
transformers的近期工作成果综述 基于 transformer 的双向编码器表示(BERT)和微软的图灵自然语言生成(T-NLG)等模型已经在机器学习世界中广泛的用于自然语言处理(NLP)任务,如机器翻译、文本摘要、问题回答、蛋白质折叠预测,甚至图像处理任务。
在本文中,对基于transformer 的工作成果做了一个简单的总结,将最新的transformer 研究成果(特别是在2021年和2022年发表的研究成果)进行详细的调研。
这张图与一篇调查论文[Tay 2022]中的图相似,但被调transformers会更新并且它们的整体分类也有很大的不同。
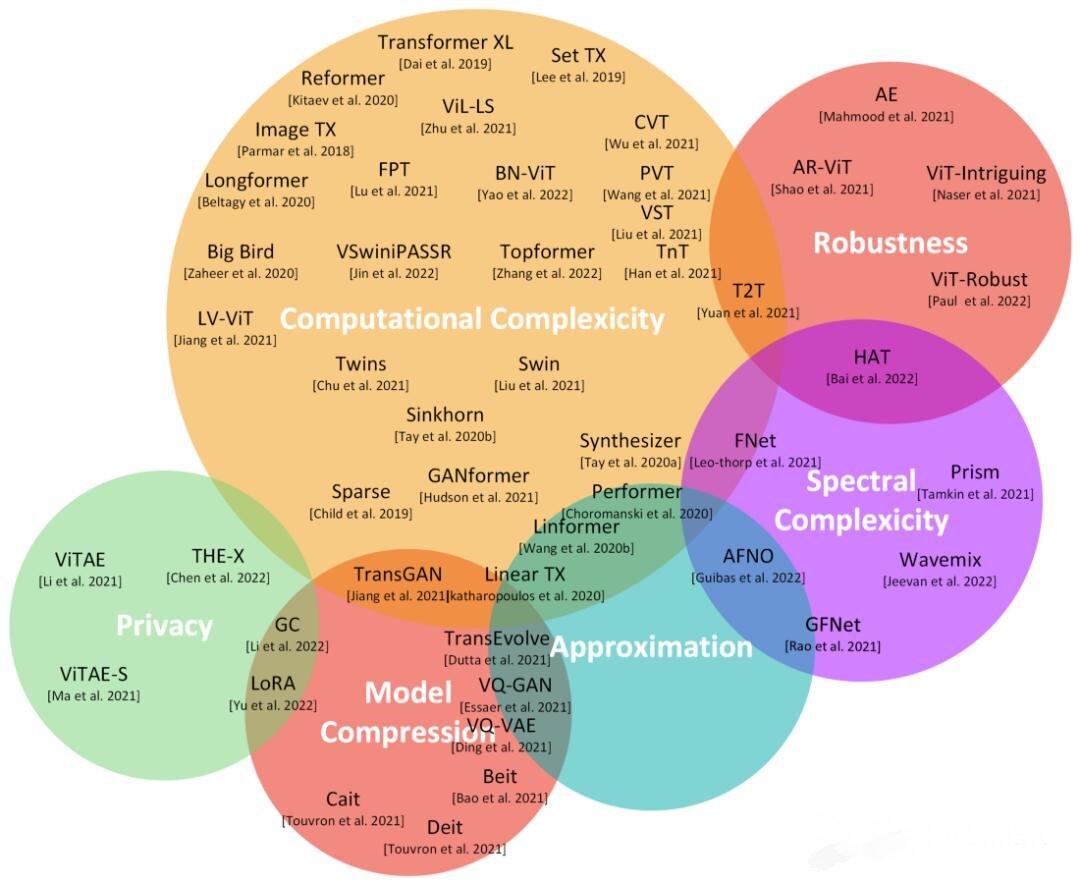
如图所示,主要类别包括计算复杂度、鲁棒性、隐私性、近似性和模型压缩等等。本文文字和专业术语较多,并且均翻译自论文原文,如有错误(很可能)请谅解。
计算复杂度 一些研究方向是以各种方式解决transformer的O(N2)计算复杂度。transformer的关键问题之一是它与输入序列长度相关的二次复杂度。这意味着我们必须为每一层和注意头计算N*N个注意矩阵。人们尝试了各种方法来降低这种O(N2)复杂度,包括使用缓存体系结构。
Sparse transformer是解决这种复杂性的流行方法之一。每个输出位置从输入位置的一个子集计算权重。如果子集是√(N),那么transformer的复杂度降低到O(N *√(N)),并允许它处理更大范围的依赖关系。
Longformer使用了带窗口的局部注意力(对于窗口大小为w的窗口,每个令牌会注意到两边的w/2个令牌,而不是整个输入)并且使用特殊令牌的任务驱动的全局注意力进行组合。
另一项被称为BigBird [Manzil 2020]的工作使用了图稀疏化技术。它使用一种称为Watts-Strogatz图的特殊图,它近似于一个完整的图可以实现输入序列的线性复杂度。作者表明在标准精度假设下,BigBird是图灵完备的。他们还评估BigBird在远距离依赖的任务上的表现,特别是在提取基因组序列(如DNA)和预测结果染色质谱方面
Linformer使用线性投影和低秩因子分解的组合逼近点积注意运算[Wang2020]。
上面许多基于稀疏矩阵操作的transformer可能需要稀疏矩阵乘法操作,这种方式并不是在所有体系结构上都可用。他们也倾向于堆叠更多的注意力层来弥补稀疏性,从而导致总体上的算力的增加。对于某些操作,如softmax操作也可能不容易;还有多项式probit运算也不容易稀疏化。
谷歌提出了一个广义注意框架Performer,可以根据不同的相似性度量或内核来指定广泛的注意力机制。他们通过积极的正交随机特征(Favor+)算法来实现注意力的机制。他们还表明可以通过指数函数和随机高斯投影的组合来近似普通的softmax注意。Performer在蛋白质序列预测任务等方面优于标准模型。
Wang等[Wang 2021]提出了一种用于无卷积的密集预测的金字塔视觉transformer(PVT)。这一问题克服了基于VIT的模型在将密集的预测任务时遇到了困难,PVT有助于各种像素级密度预测,并且不需要卷积和非最大抑制,如目标检测方法。采用渐进式收缩金字塔和空间减少注意力可以很容易地连接transformer。最后在图像分类、目标检测、实例和语义分割等任务中PVT也是可用的。
