
点击上方“迈微电子研发社”,选择“星标”公众号
重磅干货,第一时间送达

来源:机器之心@微信公众号
01
前言
图神经网络发展到什么程度了?现在我们有了专用的 Benchmark 工具来进行评测。
近期的大量研究已经让我们看到了图神经网络模型(GNN)的强大潜力,很多研究团队都在不断改进和构建基础模块。但大多数研究使用的数据集都很小,如 Cora 和 TU。在这种情况下,即使是非图神经网络的性能也是可观的。如果进行进一步的比较,使用中等大小的数据集,图神经网络的优势才能显现出来。
在斯坦福图神经网络大牛 Jure 等人发布《Open Graph Benchmark》之后,又一个旨在构建「图神经网络的 ImageNet」的研究出现了。近日,来自南洋理工大学、洛约拉马利蒙特大学、蒙特利尔大学和 MILA 等机构的论文被提交到了论文预印版平台上,而且这一新的研究有深度学习先驱 Yoshua Bengio 的参与,也得到了 Yann LeCun 的关注。

论文链接:https://arxiv.org/abs/2003.00982
在该研究中,作者一次引入了六个中等大小的基准数据集(12k-70k 图,8-500 节点),并对一些有代表性的图神经网络进行了测试。除了只用节点特征的基准线模型之外,图神经网络分成带或不带对边对注意力两大类。GNN 研究社区一直在寻求一个共同的基准以对新模型的能力进行评测,这一工具或许可以让我们实现目标。
现在,如果你想测试一下自己的图神经网络模型,可以使用它的开源项目进行测试了。
项目地址:https://github.com/graphdeeplearning/benchmarking-gnns
不同任务上的测试脚本,每一个 Notebook 都会手把手教你如何测试不同的图神经网络。
该开放基准架构基于 DGL 库,DGL 由 AWS 上海 AI 研究院、纽约大学、上海纽约大学开放和维护,是业界领先的图神经网络训练平台,并无缝支持主流深度网络平台。Benchmarking gnn 建立在 DGL 的 PyTorch 版本之上。
AWS 上海 AI 研究院首任院长、上海纽约大学张峥教授评论说:「这篇论文来得很及时,也有意义。第一,说明现有的数据集太小、以致成为前进的障碍,已经成为学界的共识。值得赞扬的是这篇文章的作者并没有因为 OGB 的发布就搁下不弄了。在我看来,他们的数据集和 OGB 有很强的互补性,呈现了图神经网络更丰富的应用场景,比如把图像数据转换成图数据,虽然是从 MNIST 和 CIFAR 开始,也隐含了颠覆或改变基于卷积网络 CNN 的解决方案,再比如旅行推销员问题是一个经典的优化问题,等等。」
「另外,基于这一系列的数据得到的结论有比较高的可信度,比如数据多起来图神经网络更能发挥优势,比如带注意力的图神经网络虽然参数更多,但性能也更好。总之,这些结果对激励更多的模型研究和拓展应用场景非常有意义。」张教授说
