推荐
专栏
教程
课程
飞鹅
本次共找到59条
吞吐量
相关的信息
Wesley13
•
4年前
11张图了解HDFS的架构设计
HDFS介绍HDFS是一个适合部署在廉价机器上的,具有高度容错性的,高吞吐量的分布式文件系统。HDFS的设计理念支持超大规模数据集运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被设计成支持大文件存储,能在一个集群里扩展到
Johnny21
•
4年前
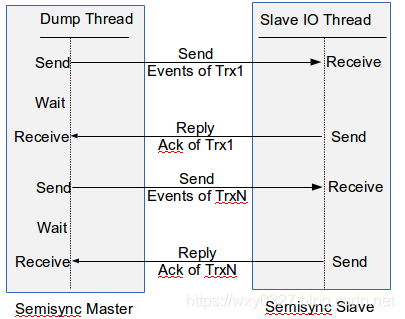
MySQL 8 复制(二)——半同步复制
目录一、简介直到目前的最新版本为止,MySQL缺省依然使用异步复制策略。简单说所谓异步复制,指的是主库写二进制日志、从库的I/O线程读主库的二进制日志写本地中继日志、从库的SQL线程重放中继日志,这三步操作都是异步进行的。如此选择的主要理由是出于性能考虑,与同步复制相比,异步复制显然更快,同时能承载更高的吞吐量。但异
Stella981
•
4年前
LinkedBlockingQueue 介绍
LinkedBlockingQueue是一个基于已链接节点的、范围任意的blockingqueue。此队列按FIFO(先进先出)排序元素。队列的头部是在队列中时间最长的元素。队列的尾部是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可
Stella981
•
4年前
RabbitMQ分布式集群架构和高可用性(HA)
(一)功能和原理设计集群的目的允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行通过增加更多的节点来扩展消息通信的吞吐量1集群配置方式RabbitMQ可以通过三种方法来部署分布式集群系统,分别是:cluster,federation,shovelcluster:不支持跨网段,用于同一个网段内的局域网可以随意的动态增加或者减
Stella981
•
4年前
ConcurrentHashMap之实现细节
ConcurrentHashMap是Java5中支持高并发、高吞吐量的线程安全HashMap实现。在这之前我对ConcurrentHashMap只有一些肤浅的理解,仅知道它采用了多个锁,大概也足够了。但是在经过一次惨痛的面试经历之后,我觉得必须深入研究它的实现。面试中被问到读是否要加锁,因为读写会发生冲突,我说必须要加锁,我和面试官也因此发生了冲突
Wesley13
•
4年前
C++ 多线程编程总结
在开发C程序时,一般在吞吐量、并发、实时性上有较高的要求。设计C程序时,总结起来可以从如下几点提高效率:并发异步缓存下面将我平常工作中遇到一些问题例举一二,其设计思想无非以上三点。1任务队列1.1 以生产者消费者模型设计任务队列 生产者消费者模型是人们非常熟
Wesley13
•
4年前
MQ之对比
activeMQ:高效、可扩展、稳定安全企业级消息通信rabbitMQ:分布式系统可靠、可扩展、功能丰富,内存式堆积,某些条件下触发换页动作将内存中消息换页到磁盘;支持多租户 不支持重试队列,二次封装延迟队列实现呢 拉模式,不回溯,支持消息追踪 多租户kafka:高吞吐量分布式发布订阅消息系统,可水平扩展,磁盘式堆积,冗余功能
Wesley13
•
4年前
MySQL应对高并发之Redis缓存
高并发高并发(HighConcurrency)是指系统运行过程中的一种“短时间内遇到大量操作请求”的情况,主要发生在web系统集中大量访问收到大量请求,例如淘宝双十一、京东618类的活动。该情况的发生会导致系统在这段时间内执行大量操作(对资源的请求、数据库的操作等)。高并发相关常用的一些指标有:响应时间、吞吐量、每秒查询率QPS、并发用户数
Stella981
•
4年前
Kafka生产环境的几个重要配置参数
Kafka在弹性、容错性以及高吞吐量方面有着很大的优势。想要达到生产环境最优,发挥这些特性,需要我们进行一系列的配置。Kafka提供了非常多的配置属性,对于初学者而言,很容易陷入困惑。其实,多数的配置已经满足了大部分的使用场景,本文分享总结了几个比较重要的配置参数,主要是针对producer端的配置,希望对你有所帮助。本文所讨论的配置文件包括:_√_
linbojue
•
1个月前
Kafka高性能揭秘:零拷贝、顺序写与页缓存,千万级吞吐量的底层原理深度剖析
很多同学在面试时都能背出那几句八股文:“零拷贝、顺序写、页缓存”。但如果面试官追问一句:“你能在Java里写出零拷贝的代码吗?你知道页缓存什么时候会失效吗?Kafka的索引文件为什么要用mmap而不是sendfile?”这时候,很多人就开始支支吾吾了。😅
1
2
3
4
5
6