推荐
专栏
教程
课程
飞鹅
本次共找到10000条
数据与信息
相关的信息
Java架构没有996
•
4年前
学妹问我Java枚举类与注解,我直接用这个搞定她!
很多人问我学妹长什么样,不多说上图吧!(https://shimo.im/docs/9GTP6XrJg9J88cJD/)@一、枚举类类的对象只有有限个,确定的.我们称此类为枚举类.说明:1.类的对象只有有限个,确定的。如:星期:Monday(星期一)、......、Sunday(星期天)性别:Man(男)、Woman(女)季节:Sp
Karen110
•
4年前
一文了解滴滴与蚂蚁金服开源共建的SQLFlow
「数仓宝贝库」,带你学数据!导读:SQFlow利用SQL语言构建机器学习和深度学习,致力于“MakeAIassimpleasSQL”,愿景是推进人工智能大众化、普及化,也就是只要懂商业逻辑就能用上人工智能,让懂业务的人能自由地使用人工智能。本文带你快速了解开源的工程化的自助式数据科学平台SQLFlow。SQLFlow利用SQL语言构建机器学习
Wesley13
•
4年前
Netty4.0学习笔记系列之一:Server与Client的通讯
本文是学习Netty的第一篇文章,主要对Netty的Server和Client间的通讯机制进行验证。Server与Client建立连接后,会执行以下的步骤:1、Client向Server发送消息:Areyouok?2、Server接收客户端发送的消息,并打印出来。3、Server端向客户端发送消息:Iamok!4、Client接收
Wesley13
•
4年前
60分钟视频带你掌握NLP BERT理论与实战
向AI转型的程序员都关注了这个号👇👇👇机器学习AI算法工程 公众号:datayx本课程会介绍最近NLP领域取得突破性进展的BERT模型。首先会介绍一些背景知识,包括WordEmbedding、RNN/LSTM/GRU、Seq2Seq模型和Attention机制等。然后介绍BERT的基础Transformer模
Stella981
•
4年前
Jenkins2.32.1+svn+maven安装配置与构建部署(一)
Stella981
•
4年前
CentOS7绑定多ip与Nginx整合实现应用网络隔离
相信点进来看的朋友们可能是被我的标题吸引的,没错,我就是标题党,本文所实现的并不是真正的网络隔离,只是实在想不出什么好的标题了,才这么写的或许在平时的使用中,(我说的是内网环境下),可能会看到如下的url地址http://172.16.4.111:8080/xxx(https://www.oschina.net/action/GoTo
Stella981
•
4年前
App 后台架构设计方案 设计思想与最佳实践
转http://blog.csdn.net/smartbetter/article/details/53933096(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fblog.csdn.net%2Fsmartbetter%2Farticle%2Fdetails%2F53933096)
Stella981
•
4年前
Linux实战教学笔记30:Nginx反向代理与负载均衡应用实践
1.1集群简介简单地说,集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统,每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器。这些服务器之间可以彼此通信,协同向用户提供应用程序,系统资源和数据,并以单一系统的模式加以管理。当用户客户机请求集群系统时,集群给用户的感觉就是
helloworld_38131402
•
3年前
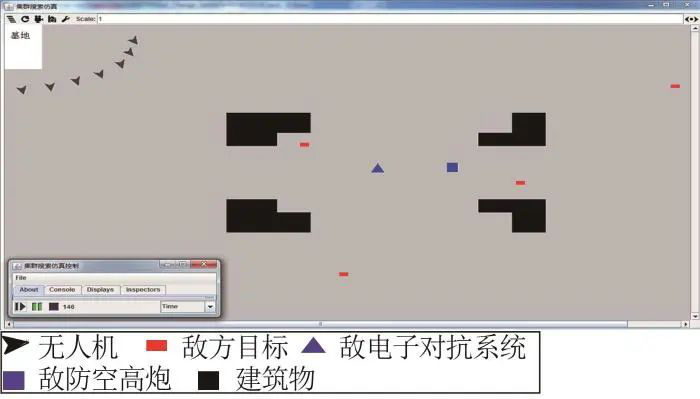
无人机集群自组织搜索仿真模型设计与实现
摘要:城市威胁背景下无人机集群自组织搜索移动目标问题,是无人机集群作战应用的一个重要发展方向。采用基于Agent的复杂系统建模仿真工具,构建了无人机集群搜索仿真模型框架,设计实现了无人机集群自组织搜索模型。在考虑无人机集群作战可能受到威胁的背景下,展示了无人机集群自组织搜索概念,探索了使用基于概率的有限状态机模型实现集群自主决策的解决方案,并通过案例进行了分
京东云开发者
•
3年前
【Rust学习】内存安全探秘:变量的所有权、引用与借用
Rust语言由Mozilla开发,最早发布于2014年9月,是一种高效、可靠的通用高级语言。其高效不仅限于开发效率,它的执行效率也是令人称赞的,是一种少有的兼顾开发效率和执行效率的语言。
1
•••
944
945
946
•••
1000