推荐
专栏
教程
课程
飞鹅
本次共找到2275条
存储快照
相关的信息
Peter20
•
4年前
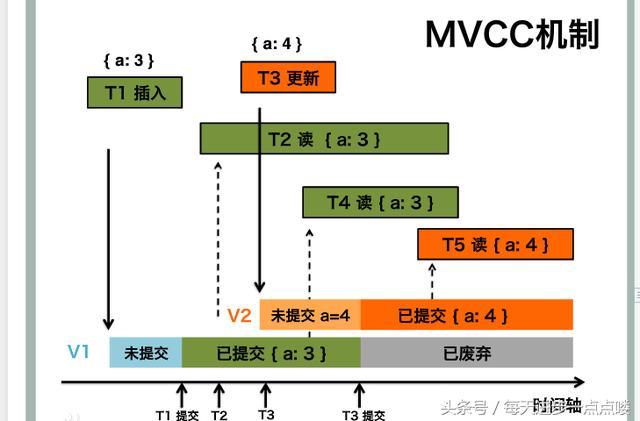
Mysql中MVCC的使用及原理详解
数据库默认隔离级别:RR(RepeatableRead,可重复读),MVCC主要适用于Mysql的RC,RR隔离级别创建一张存储引擎为testmvcc的表,sql为:CREATETABLEtestmvcc(idint(11)DEFAULTNULL,namevarchar(11)DEFAULTNULL)ENGINE\InnoDB
此账号已注销
•
4年前
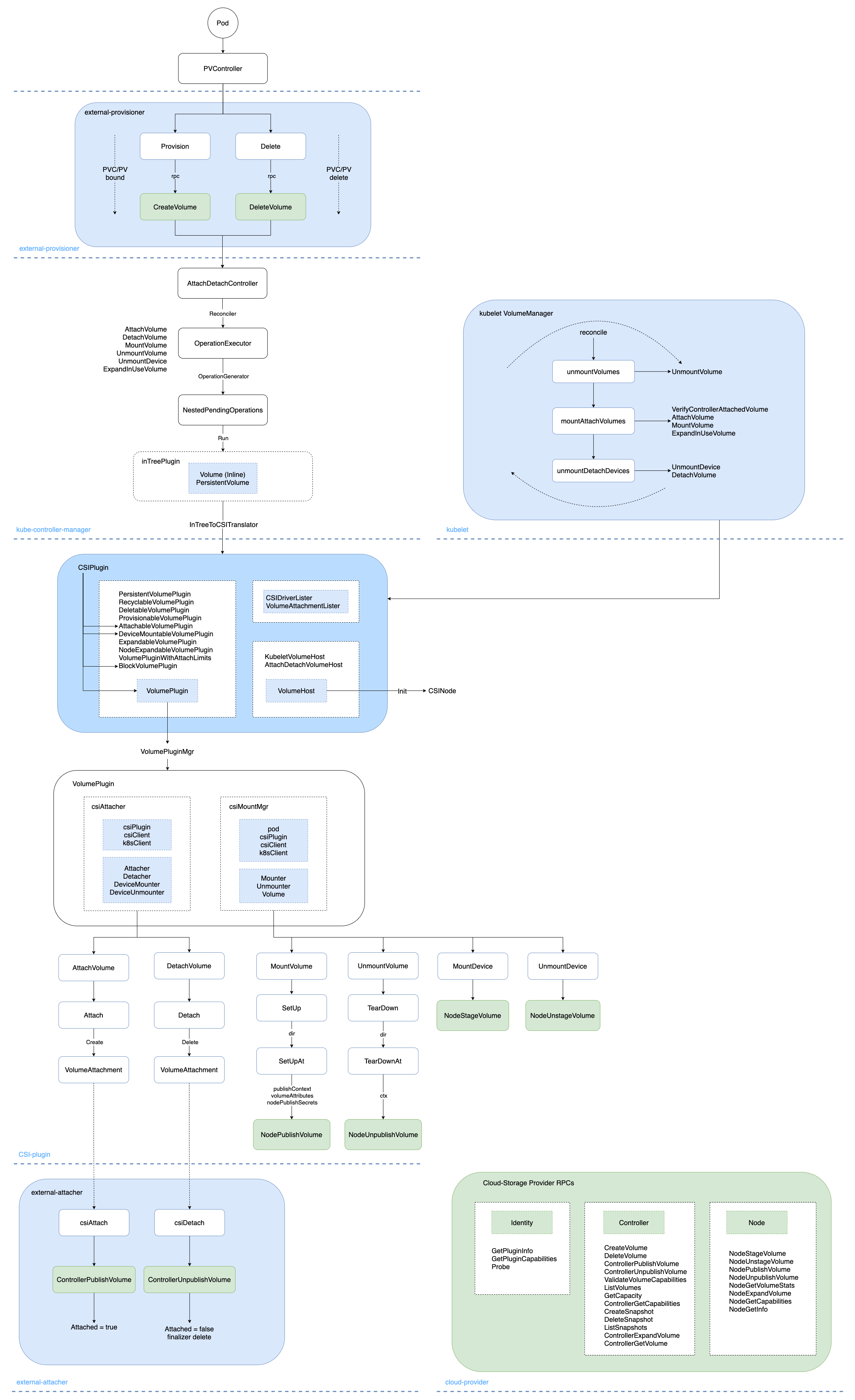
如何接入 K8s 持久化存储?K8s CSI 实现机制浅析
作者王成,腾讯云研发工程师,Kubernetescontributor,从事数据库产品容器化、资源管控等工作,关注Kubernetes、Go、云原生领域。概述进入K8s的世界,会发现有很多方便扩展的Interface,包括CSI,CNI,CRI等,将这些接口抽象出来,是为了更好的提供开放、扩展、规范等能力。K8s持久化存储经历了从in
Stella981
•
4年前
SpringBoot整合Redis乱码原因及解决方案
问题描述:springboot使用springdataredis存储数据时乱码rediskey/value出现\\xAC\\xED\\x00\\x05t\\x00\\x05问题分析:查看RedisTemplate类!(https://oscimg.oschina.net/oscnet/0a85565fa
Wesley13
•
4年前
voltdb 优化数据库使用方法
方法一、partitioning!(http://static.oschina.net/uploads/space/2016/0608/155940_ZDmx_2308739.png)此图是一个通过patitioning方法,按照相关列,将数据分发到集群当中不同的partition上面。然后通过存储过程,去
Wesley13
•
4年前
B树C语言代码实现
在这里实现的是在主存中的操作,没有进行文件的存储和修改。头文件btree.h:ifndef_BTREE_H define_BTREE_H defineMIN_T3 defineMAX_T(MIN_T2)typedefstructBTreeNod
Stella981
•
4年前
Database schema
Jira|事务与项目跟踪软件,敏捷团队的首先软件开发工具。Database–Changehistory Jira将每个Issue的变更历史记录存储在changegroup和changeitem表中。每条changegroup表记录,描述了它关联的Issue、变更
Stella981
•
4年前
PostgreSQL学习手册(数据表)
一、表的定义: 对于任何一种关系型数据库而言,表都是数据存储的最核心、最基础的对象单元。现在就让我们从这里起步吧。 1\.创建表:CREATETABLEproducts(product\_nointeger,nametext,pricenumeric);
1
•••
80
81
82
•••
228