一、背景
社区收藏业务是一个典型的读多写少的场景,社区各种核心Feeds流都需要依赖用户是否收藏的数据判断,早期缓存设计时由于流量不是很大,未体现出明显的问题,近期通过监控平台等相关手段发现了相关的一些问题,因此我们针对这些问题对缓存做了重构设计,以保障收藏业务的性能和稳定性。
二、问题分析定位
2.1 接口RT偏大 通过监控平台查看「判断是否收藏接口」的RT在最高在8ms左右,该接口的主要作用是判断指定单个用户是否已收藏一批内容,其实如果缓存命中率高的话,接口RT就应该趋近于Redis的RT水平,也就是1-2ms左右。
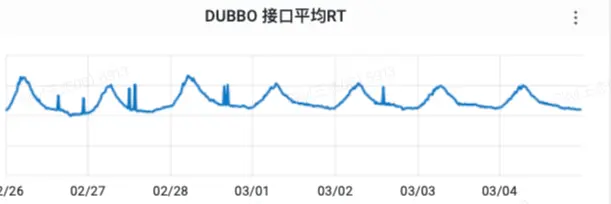
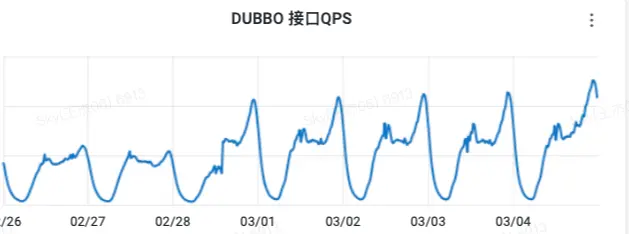
2.2 Redis&MySQL访问QPS偏高
通过监控平台可以看到从上游服务过来的收藏查询QPS相对访问Redis缓存的QPS放大了15倍,并且MySQL查询的最高QPS占上游访问量接近37%,这说明缓存并没有很高的命中率,导致回表查询的概率还是很大。
QPS访问量见下图:
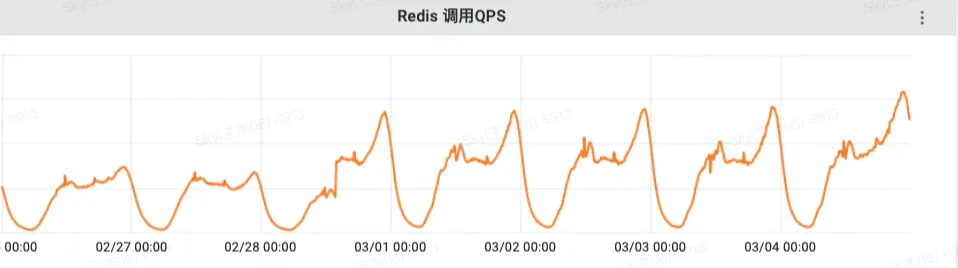
MySQL访问量

基于以上分析我们现在有了明确的优化切入点,接下来我们来看下具体的找下原因是什么。
接下来我们来看一下伪代码的实现:
//判断用户是否对指定的动态收藏
func IsLightContent(userId uint64,contentIds []uint64){
index := userId%20
cacheKey := key + "_" + fmt.Sprintf("%d", index)
pipe := redis.GetClient().Pipeline()
for _, item := range contentIds {
InitCache(userId, contentId)
pipe.SisMember(cacheKey, userId)
}
pipe.Exec()
//......
