推荐
专栏
教程
课程
飞鹅
本次共找到7663条
华为云服务
相关的信息
Aidan075
•
4年前
收藏这些API,获取网易云音乐数据超轻松
汇总了常见的网易云音乐API,墙裂建议点击右上角收藏下面是常见的网易云音乐get请求的API。简单介绍一下它们:评论http://music.163.com/api/v1/resource/comments/RSO4歌曲ID?limit20&offset0这应该是最最最常见的了,毕竟80%的网易云音乐的爬虫/数据分析文章都是关于评论数据使用技
天翼云开发者社区
•
3年前
云行 | 加码算力网络布局,天翼云发布南京3AZ节点
9月20日,以“乘云共上融绘新篇”为主题的2022天翼云(https://click.ctyun.cn?tracksource_bkmedium_cpscontent_se460893)中国行·江苏站活动暨南京3AZ发布会在南京成功举办。江
Wesley13
•
4年前
CNCF的云原生景观简介
当你在研究云原生应用程序和技术,则可能会看到过云原生基金会(CNCF)提供的云原生景观图。毫不奇怪,它的规模相当庞大。如此众多的类别和众多的技术。我们应该如何看待它?与其他任何复杂事物一样,如果你并对其进行拆分并分析,你会发现它并不那么复杂。实际上,云原生景观图是按功能整齐地组织的,一旦你了解了每个类别所代表的内容,就可以轻松进行“导航”。在本系列的
天翼云开发者社区
•
3年前
实战天翼云云主机系统盘扩容
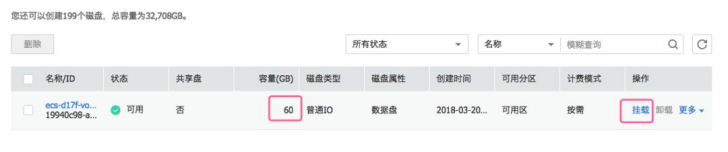
天翼云云主机默认提供的系统盘容量是40G,已经能适应于绝大多数场景。但在一些特殊场景下默认的40G系统盘空间不够,必须要扩大系统盘。这时候该如何处理呢?今天就来实战一番。以centos6(下文也适应于centos7)操作系统为例,我们使用ssh登录到云主机,使用 partedl 命令查看一下现在的分区情况。5、云主机开机回到弹性云主机页面,对云主机执行开机
天翼云开发者社区
•
3年前
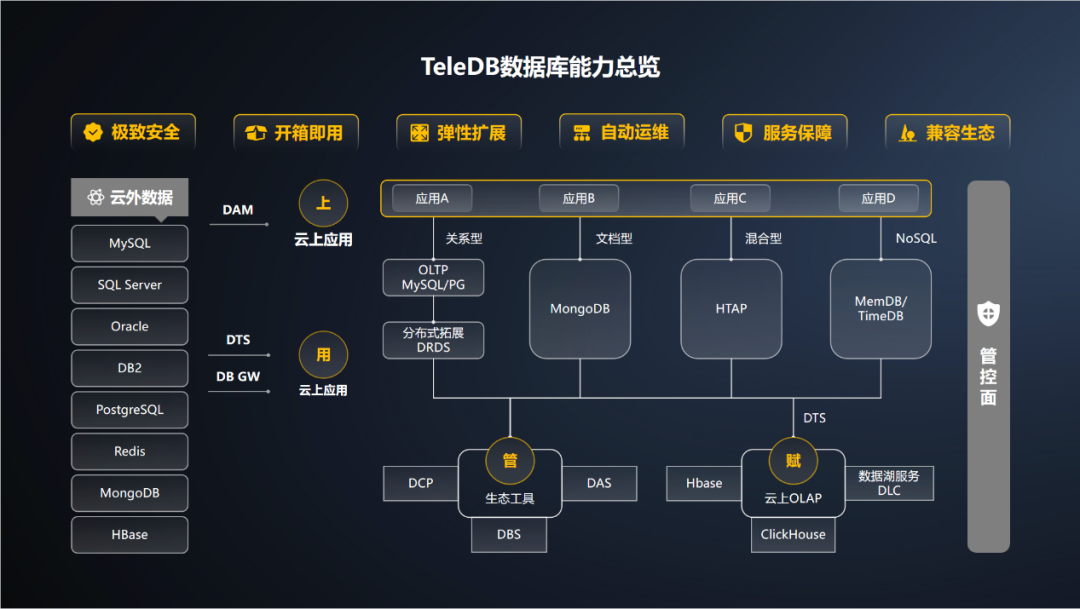
驭数有道,天翼云TeleDB系列产品全新升级
8月16日,以“红云天翼安全普惠”为主题的天翼云TeleDB系列产品升级发布会在线上顺利举办。此次发布的天翼云自主研发云原生数据库实现了全新升级,推出一站式HTAP融合数据库,以及TeleDB数据库容灾双活方案,展示了TeleDB数据库的可用性、易用性、安全性、云原生、容灾等能力,以及其在各行业领域的实践成果。国产化数据库高速发展核心技术自主可控是关键Ga
京东云开发者
•
2年前
一份保姆级的Stable Diffusion部署教程,开启你的炼丹之路 | 京东云技术团队
在经历了一系列的探索后,我为你总结出了一套零基础的、非常好上手的借助京东云GPU云主机部署安装StableDiffusionWebUI以及相关工具和插件的保姆集教程,请查收。
天翼云开发者社区
•
1年前
新格局,新生态!天翼云以国云智算底座赋能AI产业发展!
近日,中国云产业联盟暨中关村云计算产业联盟(以下简称“云联盟”)主办的“首届AIGC全网小程序应用创新大会暨云联盟・移动应用专业委员会成立发布会”在中关村国家自主创新示范区展示中心圆满召开。本次峰会以“AIGC激荡全网·小程序重塑新格局”为主题,邀请AI各领域高潜力企业、知名投资人、政府及学界代表、小程序相关企业负责人相聚一堂,站在AIGC新起点上,探讨小程序的应用创新,深度剖析AIGC技术带来的新场景、新应用、新机遇。
天翼云开发者社区
•
1年前
解锁数据潜力,天翼云TeleDB为企业数智蝶变添力赋能!
近日,第15届中国数据库技术大会(DTCC2024)在北京召开。大会以“自研创新数智未来”为主题,重点围绕向量数据库与向量检索技术实践、数据治理与数据资产管理、云原生数据库开发与实践、特定场景下的数据库管理与优化、大数据平台建设等内容展开分享和探讨。天翼云数据库产品线首席技术官李跃森、天翼云资深研发专家胡彬参会,分享了天翼云在数据库领域的产品布局、技术创新与实践应用。
天翼云开发者社区
•
3年前
数聚生态,智驭全界!看天翼云如何为智慧园区注入新动能!
7月30日,“数聚生态智驭全界——5G天翼云AI数字化转型智慧园区”天翼云(https://click.ctyun.cn?tracksource_bkemedium_cpscontent_se460893)中国行活动在上海顺利召开。中
1
•••
114
115
116
•••
767