Liu等人[Liu 2021]讨论了transformer从语言领域到视觉领域的适应问题,方法包括大量视觉实体的差异和与文本中的文字相比的图像的高分辨率像素差异。为了解决这个问题,作者提出了Swin Transformer [Lui 2021],这是一种分层方法,其表示是使用移位窗口计算。该技术更有效地克服了自注意力局部窗口不重叠的问题。
Chu等人[Chu 2021]讨论了空间注意对于transformer在各种任务中的性能成功的重要性。作者提出了两个简单而高效的体系结构:twin - pcpvt和twin - svt。twin -pcpvt使用可分离的深度卷积注意机(depth-wise convolution attention machine),又被称为空间分离自注意力(spatial-separable self-attention - SSSA)。SSSA使用两种类型的注意力操作:本地分组的自注意力(LSA)和全局次采样的注意力(GSA)。LSA处理细粒度和短距离信息,而GSA则处理长距离序列和全局信息。另一个方法twin - svt同时使用LSA和带有矩阵乘法的GSA。
光谱的复杂性 通过将自注意网络替换为混合输入令牌的线性转换,可以设计高效的transformer来加速编码器架构。transformer的自注意层被参数化的傅里叶变换(Fnet)取代[Lee-Thorp 2022],然后是一个非线性和前馈网络。与BERT相比,该网络速度快80%,可以达到传统transformer性能的92%到97%。
The Global Frequency network(GFnet) [Rao 2022]提出了一种用于令牌混合的深度全局卷积。GFnet涉及三个步骤:通过快速傅里叶变换(FFT)进行空间令牌混合、频率门控和反FFT进行令牌分解。GFnet不涉及信道混合,随着序列长度的增加,对于高像素的图像来说消耗非常大,而且不具有自适应能力。
Guibias等人[Guibias 2022]将令牌混合任务定义为一种操作符学习任务,该任务是学习在无限尺寸空间中连续函数之间的映射。Li等人[Li 2020]讨论了使用傅里叶神经算符(FNO)求解偏微分方程(PDE)。FNO在连续域中工作良好。
将FNO应用于高分辨率图像输入的视觉域,需要对PDE的FNO设计体系结构进行修改。这是因为高分辨路图像由于边缘和其他结构而具有不连续性。信道混合FNO与信道大小有关,具有二次复杂度。信道混合权重采用块对角线结构来解决信道混合问题。作者在MLP层的令牌之间共享权重以提高参数效率,并使用软阈值在频域引入稀疏性以进行泛化。这些解决方案结合称为自适应傅里叶神经算子(AFNO)。
Bai等人[Bai 2022]提出了HAT方法(High-frequency components via Adversarial Training),该方法在训练阶段对组件进行高频扰动。HAT方法通过添加对抗性扰动改变训练图像的高频成分,然后用改变后的图像训练ViT [Bai 2022]模型,这样可以提高模型性能,使模型更鲁棒。