}
//缓存初始化判断,不存在则初始化数据缓存
func InitCache(userId uint64,contentId uint64){
index := userId%20
cacheKey := key + "_" + fmt.Sprintf("%d", index)
ttl,_ := redis.GetClient().TTL(cacheKey)
if ttl <= 0{//key不存在或者未设置过期时间
// query from db
// sql := "select userId from trendFav where userId%20 = index and content_id = contentId"
// save to redis
}else{
redis.GetClient().Expire(cacheKey,time.Hour()*48)
}
}从上面的伪代码中,我们能够很清晰的看到,该方法会遍历内容id集合,然后对每个内容去查询缓存下来的用户集合,判断该当前用户是否收藏。也就是说缓存设计是按照内容维度和用户1:N来设计的,将单个动态下所有收藏过内容的用户id查出来缓存起来。并且基于大Key的考虑,代码又将用户集合分片成20组。这无疑又再次放大了Redis缓存Key的数量。并且每个Key都使用TTL命令来判断是否过期。这样一来Redis的QPS和缓存Key就会被放大很多倍。
正是由于分片策略+缓存时效短,导致了MySQL查询的QPS居高不下。
三、解决方案
基于以上对问题的分析定位,我们思考的解决思路就是一次接口请求降低Redis查询操作,尽可能减少放大的情况,初步判断有如下两个实现路径:
- 去掉遍历内容查询,改为一次性查询
- 去掉用户集分片存储,改为单Key存储
上游的调用参数用户和内容是一对多的关系,因此要实现的Redis查询也是要满足一对多的关系,那么显而易见我们的缓存应该是按照用户的维度来存储已经收藏过的内容集合。
用户收藏的内容比较少的话,我们很简单的就可以从数据库全部查询出来放在缓存,但如果用户收藏的内容比较多呢,那也会可能造成大Key问题,如果继续分片存储的话又会回到了原来的方案。我们讨论出以下两种方案:
