推荐
专栏
教程
课程
飞鹅
本次共找到3111条
复杂网络
相关的信息
爱写码
•
4年前
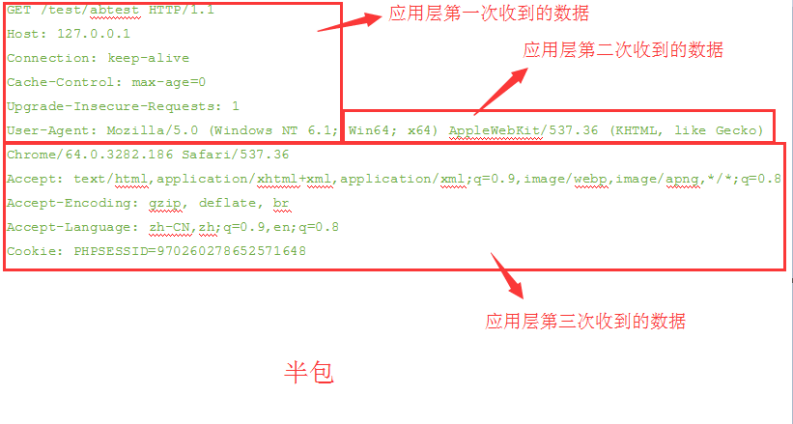
再聊t-io网络编程架构的基础知识:半包和粘包
半包顾名思义,就是收到了半个包,这个时候不足以组成一个应用层的包。就像你要对你喜欢的人说“我喜欢你”,但是因为喝水咽着了,第一次只说了“我”字,第二次说了个“喜”字,第三个次了个“欢你”,那么就发生了半包问题,对方只有等待你说完这4个字后才知道你是想说“我喜欢你”!用http协议为例,展示半包场景粘包粘包与半包相反,就是把多个想说的话,一口气说完了,对方反应
专注IP定位
•
4年前
FBI 警告称,网络犯罪分子可能以 2021 年东京奥运会为目标!
美国联邦调查局(FBI)已就威胁行为者可能试图扰乱即将到来的2021年东京夏季奥运会发出警告。它继续警告说,网络犯罪分子可以利用各种类型的网络犯罪,例如分布式拒绝服务(DDoS)攻击、勒索软件或社会工程来破坏奥运会。但是,就目前而言,还没有迹象表明针对这项受欢迎的体育赛事进行了攻击。联邦调查局表示:“迄今为止,联邦调查局并未发现针对这些奥运会的
专注IP定位
•
4年前
李克强签署国务院令 公布《关键信息基础设施安全保护条例》
关键信息基础设施安全保护条例》已经2021年4月27日国务院第133次常务会议通过,现予公布,自2021年9月1日起施行。总理李克强2021年7月30日关键信息基础设施安全保护条例第一章总则第一条为了保障关键信息基础设施安全,维护网络安全,根据《中华人民共和国网络安全法》,制定本条例。第二条本条例所称关键信息基础设施,是指公共通信和信息服务、能源、交通、
李志宽
•
4年前
小白怎么成为一个黑客?按照这个路线来!
大家好,我是周杰伦。接下来我会写系列的文章,给大家整理下网络安全的详细的学习步骤和学习资源推荐。今天的主题是——Web安全。Web安全是网络渗透中很重要的一个组成部分,今天跟大家聊一下,如何在三个月内从零基础掌握Web安全。第一个月第一周:HTMLCSS,学会网页基本格式,学会编写基本网页,表单,学会用浏览器F12检查元素,查看源码推荐学习地址:H
爱写码
•
4年前
唯一入驻华为开源优选库的国产网络框架t-io
在2020年5月份,tio在版本tio3.6.1发布的时候,就被华为选中作为网络中台,入驻华为开源软件优选库。主要原因还是因为tio一路走来也有将近十年的精心打磨了,被华为业软部的某测试部严格测试的3个月中,配合华为的测试要求,不断完善tio,把tio磨练成一个相对更加完美的产品了,所以tio相对比较完善了,能满足目前各行各业的应用需求,而且tio周边的产
Stella981
•
4年前
Bengio参与、LeCun点赞:图神经网络权威评测工具Benchmark开源了!