鲁棒性 Shao等[Shao 2021]利分析了transformer模型的鲁棒性。作者使用白盒攻击进行了一个实验。他们观察到与卷积神经网络(CNNs)相比,ViT具有更好的对抗鲁棒性。ViT特征包含低层信息,对对抗攻击提供了优越的鲁棒性,并指出与增加尺寸或增加层数的纯transformer模型相比,cnn和transformer的组合具有更好的鲁棒性。他们还发现预训练更大的数据集并不能提高鲁棒性。对于一个稳健的模型,情况正好相反。
Bhojanapalli等人[Bhojanapalli 2021]调查了ViT模型和resnet模型针对对抗实例、自然实例和常见破坏的各种鲁棒性度量。作者研究了对输入和模型扰动的鲁棒性。无论是从输入还是从模型中去除任何一层,transformer都是鲁棒的。
Paul等人[Paul 2022]研究了ViT [Dosovitskiy 2020]、cnn和Big Transformer[Kolesnikov 2020]方法的鲁棒性。Paul等人[Paul 2022]在ImageNet数据集上对ViTs的鲁棒性进行了基准测试。结果在表r中。通过6个实验,作者验证了与CNN和Big Transformer相比,ViT在鲁棒性方面有了提高。这些实验的结果包括:
实验1:注意力是提高鲁棒性的关键。
实验2:预训练的作用很重要。
实验3:ViT对图像遮蔽具有较好的鲁棒性。
实验4:傅里叶频谱分析显示ViT的灵敏度较低。
实验5:对抗性扰动在能量谱中扩散得更广。
实验6:ViT对输入扰动有更平滑的损失。

根据Park等人[Park 2022]的研究,与cnn相比ViT [Dosovitskiy 2020]在捕获图像高频成分方面的效率较低。HAT [Bai 2022]是对现有transformer模型在频率角度的影响进行进一步研究的结果。HAT使用RandAugment方法对输入图像的进行高频分量扰动。Wu等人[Wu 2022]研究了易受对抗实例影响的transformer模型的问题。这个问题(对对抗性噪声的脆弱性)在cnn中是通过对抗性训练来处理的。但在transformer中,由于自注意计算的二次复杂度,对抗训练的计算成本很高。AGAT方法采用了一种有效的注意引导对抗机制,在对抗训练过程中使用注意引导下降策略去除每一层嵌入的确定性补丁。
隐私 预训练的transformer模型部署在云上。基于云的模型部署中的一个主要问题与数据中隐私问题有关。主要的隐私问题是用户数据(如搜索历史、医疗记录和银行账户)的暴露。目前的研究重点是在transformer模型推理中保护隐私。
论文[Huang 2020]介绍了TextHide,一种保护隐私的联邦学习技术,但这种方法适用于基于句子的任务,如机器翻译、情绪分析、转述生成任务),而不是基于令牌的任务(如名称实体识别和语义角色标记)。
DP-finetune [Kerrigan 2020]差分隐私(DP)方法允许量化保护数据敏感性的程度。但是训练DP算法会降低模型的质量,但是可以在私有数据集上使用公共基础模型进行调优来部分解决。
Gentry等人[Gentry 2009]提出了一种用homomorphic encryption(HE)中的密文保护隐私的方法。但是transformer的模型中GELU [Hendrycks 2016]激活的计算复杂性,HE解决方案只支持加法和乘法。