- 方案1. 处理大数据大部分常规思路就是要么分片,要么冷热分离
因为业务逻辑的特点,推荐流下用户看到的内容绝大部份基本都是一年以内的,我们可以缓存用户一年以内的收藏内容,这样就限制了用户收藏的极端数量。如果看到的内容发布超过一年时间,可以用MySQL直接查询,这种场景的case概率是很小的。但仔细考虑了下实现,这个需要依赖业务方,我们需要去查询内容的发布时间,以此来判断是否在我们的缓存内,这样会加重整个接口的逻辑,反而得不偿失,因此该思路很快就被否定了。
- 方案2. 既然不能依赖第三方,就是要从自身拥有的信息上,来能够缓存一部分最热的数据,使得查询能够大范围落到这些数据
我们目前只有内容id,而内容id都是纯数字,数字本身的话可以按照大小来排列。业务查询本身都是最近一段时间的内容,所以查询的内容id都是近期较大的id。那我们可以按照内容id降序排列,取用户收藏过的若干条数据来缓存。只要查询的id都比缓存最小的id大,那么我们就可以只通过缓存来判断出用户是否收藏这些内容了。
示例
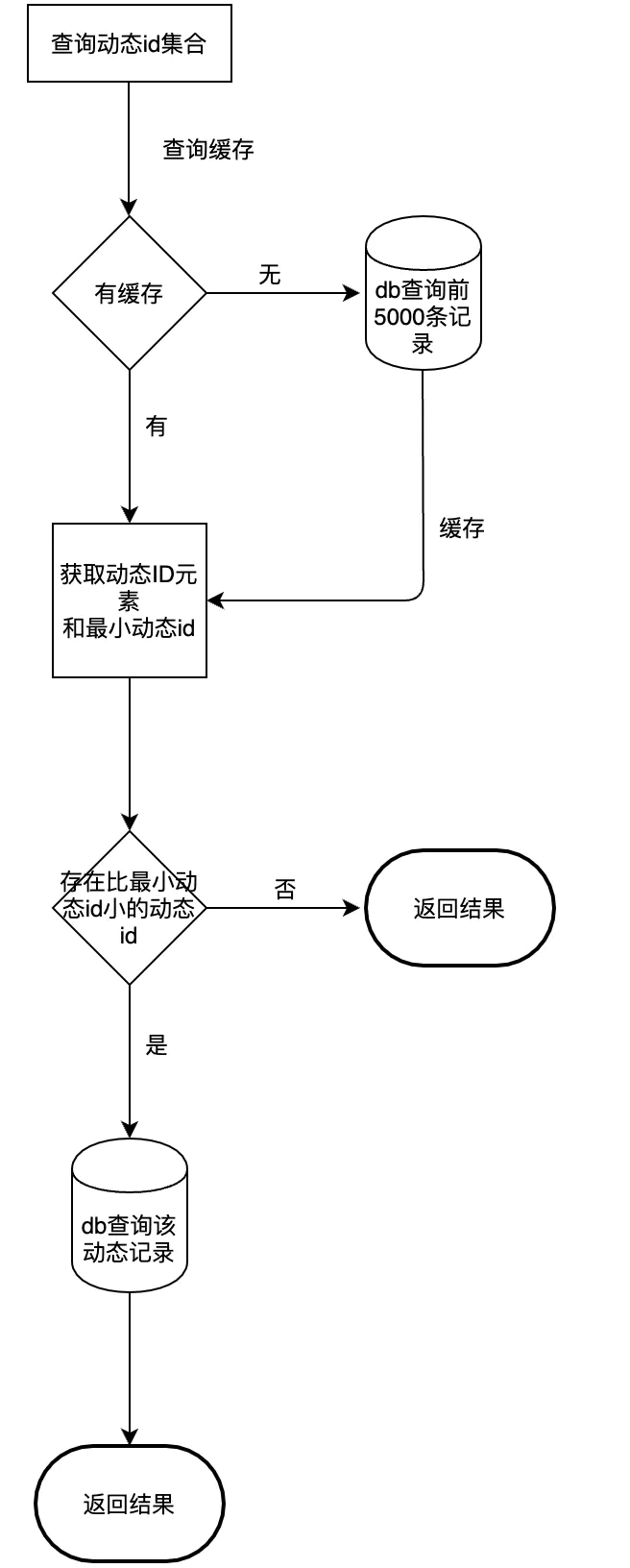
初始化缓存时我们按照内容id降序排列,拿到前5000个内容id:
如果查询结果不满5000,那么这个用户缓存了全部收藏记录,此时小缓存的内容id为0
如果大于等于5000,说明还有部分未缓存的记录,此时最小缓存的内容id为第5000个内容ID
等到查询判断时,将查询的内容id数组和缓存的最小内容id对比,如果全部大于,则说明都在缓存范围内,如果有小于,则是超过缓存范围,届时单独去数据库判断,当然这种概率在业务上的发生几率是比较小的。
这里缓存的数量的抉择显得尤为重要,如果太小,那缓存的命中率不高,导致MySQL回表查询概率变大,如果太大,则初始化时比较耗费时间,或产生大Key问题。经过分析线上数据,目前以5000这个数字能够比较好的权衡。
下面是查询缓存判断流程图:
缓存方式由原来的set结构,改为Hash结构,TTL延长到7 * 24 hour。
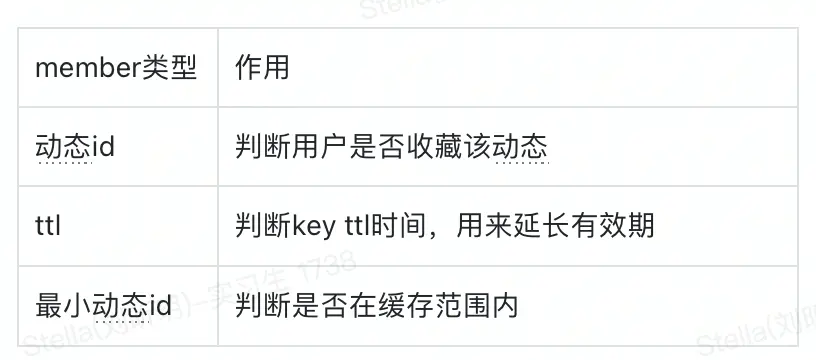
