推荐
专栏
教程
课程
飞鹅
本次共找到1578条
博客搜索
相关的信息
LeeFJ
•
3年前
Foxnic-Web 代码生成 (8) —— 配置列表页
列表页面主要包含了顶部的搜索区域和表格区域,搜索区域有点类似表单,配置上可能存在相似之处。本篇我们就来了解一下,在代码生成时的列表页呈现方面,我们可以做点啥。
Wesley13
•
4年前
java实现 PageRank算法
PageRank算法是Google的核心搜索算法,在所有链接型文档搜索中有极大用处,而且在我们的各种关联系统中都有好的用法,比如专家评分系统,微博搜索/排名,SNS系统等。 PageRank算法的依据或思想: 1,被重要的网页链接的越多(外链) ,此网页就越重要 2,此网页对外的链接越少越重要 这两个依据不能
晴雯
•
2年前
IntelliJ IDEA 2022 中文安装切换保姆级别教程
保姆级别的IntelliJIDEA2022中文设置教程,首次安装好之后点击plugins在搜索框搜索chinese,找到Chinese(Simplified)点击install中文语言包下载完成后点击RestrtIDE。点击restart,软件会自动重启。
Paul05
•
4年前
Docker 简单部署 ElasticSearch
一、ElasticSearch是什么?Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTfulAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。不过,
Wesley13
•
4年前
VSCode 配置 Sonar Lint
1、安装SonarQube2、在安装了SonarQube之后,使用CtrlP打开VSCode命令搜索功能,输入Sonar,搜索结果如下:!(https://oscimg.oschina.net/oscnet/8963097362dd9e8fca1eb30c565dec7a068.png)3、sonar
Stella981
•
4年前
PBFT算法java实现(上)
PBFT算法的java实现(上)在这篇博客中,我会通过Java去实现PBFT中结点的加入,以及认证。其中使用socket实现网络信息传输。关于PBFT算法的一些介绍,大家可以去看一看网上的博客,也可以参考我的上上一篇博客(https://www.oschina.net/action/GoToLink?url
Stella981
•
4年前
Jenkins+Git+Github+Python自动化化接口项目例子
环境:Linux服务器一台一、安装Jenkins参考博客:https://www.cnblogs.com/xiaokuangnvhai/p/11343003.html安装插件:PublishOverSSH二、安装Python环境参考博客:https://www.cnblogs.com/xiaokuangnvhai/p/11353014
Stella981
•
4年前
Kafka——SpringBoot整合(消费者位移的提交)
消费者位移的提交方式以及提交时机需要根据不同的业务场景进行选择,可以看之前的博客kafka消费者相关。这里只做应用相关,更多的使用场景,该怎么用、何时用要看前面的博客了解原理。参考博客:https://blog.csdn.net/yy756127197/article/details/103895810(https://www.oschina.ne
helloworld_38131402
•
3年前
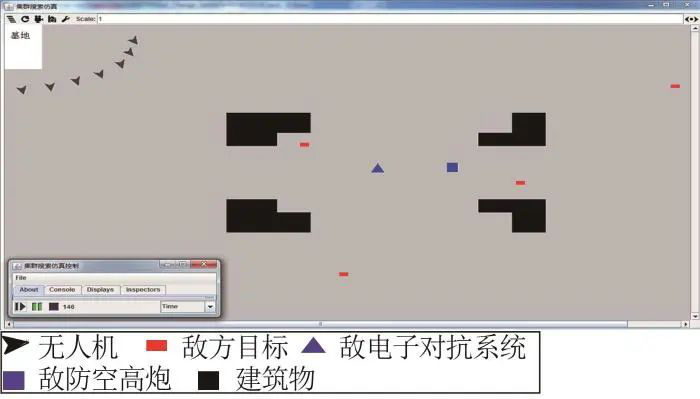
无人机集群自组织搜索仿真模型设计与实现
摘要:城市威胁背景下无人机集群自组织搜索移动目标问题,是无人机集群作战应用的一个重要发展方向。采用基于Agent的复杂系统建模仿真工具,构建了无人机集群搜索仿真模型框架,设计实现了无人机集群自组织搜索模型。在考虑无人机集群作战可能受到威胁的背景下,展示了无人机集群自组织搜索概念,探索了使用基于概率的有限状态机模型实现集群自主决策的解决方案,并通过案例进行了分
智码逐影人
•
3个月前
雷池 WAF 配置教程:小白学规则编写,用 Nginx 护住 WordPress 博客
作为刚学WordPress的小白,我之前总觉得“规则编写”是专业运维的专利,直到自己的博客被垃圾评论刷屏、后台遭频繁登录尝试后才意识到——哪怕是个人博客,也需要定制化的防护规则。跟着雷池WAF的配置教程学规则编写后,我不仅解决了博客的安全问题,还对Web防
1
•••
18
19
20
•••
158