图神经网络已成为分析和学习图形数据的标准工具,并已成功地应用在很多领域中,包括化学、物理、社会科学、知识图谱、推荐系统以及神经科学等。随着各领域的发展,确定架构类型以及关键的机制显得尤为重要,这些架构与机制可以在跨图形大小的情况下进行泛化,使得我们能够处理更多更大更复杂的数据集以及领域。
但是,在缺乏具有一致性的实验设置和大量数据集没有标准化基准的情况下,衡量新的 GNN 有效性以及对比模型变得越来越困难。在本论文中,作者提出了一个可复制化的 GNN 基准测试框架,可以让研究人员方便地添加新的数据集以及模型。从数学建模、计算机视觉、化学和组合问题等多方面将这一基准框架应用至最新的中尺度图形数据集里,以便于在设计有效的 GNN 时建立起关键的操作。更准确的来说,图卷积、各项异性扩散、残差连接、归一化层是开发鲁棒性以及可扩展性 GNN 的通用构件。
02
基准测试的数据集和建构图的方法
这项工作的目标之一是提供一个易于使用的中等规模数据集,在这些数据集上,面向过去几年中所提出的不同 GNN 架构在性能表现上有明显的差异。同时,这些差异从统计的角度上来说是具有相当的意义,该基准包含 6 个数据集,如表 1:
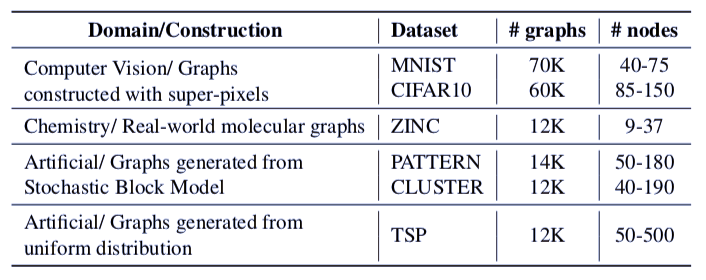
提议基准数据集的汇总统计信息。
对于这两个计算机视觉数据集,来自经典的 MNIST (LeCun et al., 1998) 以及 CIFAR10 (Krizhevsky et al., 2009) 数据集中的每个图像都使用了所谓的超像素转换成图。
而接下来的任务是将这些图形分类。在 PATTERN 和 CLUSTER 数据集中,图形是根据随机块模型生成的。这些任务包括识别特定的子图结构 (PATTERN 数据集) 或者识别集群 ( CLUSTER 数据集)。这些都属于是节点分类任务。
Tsp 数据集是基于销售人员旅行的问题 (假设给定一个城市列表,访问每个城市并返回原始城市的最短路径是什么?)
将随机欧氏图上的 TSP 问题作为一个边界分类或是连接预测的任务看待,其中 Concorde Solver 给出的 TSP 旅行中每一边界的真实情况值都属于是在现实世界中已存在的分子数据集。每个分子可被转换成一个图形: 其中每个原子可成为一个节点,每个键可成为一个边。
03
基准测试设置
GatedGCN-门控图卷积网络 (Bresson & Laurent,2017) 是考虑中的最后一个 GNN。如果在数据集中可用的情况下,其中 GatedGCN-e 表示使用边缘属性/特征的版本。另外,作者也实现了一个简单的不使用图结构的基线模型,它处于并行情况下对每个节点的特征向量使用一个 MLP,且独立于其他节点。
