推荐
专栏
教程
课程
飞鹅
本次共找到4925条
存储过程
相关的信息
helloworld_78018081
•
3年前
限时发布!非科班程序员金三银四求职经历
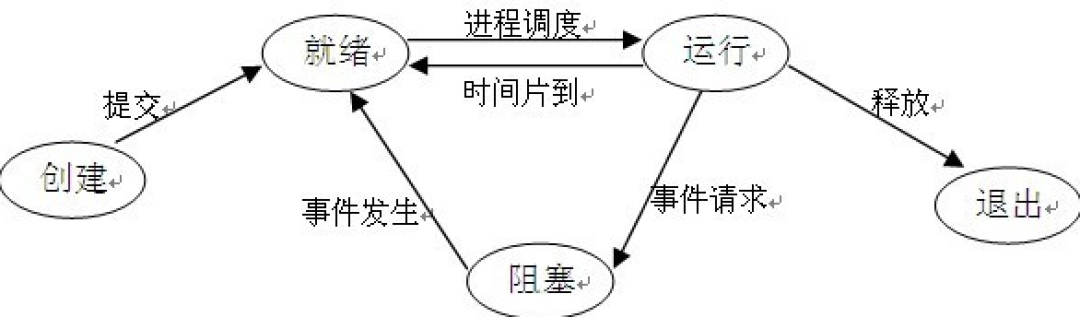
进程和线程的概念进程是具有独立功能的程序在一个数据集合上运行的过程。进程是系统进行资源分配的单位,实现的操作系统的并发。线程是比进程更小的能独立运行的单位,是 调度的基本单位,实现了进程内部的并发。线程成为了程序执行流的最小单位。进程状态转换图1.创建状态:进程正在被创建。2.就绪状态:进程已经分配到了除 之外的所有资源,只要分配到 就可以开
Easter79
•
3年前
TypeScript Generics(泛型)
软件工程的一个主要部分就是构建组件,构建的组件不仅需要具有明确的定义和统一的接口,同时也需要组件可复用。支持现有的数据类型和将来添加的数据类型的组件为大型软件系统的开发过程提供很好的灵活性。在C和Java中,可以使用"泛型"来创建可复用的组件,并且组件可支持多种数据类型。这样便可以让用户根据自己的数据类型来使用组件。泛型的简单案例首先,
Stella981
•
3年前
Redis内存淘汰机制
摘要Redis是一款优秀的、开源的内存数据库,我在阅读Redis源码实现的过程中,时时刻刻能感受到Redis作者为更好地使用内存而费尽各种心思,例如最明显的是对于同一种数据结构在不同应用场景下提供了基于不同底层编码的实现(如压缩列表、跳跃表等)。今天我们暂时放下对Redis不同数据结构的探讨,来一起看看Redis提供的另一种机制——内存淘汰机制。
Wesley13
•
3年前
mysql可扩展第二部分
数据分片主要是将数据按照一定的规则分为几个完全不同的数据集合的方式成为数据分片。数据的切分可以是数据库内的,将数据库中的一张表切分为几个不同的数据库表。也可以是数据库级别的,将数据库中的表划分为多个表,这些表存储在不同的数据库服务器上。该部分主要用来介绍数据库级的数据分片。切分规则将具有相关的数据保存在同一个分片上可以提高数据查询效率。数据库分片的路由规
邢德全
•
1年前
制造业企业如何通过数字化转型建立智能工厂
企业想实现数字化转型建立智能工厂,就需要先建设数字化车间,可以说数字化车间是建设智能工厂的重要一环,智能工厂的基础是数字化车间。数字化车间可以实现企业生产过程中车间计划调度、工艺执行管理、生产质量管理等监督及追溯,达到智能安全生产,提升产品质量的目的,从而完成企业建设智能工厂的重要一步,进而达到加强外界联系、拓宽国际市场的目的。
API 小达人
•
1年前
Eolink Apikit「 零代码」快速发起 RPC 接口自动化测试
RPC(RemoteProcedureCall)远程过程调用,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC的核心思想是将远程服务抽象成一个接口,客户端通过调用这个接口,就可以实现对远程服务的访问。EolinkApikit支持多协议,RPC、DUBBO、HTTP、REST、Websocket、gRPC、TCP、UDP、SOAP、HSF等。零代码快速发起RPC接口自动化测试,可以根据RPC接口文档自动生成测试用例,开发者只需简单修改即可使用。
小万哥
•
9个月前
Kotlin 布尔值教程:深入理解与应用示例
Kotlin中的布尔值是一种数据类型,仅能存储true或false两种状态,适用于表示二选一的情况,如开关或真假判断。布尔类型可通过Boolean关键字声明,并直接赋值为true或false。此外,Kotlin支持使用比较运算符创建布尔表达式,用于条件判断。条件语句包括if、else和elseif,允许根据不同条件执行特定代码块。特别地,在Kotlin中,if..else结构不仅能作为语句使用,还能作为表达式,即可以在条件判断的同时返回一个值。这种灵活性使得Kotlin在处理条件逻辑时更为简洁高效。
飞速低代码平台
•
3年前
飞速低代码平台 | 风口上的低代码,专业开发者需要考虑哪些?
低代码平台采用可视化的声明性技术,而不是传统的编程方式,开发人员和非开发人员都使用这些技术,并显著减少了交付应用程序和自动化过程的时间和精力。即便如此,低代码对不同的人来说仍然意味着很多事情,因为在这个总称下存在几种工具类型:网站生成器、表单生成器、API连接器、数据库生成器、工作流自动化等。这里,我们将介绍低代码开发与“无代码开发”的区别、主要用例、平台使
京东云开发者
•
2年前
万字长文详解如何使用Swift提高代码质量 | 京东云技术团队
京喜APP最早在2019年引入了Swift,使用Swift完成了第一个订单模块的开发。之后一年多我们持续在团队/公司内部推广和普及Swift,目前Swift已经支撑了70%以上的业务。通过使用Swift提高了团队内同学的开发效率,同时也带来了质量的提升,目前来自Swift的Crash的占比不到1%。在这过程中不断的学习/实践,团队内的CodeReview,也对如何使用Swift来提高代码质量有更深的理解。
天翼云开发者社区
•
1年前
将个人PC转变为高效的云电脑:理论、实践与优化
在数字化时代的今天,我们越来越依赖互联网和计算机技术进行工作和生活。然而,传统的个人电脑(PC)在使用过程中存在一些限制,例如硬件资源的利用率不高、数据安全难以保障等。为了解决这些问题,我们可以将个人PC转变为高效的云电脑,通过远程访问和共享的方式来提高资源利用率和数据安全性。本文将详细探讨这一主题,包括理论、实践和优化的方法。
1
•••
477
478
479
•••
493