败
Easter79
•
4年前
SpringCloud实现分库分表模式下,数据库实时扩容方案
本文源码:GitHub·点这里(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fcicadasmile%2Fspringcloudbase)||GitEE·点这里(https://gitee.com/cicadasmile/springcloud
Stella981
•
4年前
Koa 连接mysql数据,mysql数据库表初始化脚本
以下脚本是借鉴chenshenhai大佬的Koa教程中的代码,并对其进行修改。整个初始化步骤作为记录,方便以后快速查阅。目录结构:sqldata.sqluser.sqldbmysql_config.js//数据库配置a
Easter79
•
4年前
Tomcat下的数据库连接池的配置与使用
实验环境:EclipseNeon.3(4.6.3)、MySQL、Tomcat9.0一、在web应用下的METAINF下新建context.xml文件,配置数据源。<?xmlversion"1.0"encoding"UTF8"?<Context<Resourcename"DBPool"
Stella981
•
4年前
GitHub开源的最全中文诗歌古典文集数据库
GitHub开源的最全中华古典文集数据库,包含5.5万首唐诗、26万首宋诗、2.1万首宋词和其他古典文集。诗人包括唐宋两朝近1.4万古诗人,和两宋时期1.5千古词人。!(https://oscimg.oschina.net/oscnet/up76139d548d2a2a1a179cf3da6b8bf3a7.gif)为什么要做
Wesley13
•
4年前
spring+mybatis 根据业务场景访问不同数据库,读写分离
//配置文件<beanid"sqlSessionFactory1"class"org.mybatis.spring.SqlSessionFactoryBean" <propertyname"dataSource"ref"DataSource1"/ <propertyname"configLocat
1
•••
207
208
209
•••
333