推荐
专栏
教程
课程
飞鹅
本次共找到1995条
分布式算法
相关的信息
Wesley13
•
4年前
SQL优化器原理
摘要:在MaxCompute中,Join操作符的实现算法之一名为"HashJoin",其实现原理是,把小表的数据全部读入内存中,并拷贝多份分发到大表数据所在机器,在map阶段直接扫描大表数据与内存中的小表数据进行匹配。 这是MaxCompute有关SQL优化器原理的系列文章之一。我们会陆续推出SQL优化器有关优化规则和框架
Wesley13
•
4年前
Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fblog.csdn.net%2Fpipisorry%2Farticle%2Fdetails%2F53257188)弹性分布
Jacquelyn38
•
4年前
手把手教你实现一个Vue无限级联树形表格(增删改)
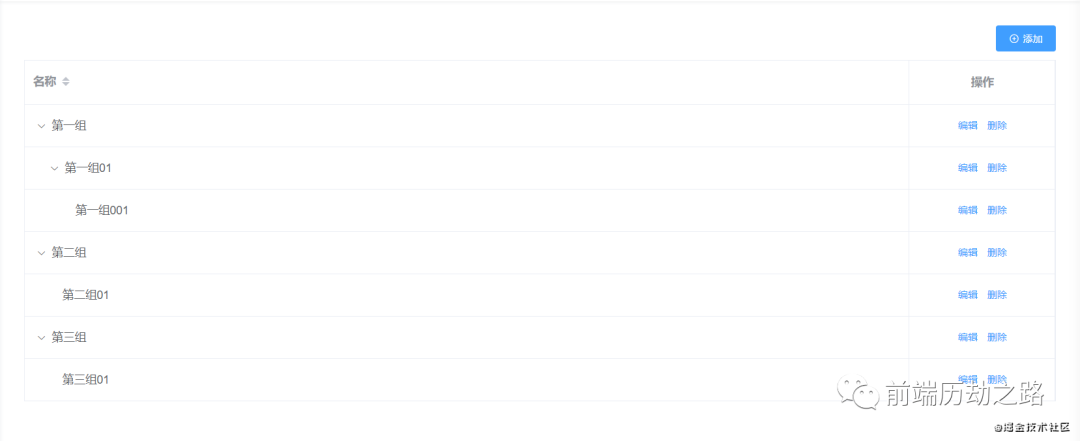
前言平时我们可能在做项目时,会遇到一个业务逻辑。实现一个无限级联树形表格,什么叫做无限级联树形表格呢?就是下图所展示的内容,有一个祖元素,然后下面可能有很多子孙元素,你可以实现添加、编辑、删除这样几个功能。资源JavaScript框架:vue.jsUI框架:ElementUI源码这里需要重点说明的是,主要使用了递归的算法以及给数
Stella981
•
4年前
SparkSql学习1 —— 借助SQlite数据库分析2000万数据
总所周知,Spark在内存计算领域非常强势,是未来计算的方向。Spark支持类Sql的语法,方便我们对DataFrame的数据进行统计操作。但是,作为初学者,我们今天暂且不讨论Spark的用法。我给自己提出了一个有意思的思维游戏:Java里面的随机数算法真的是随机的吗?好,思路如下:1\.取样,利用Java代码随机生成2000万条01
Stella981
•
4年前
Spring Boot + Spring Cloud 构建微服务系统(八):分布式链路追踪(Sleuth、Zipkin)
技术背景在微服务架构中,随着业务发展,系统拆分导致系统调用链路愈发复杂,一个看似简单的前端请求可能最终需要调用很多次后端服务才能完成,那么当整个请求出现问题时,我们很难得知到底是哪个服务出了问题导致的,这时就需要解决一个问题,如何快速定位服务故障点,于是,分布式系统调用链追踪技术就此诞生了。ZipKinZipkin是一个
Wesley13
•
4年前
Java Opencv 实现细化 二值化
1.用OpenCV验证腐蚀和膨胀,只需截图回复。具体做法可参考何东健课件和源代码的第6章或其他资源。2.用OpenCV验证细化,只需截图回复。具体做法可参考何东健课件和源代码的第6章或其他资源。3.其他方法,可先了解基本原理,数学推导知道即可。算法理论文章:https://blog.csdn.net/baidu\_2157855
Wesley13
•
4年前
Mysql 表分区分类
针对Mysql数据库,表分区类型简析。【1】表分区类型(1)Range分区:按范围分区。按列值的范围区间进行分区存储;比如:id小于10存储在一个分区;id大于10小于20存储在另外一个分区;(2)List分区:按离散值集合分区。与range分区类似,不过它是按离散值进行分区。(3)Hash分区:按hash算法结果分区。对用户定义的表达式所返
Stella981
•
4年前
SpringBoot 2,用200行代码完成一个一二级分布式缓存
缓存系统的用来代替直接访问数据库,用来提升系统性能,减小数据库负载。早期缓存跟系统在一个虚拟机里,这样内存访问,速度最快。后来应用系统水平扩展,缓存作为一个独立系统存在,如redis,但是每次从缓存获取数据,都还是要通过网络访问才能获取,效率相对于早先从内存里获取,还是不够逆天快。如果一个应用,比如传统的企业应用,一次页面显示,要访问数次redis,那效果
京东云开发者
•
2年前
分布式数据库 Join 查询设计与实现浅析 | 京东云技术团队
文章从常用的关系型数据库MySQL的分库分表Join分析,再到非关系型ElasticSearch来分析Join实现策略。逐步深入Join的实现机制。
1
•••
155
156
157
•••
200