这是后续可选的一个门控机制,用以以获得门控 MLP 基线 (详情见补充材料)。作者对 MNIST,CIFAR10,ZINC 以及 TSP 在 Nvidia 1080Ti GPU 上进行实验,对 PATTERN 和 CLUSTER 在 Nvidia 2080Ti GPU 上进行实验。
图分类和超像素数据集
这一部分使用了计算机视觉领域里最流行的 MNIST 和 CIFAR10 图像分类数据集。超分辨率格式为 SLIC(Knyazev et al., 2019)。MNIST 拥有 55000 训练/5000 验证/10000 测试图,节点为 40-75 之间(即超像素的数量),CI-FAR10 有 45000 训练/5000 验证/10000 测试图,节点数为 85-150。

图 1. 示例图和超像素图。SLIC 的超像素图(其中 MNIST 最多 75 节点,CIFAR10 最多 150 节点)是欧几里得空间中的 8 个最近邻图形,节点颜色表示平均像素强度。
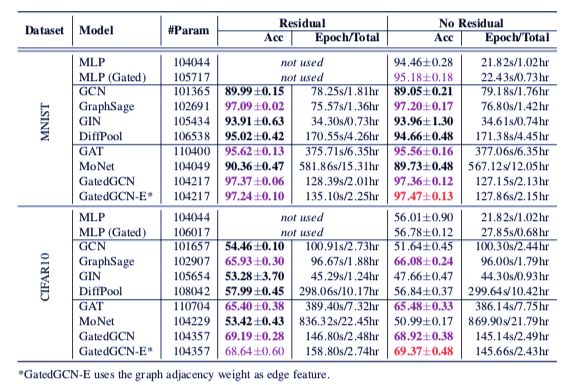
表 3. 不同方法在基于 MNIST 和 CI-FAR10 的标准测试集上的测试结果(数值越高越好)。该结果是使用 4 个不同种子运行四次结果的平均值。红色为最佳水平,紫色为高水平。粗体则表示残差链接和非残差连接之间的最佳模型(如两个模型水平相同则皆为粗体显示)。
图回归和分子数据集
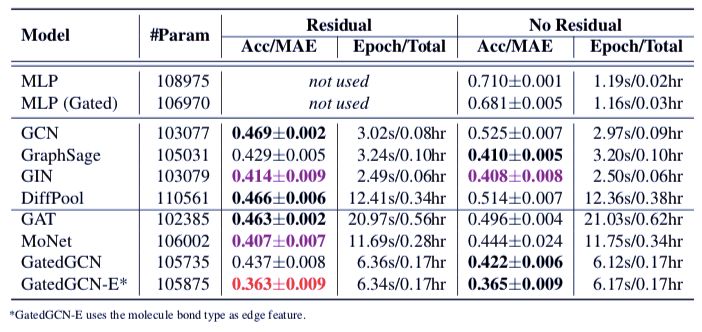
ZINC 分子数据集被用于对受限溶解度分子特性进行回归分析。在这里 ZINC 有 10000 训练/1000 验证/1000 测试图,节点数/原子数为 9-37。对于每个分子图,节点特征是原子的类型,边缘特征是边缘的类型。
在SBM数据集上进行节点分类
研究者考虑了节点级别的图模式识别任务和半监督图聚类任务。图模式识别时为了找到一个固定的图模式 P,嵌入于更大的图 G 中。
而半监督聚类任务则是网络科学中的另一个重要任务。研究者针对以上两个任务分别生成了相应的数据集。
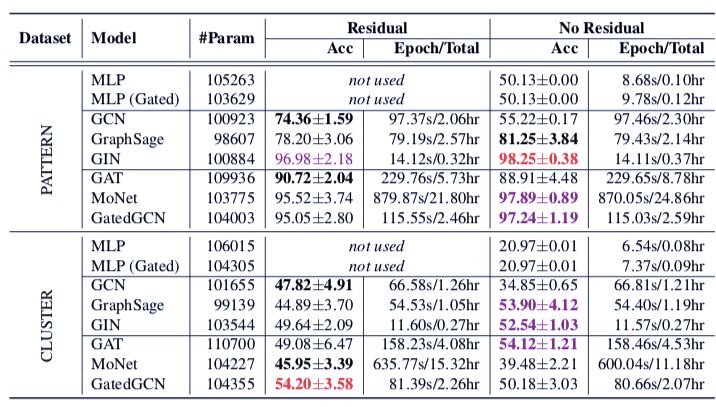
表 5:在标准测试集 PATTERN 和 CLUSTER SBM 图上的性能表现。
TSP数据集上的边分类
TSP(Travelling Salesman Problem)指的是旅行推销员问题:给定一个 2D 的欧几里得图,算法需要找到一个最优的序列节点,名为 Tour。它应当有着最少的边权重。TSP 的大规模特性使得它成为一个具有挑战性的图任务,需要对局部节点的近邻和全局图结构进行推理。
更重要的是,组合优化问题也是 GNN 中有研究意义的一个应用场景。研究这类问题,不仅仅在现实中有着广泛的应用,还对于理解图模型的优化和学习过程,图网络本身的局限性等有重要意义。
