推荐
专栏
教程
课程
飞鹅
本次共找到1294条
内存带宽
相关的信息
爱写码
•
4年前
国产开源网络编程框架t-io的炸裂性能介绍之30W长连接并发
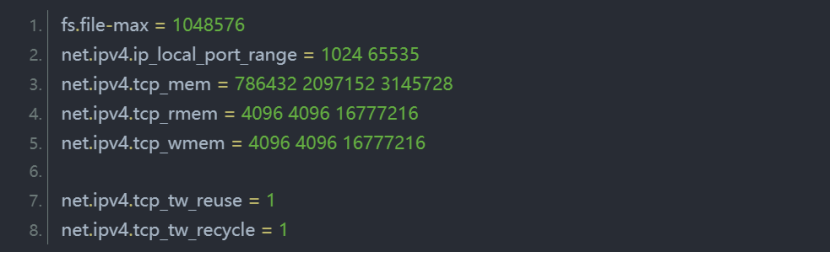
tio的性能用炸裂来形容,一点都毫不夸张,请各位大拿仔细阅读下面的内容,想你们心里有数。具体请参考:准备工作操作系统Ubuntu12在/etc/sysctl.conf中添加如下配置:在/etc/security/limits.conf中添加如下配置:最后使用ulimitan查询设置是否生效。测试主机cpu:内存:客户端测试机用VMware创建12台虚拟
京东云开发者
•
2年前
Bitmap、RoaringBitmap原理分析
在处理海量大数据时,我们常常会使用Bitmap,但假如现在要向Bitmap内存入两个pin对应的偏移量,一个偏移量为1,另一个偏移量为100w,那么Bitmap存储直接需要100wbit的空间吗?数据部将偏移量存入Bitmap时,又如何解决数据稀疏问题呢?本文将为大家解答
Stella981
•
4年前
Redis 子进程开销监控和优化方式
Redis子进程负责AOF或者RDB文件的重写,它的运行过程主要涉及CPU、内存、硬盘三部分的消耗01 CPUCPU开销分析。子进程负责把进程内的数据分批写入文件,这个过程属于CPU密集操作,通常子进程对单核CPU利用率接近90%CPU消耗优化。Redis是CPU密集型服务,不要做绑定单核CPU操作。由于子进程非常消耗
Stella981
•
4年前
Django的原生NoSQL支持
今天在豆瓣小组里看到了一个关于djangononrel的帖子,通过回帖发现好多人对这个项目乃至整个Django社区的消息都非常滞后。比如有人还在以为djangononrel能merge到Django的官方代码里……实在是看不下去了以后我就回帖了:\djangononrel的实现是采用在内存里模拟SQL数据库操作的方式,尤其是
Stella981
•
4年前
Dask教程
Dask介绍Dask是一款用于分析计算的灵活并行计算库。Dask由两部分组成:针对计算优化的动态任务调度。这与Airflow,Luigi,Celery或Make类似,但针对交互式计算工作负载进行了优化。“大数据”集合,像并行数组,数据框和列表一样,它们将通用接口(如NumPy,Pandas或Python迭代器)扩展到大于内存或分
Wesley13
•
4年前
Java性能调优:利用JMC进行性能分析
JMC,即Java任务控制(JavaMissionControl)是从Java7(7u40)和 Java8 的商业版本包括一项新的监控和控制特性。JMC程序 (JDK\_HOME\\bin目录下) 会启动一个窗口程序,然后让我们选择对那进程进行监控,JMC打开性能日志后,主要包括7部分性能报告,分别是一般信息、内存、代码、线程、I/O、系统、
Easter79
•
4年前
TF实战丨使用Vagrant安装Tungsten Fabric
本文为苏宁网络架构师陈刚的原创文章。01准备测试机在16G的笔记本没跑起来,就干脆拼凑了一台游戏工作室级别的机器:双路E52860v3CPU,24核48线程,128GDDR4ECC内存,NVME盘512G。在上面开5个VM,假装是物理服务器。·192.16.35.110deployer·192.16.35.11
Stella981
•
4年前
JVM垃圾收集调优案例
简介通过压力测试查看xwiki的gc情况,统计分析gc日志,在不改变总内存使用的情况下做出合理调整,通过压力测试聚合报告对比调优效果。步骤1.运行程序,增加打印GC日志的参数;2.使用badboyjmeter对web程序的单个页面(首页)进行压力测试,压力测试参数为10线程,每线程执行100次测试;3.使用js
Wesley13
•
4年前
Mysql基本操作
什么是数据库用来存储数据的仓库数据库可以在硬盘及内存中存储数据数据库与文件存储数据区别数据库本质也是通过文件来存储数据,数据库的概念就是系统的管理存储数据的文件数据库介绍数据库服务器端:存放数据库的主机集群数据库客户端:可以
京东云开发者
•
2年前
浅析JVM GC配置指南 | 京东云技术团队
本文旨在简明扼要说明各回收器调优参数,如有疏漏欢迎指正。1、JDK版本以下所有优化全部基于JDK8版本,强烈建议低版本升级到JDK8,并尽可能使用update191以后版本。2、如何选择垃圾回收器响应优先应用:面向C端对响应时间敏感的应用,堆内存8G以上建
1
•••
107
108
109
•••
130