
一、ElasticSearch是什么?
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
二、Docker 部署 ElasticSearch
2.1 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.3.2 2.2 运行容器
ElasticSearch的默认端口是9200,我们把宿主环境9200端口映射到Docker容器中的9200端口,就可以访问到Docker容器中的ElasticSearch服务了,同时我们把这个容器命名为es。
docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.3.2 2.3 配置跨域
2.3.1 进入容器
由于要进行配置,因此需要进入容器当中修改相应的配置信息。
docker exec -it es /bin/bash 2.3.2 进行配置
# 显示文件
ls
结果如下:
LICENSE.txt README.textile config lib modules
NOTICE.txt bin data logs plugins
# 进入配置文件夹
cd config
# 显示文件
ls
结果如下:
elasticsearch.keystore ingest-geoip log4j2.properties roles.yml users_roles
elasticsearch.yml jvm.options role_mapping.yml users
# 修改配置文件
vi elasticsearch.yml
# 加入跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*" 2.3 重启容器
由于修改了配置,因此需要重启ElasticSearch容器。
docker restart es 展示如下: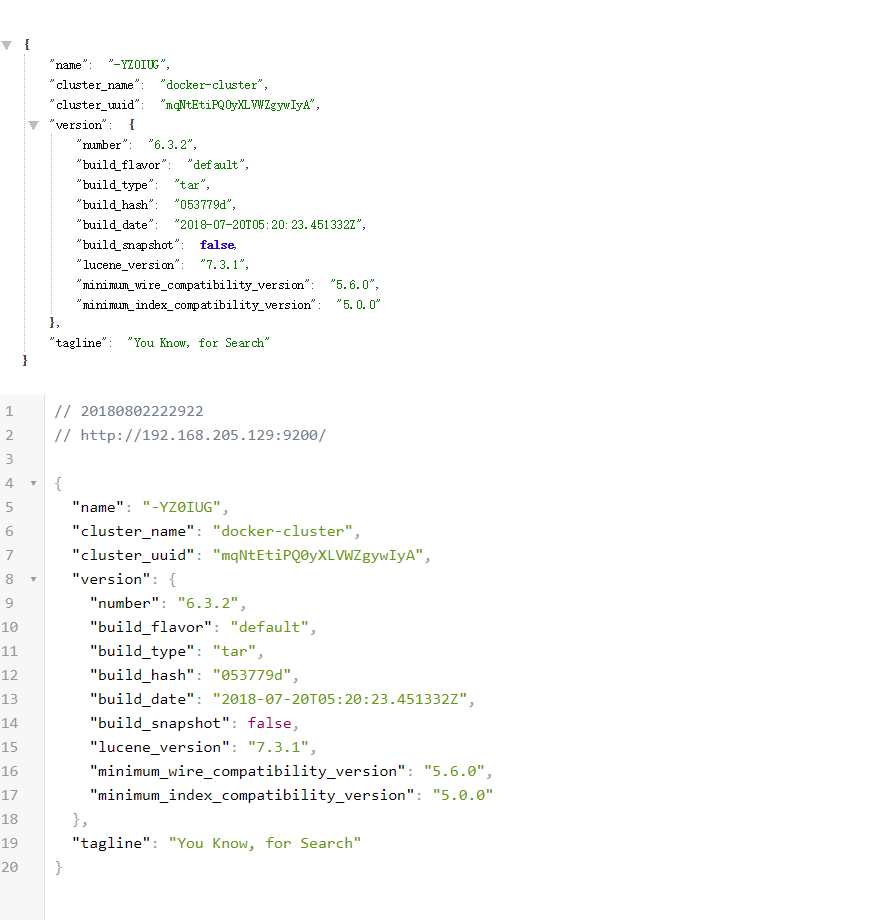
三、Docker 部署 ElasticSearch-Head
为什么要安装ElasticSearch-Head呢,原因是需要有一个管理界面进行查看ElasticSearch相关信息
3.1 拉取镜像
docker pull mobz/elasticsearch-head:5 3.2 运行容器
docker run -d --name es_admin -p 9100:9100 mobz/elasticsearch-head:5 展示如下: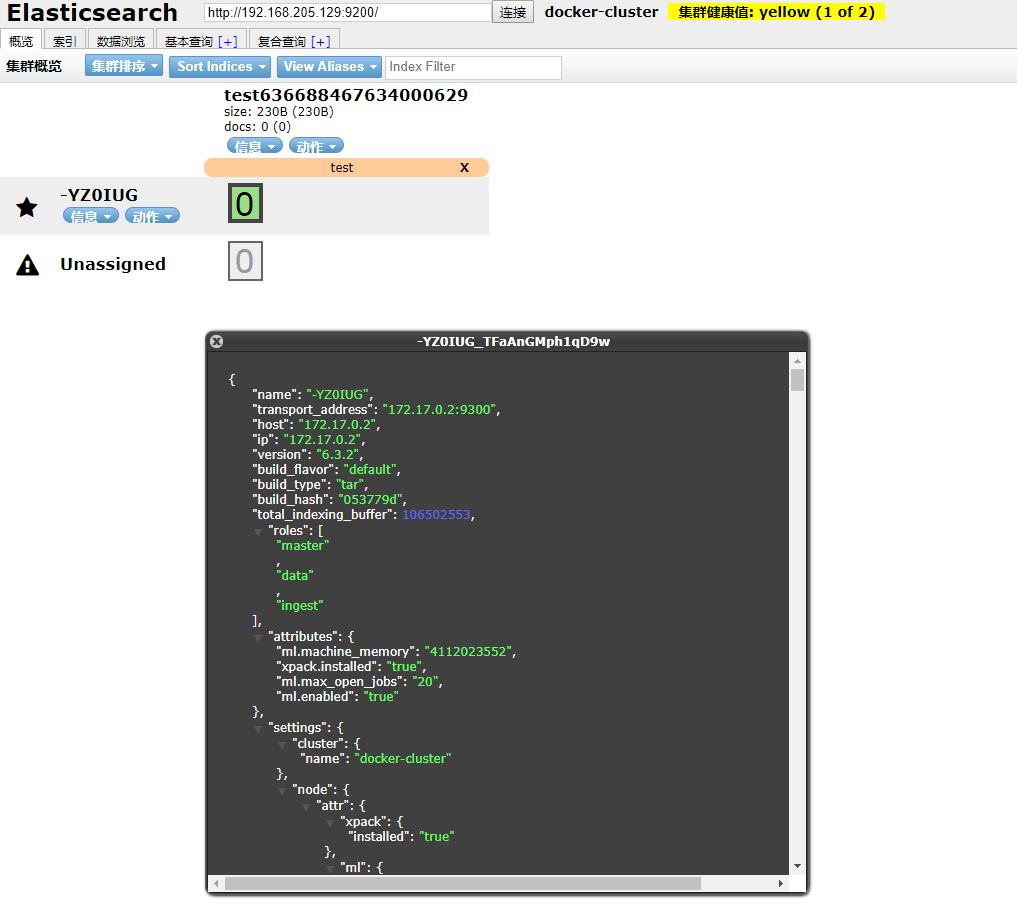
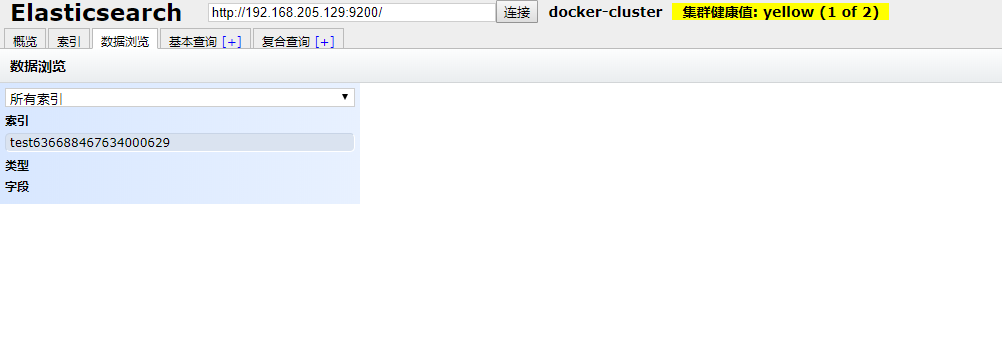
这样,我们就完成了用Docker提供Elasticsearch服务,而不污染宿主机环境了,这样还有一个好处,如果想同时启动多个不同版本的Elastcsearch或者其他服务,Docker也是一个理想的解决方案。