点击上方“迈微电子研发社”,选择“星标”公众号重磅干货,第一时间送达!(https://oscimg.oschina.net/oscnet/7032892bb3fd86c0fcd96afe151604e672b.jpg)来源:机器之心@微信公众号01前言图神经网络发展到什么程度了?现在我们有了专用的Bench
Python进阶者
•
3年前
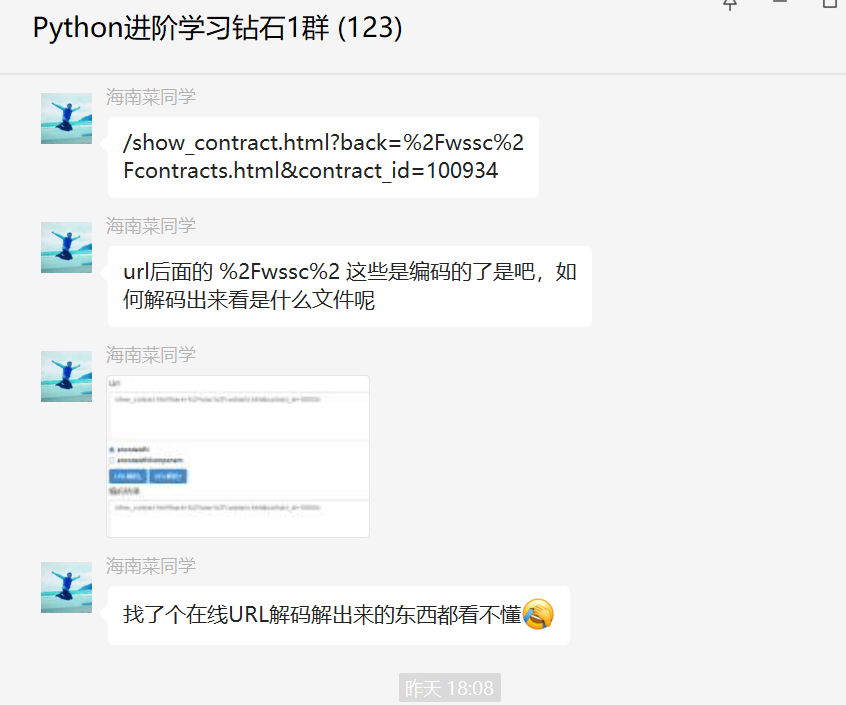
分享Python网络爬虫过程中编码和解码的一个库
大家好,我是皮皮。一、前言前几天在Python白银钻石群【海南菜同学】问了一个Python编码的问题,提问截图如下:原始代码如下:/showcontract.html?back%2Fwssc%2Fcontracts.html&contractid100934编码截图如下图所示:二、实现过程一开始以为不是编码,后来【此类生物】直接看出来了,太强了。其实关于
十月飞翔
•
3年前
chaoblade create network loss --- 网络丢包实验场景---混沌测试故障注入
介绍可以指定网卡、本地端口、远程端口、目标IP丢包。需要特别注意,如果不指定端口、ip参数,而是整个网卡丢包,切记要添加timeout参数或者excludeport参数,前者是指定运行时间,自动停止销毁实验,后者是指定排除掉的丢包端口,两者都是防止因丢包率设置太高,造成机器无法连接的情况,如果真实发生此问题,重启机器即可恢复。本地端口和远程端口
胖大海
•
3年前
Debian 11 安装,超详细!
安装装备华为源中下载镜像 3A服务器的虚拟机开始安装配置虚拟机直接回车即可,第一次安装的小伙伴可以选择中文版安装,这样方便易懂,一路继续,配置网络,ip配置完之后网络就可以ping通了,下面是主机名配置,root用户密码配置,配置另一个新用户,注意不能是root磁盘分区,一路继续逻辑卷配置,选择是一路继续选择是一路继续配置软件包,选择最近的镜像地址与网
天翼云开发者社区
•
2年前
云电脑架构设计的层次
云电脑架构设计的层次基础设施层是云电脑架构的最底层,负责提供计算、存储、网络等基础设施。这些基础设施可以由多个服务器组成,通过虚拟化技术进行资源池化,实现资源的动态分配和共享。基础设施层需要提供足够的计算、存储和网络资源,以满足虚拟化层和应用层的资源需求。同时,基础设施层还需要具备高可用性、可扩展性和安全性等特点,以满足用户的需求和保障数据安全。
1
•••
148
149
150
•••
312