论文[Chen 2022]在transformer中基于HE [Boemer 2019, Boemer 2020]的解上提出了一种通过级数逼近的The - x方法。the - x方法在SoftMax和GELU等层的帮助下,用一系列近似代替非多项式操作,去掉池器层,添加归一化层,使用知识蒸馏技术。THE-X方法使用BERT-Tiny Model进行评估[Wang 2018],并对CONLL2003 [Sang2003]任务进行了基准测试。
Li等人[Li 2022]使用差分隐私算法解决了性能下降和高计算开销的问题。这样可以使用更大的预训练语言模型来处理,也可以通过在中等语料库上使用DP优化进行微调的对齐预训练过程来进行微调。
近似性 论文[Ruthotto 2019]是最早为ResNets等深度神经网络提供基于偏微分方程(PDEs)的理论基础的论文之一。更具体地说,作者证明了残差cnn可以解释为时空微分方程的离散化。在理论表征的基础上,Ruthotto还提出了具有特殊性质的双曲和抛物线cnn等新模型。
残差网络也被解释为常微分方程的欧拉离散化。但欧拉法求解精度不高,由于是一阶方法,存在截断误差。ODE Transformers [Bei 2022]的作者使用了经典的高阶方法(Runge Kutta)来构建Transformer块。他们在三个序列生成任务上评估了ODE Transformers 。这些任务证明了ODE是有效的,包括抽象摘要、机器翻译和语法纠正。在这个方向上的另一项努力是TransEvolve [Dutta 2021],它提供了一个Transformer架构,与ODE类似,但以多粒子动态系统为模型。
Transformers 已经被证明相当于通用计算引擎[Kevin 2022]。作者提出了一种称为Frozen pretrain transformer (FPT)的结构,它可以在单一模态(如用于语言建模的文本数据)上进行训练,并识别跨模态有用的抽象(如特征表示)。他们采用GPT,只对自然语言数据进行预训练,并对其输入和输出层以及层归一化参数和位置嵌入进行微调。这使得FPT在完成蛋白质折叠预测、数值计算甚至图像分类等各种任务时,可以与完全从零开始训练的transformer进行比较。
模型压缩
Touvron等人[Touvron 2021]提出了一种基于蒸馏技术(Deit)的高效transformer模型。它使用一种依赖于蒸馏令牌的师生策略,以确保学生通过注意力从老师那里学习。
Bao等人[Bao 2021]向预训练的VIT提出了一个遮蔽图像模型任务。作者提出了一种基于自监督的视觉表示模型,即来自图像transformer的双向编码器表示(BEiT),它遵循了为自然语言处理领域开发的BERT [Kenton 2019]方法。在这种方法中,每个图像被认为是两个视图:一个是大小为16 x 16像素的图像补丁,另一个是离散的可视标记。将原始图像标记为可视标记,并对部分图像补丁进行随机掩码,然后将其馈送给预训练的骨干transformer。训练BEiT后,模型可以针对下游任务进行微调。
作者:Dr. Vijay Srinivas Agneeswaran
人工智能技术与咨询