在基准测试中,研究者采用了基于学习的方法,建立了一 GNN 作为骨架网络,来给每个边和是否所属预测结果集进行概率预测。这一概率经由图搜索技术被转换为离散决策。研究者分别创建了 10000 个训练实例和 1000 个验证、1000 个测试实例。
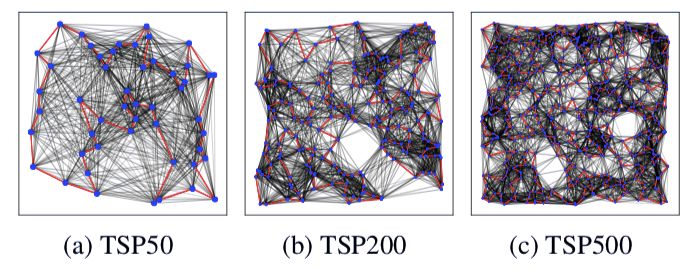
图 2:TSP 数据集的样本图。节点以蓝色表示,红色表示 groundtruth 的边。
04
测试结果
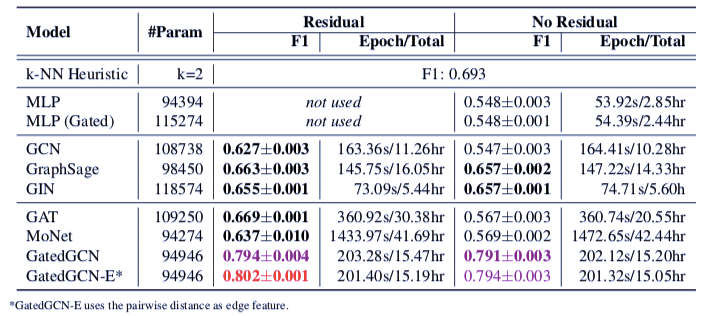
表 6:TSP 测试集的图性能表现,分为有/无残差连接良好总情况。红色表示最好的模型性能,紫色表示模型效果不错。
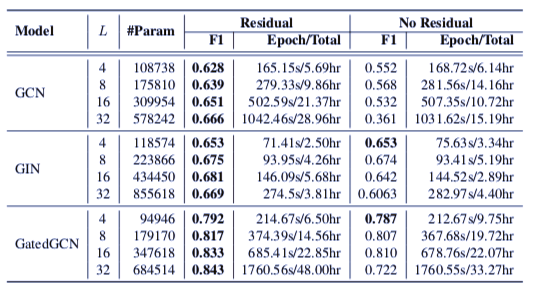
表 7:在 TSP 测试集图上的性能表现。模型是深度 GNN,有 32 层。模型分为使用残差连接和没有残差连接两种情况。L 表示层数,B 表示最好的结果(有残差连接和无残差连接的情况)。
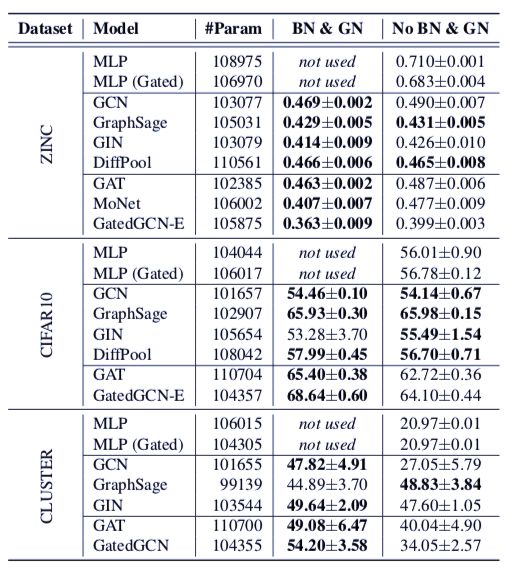
表 8:ZINC、CIFAR10 和 CLUSTER 测试集图在有或者没有 BN、GN 的情况下的性能表现。
ⓝ
MaiweiE-com|WeChat ID:Yida_Zhang2
相关文章
机器学习算法之——隐马尔科夫链(Hidden Markov Models, HMM)
机器学习算法之——支持向量机(Support Vector Machine, SVM)
机器学习算法之——逻辑回归(Logistic Regression)算法讲解及Python实现
机器学习算法之——梯度提升(Gradient Boosting) 上 算法讲解及Python实现
机器学习算法之——梯度提升(Gradient Boosting) 下 算法讲解及Python实现
机器学习算法之——决策树模型(Decision Tree Model)算法讲解及Python实现
机器学习算法之——K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
机器学习算法之——K最近邻(k-Nearest Neighbor,KNN)分类算法Python实现
传送门
精彩不断!干货不断!请关注迈微电子研发社公众号(点击上方蓝色专知关注)

△微信扫一扫关注「迈微电子研发社」公众号
知识星球:社群旨在分享AI算法岗的秋招/春招准备攻略(含刷题)、面经和内推机会、学习路线、知识题库等。
△扫码加入「迈微电子研发社」学习辅导群

点击“阅读原文”免费查看更多机器学习内容
(点击这里,即可留言)

本文分享自微信公众号 - 迈微电子研发社(MaiweiE-com)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。