这样一来,原来的独立调用的TTL和sismember命令,可以合并成一个Hmget命令,减少了一半的Redis访问次数,这个改进收益是相当可观的。
四、优化成果
截止本文撰写时,我们对收藏的功能进行了优化改造并上线,取得了很不错的进展。所有数据为最近7天的数据4.14 - 4.20,优化效果在4.15号17点左右开始。
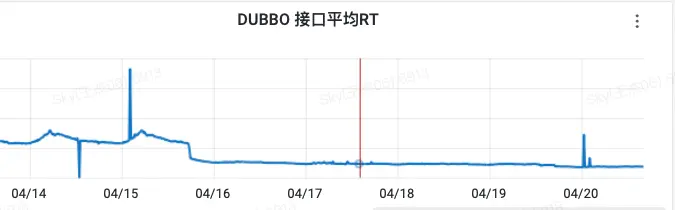
4.1 RPC接口响应RT降低
1 IsCollectionContent
RPC接口,判断动态是否缓存。平均RT提高了接近3倍。并且RT比较稳定
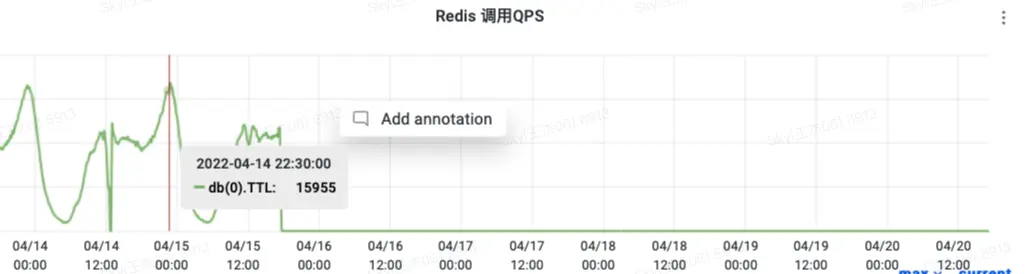
4.2 Redis负载降低
1 TTL 查询
查询Key有效期,用来判断延长Key有效期。QPS直接降到0
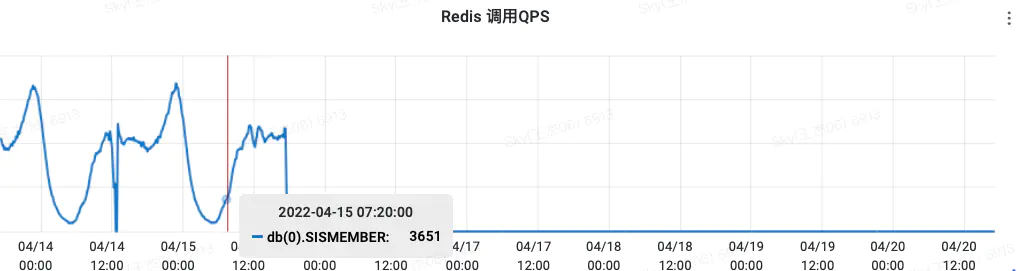
2 SISMEMBER查询
原来旧的收藏缓存查询,已经改为HMGET查询QPS降低到0
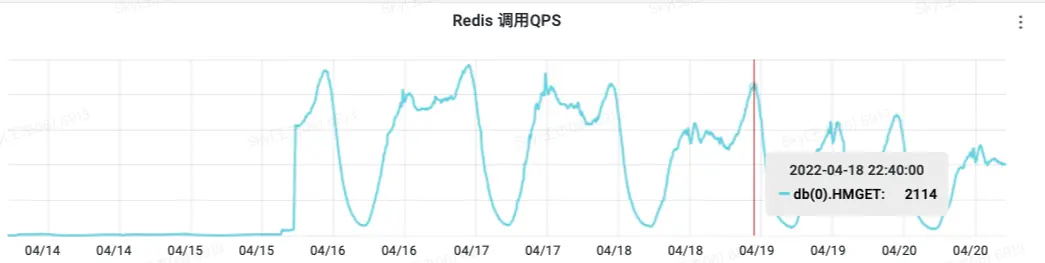
3 HMGET查询
新的收藏缓存查询QPS数量和上游过来查询的QPS正好能对应上
4 Redis 内存降低
新的缓存较旧缓存在占用内存和Key数量这2个指标均降低了3倍左右
4.3 MySQL负载降低
1 content_collection表select查询降低
QPS降低了24倍左右并且保持在一个比较稳定的水位
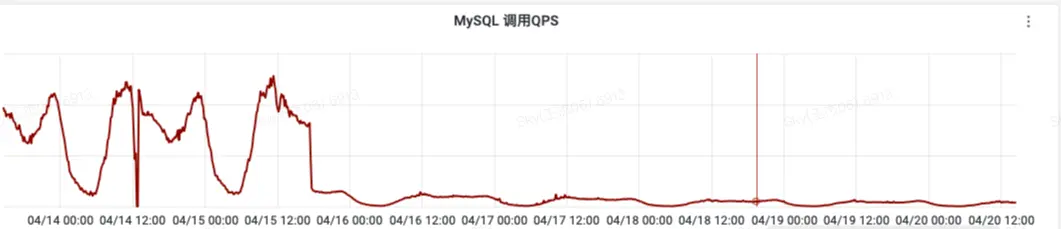
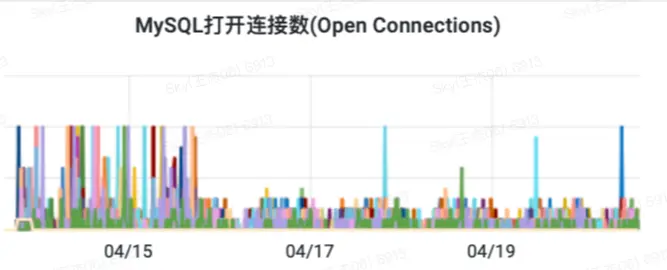
2 MySQL连接并发数降低
查询QPS的减少也降低了并发连接数,大概降低了3倍左右,最终也降低了等待连接次数
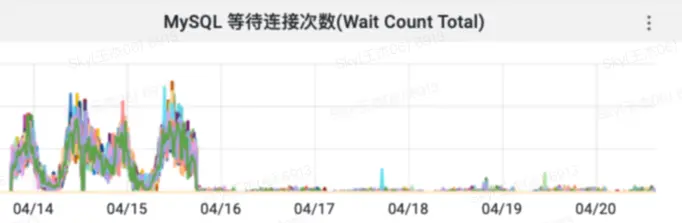
五、总结
经过对本次问题的分析和解决,不难看出一个良好的缓存设计对于服务来说是多么的重要。好的缓存设计不仅能够提升性能,同时可以降低资源使用,整体提升了资源利用率。同时下游的流量和上游基本持平,在流量上升时,不会对下游造成很大的压力,这样服务整体的抗并发能力也提升了很多。