前言
上一章我们从0到1的实现了一颗二叉搜索树,以及理解了二叉搜索树的特性与基本操作,这一章介绍关于二叉树的更多操作,也就是树的遍历,对树的每个节点进行访问。主要包括前序遍历、中序遍历、后序遍历、层序遍历,前面三种也叫深度优先遍历(DFS),最后的层序遍历也叫广度优先遍历(BFS),理解这四种遍历方式的不同,再遇到树相关的算法问题时,也就能更加游刃有余。这里不单指二叉搜索树,遍历思想同样适用于多叉树。
深度优先遍历(DFS)
深度优先顾名思义,首先从树的深度开始,也就是优先访问完其中一棵子树,然后再去访问另一颗子树。树的深度优先里又分为前/中/后序遍历,它们的区别仅仅是当访问到具体的节点时,它们先后顺序的不同。深度优先一般都是采用递归的方式实现,因为好理解,当然也可以使用遍历实现,不过那样会增加代码复杂性以及代码的语义化。(LeetCode上后序遍历的非递归实现可是困难难度)
前序遍历
也就是靠前访问到树的节点,首先贴出代码,给上一章实现的二叉搜索树增加前序遍历的方法:
class BST {
constructor() {
this.root = null // 根节点
}
...
preorder(fn) { // 前序遍历
const _helper = node => {
if (!node) {
return
}
fn(node.val) // 先访问根节点
_helper(node.left) // 再访问左节点
_helper(node.right) // 最后访问右节点
}
_helper(root)
}
} 无论使用哪种遍历方式都是为了访问到树的每个节点,注意上面代码里函数fn的位置,它位于两个递归函数的前面,所以叫它前序遍历;而中序遍历fn就是在两个递归函数的中间;后序遍历fn就是在两个递归函数的后面,它们叫法的由来,也是仅此而已。虽然是这么一点点的区别,然而结果相差挺大且应用方式的区别也很大,首先来看下前序遍历: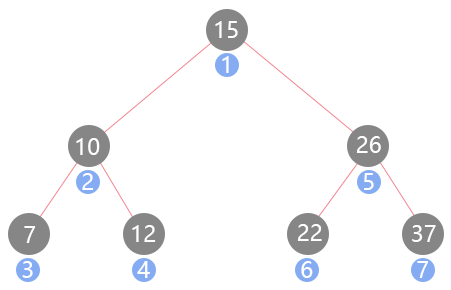
当使用前序遍历时,它的访问顺序是15、10、7、12、26、22、37。它的访问特点是首先访问这棵树的根节点,然后访问它的左子树,最后是访问右子树,这也是看起来比较符合直觉的一种遍历方式。如果还是不太好理解的话,可以将一整颗树分解来理解: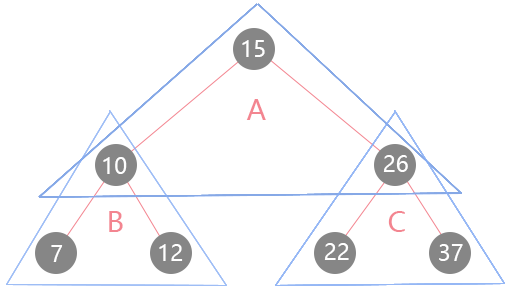
因为是前序遍历,首先遇到子树A,此时它的根节点是15,被访问到。然后去它的左子树B,节点10又是子树B的根节点,所以被访问到。再去节点7与两个null构成的子树,节点7被访问到,因为7的左右孩子都是null,所以返回到父节点10,最后去访问右节点12,整棵树的左子树就访问完了。然后再右子树实行同样的规则进行访问。以此类推也就形成了刚才看到的访问顺序结果,知道它的访问顺序有什么用?那就以一道算法题来看其应用。
前序遍历应用 - 108-将有序数组转换为二叉搜索树
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
一个高度平衡二叉树是指一个二叉树每个节点的左右两个子树的高度差的绝对值不超过 1。
给定有序数组: [-10,-3,0,5,9],一个可能的答案是:[0,-3,9,-10,null,5],
它可以表示下面这个高度平衡二叉搜索树:
0
/ \
-3 9
/ /
-10 5 必须要高度平衡,所以不能出现一边高一点低的情况。该题有个条件是在一个有序的数组集合里,所以再重构这颗树时,根节点就可以选择数组的中间位置,因为剩下左侧部分全部是小于根节点的,而右侧部分全部是大于根节点的,正好符合二叉搜索树的定义。以此类推剩下部分的根节点依然中间位置,从而进行左右的分割,直到最后不能进行分割即可。
function TreeNode(val) { // 树节点类
this.val = val;
this.left = this.right = null;
}
var sortedArrayToBST = function (nums) {
const _helper = (arr, l, r) => { // l为左边界、r为右边界
if (l > r) { // 递归终止条件
return null
}
const mid = l + (r - l) / 2 | 0 // 取数组中间值,并向下取整
const node = new TreeNode(arr[mid]) // 前序遍历,实例化为树节点
node.left = _helper(arr, l, mid - 1) // 将分割的左侧构建为二叉搜索树
node.right = _helper(arr, mid + 1, r) // 将分割的右侧构建为二叉搜索树
return node // 将构建好的树返回
}
return _helper(nums, 0, nums.length - 1) // 注意前闭后闭的区间方式
}; 为什么不采用(l + r) / 2,而采用l + (r - l) / 2的书写方式,是为了防止出现整型溢出的情况。因为数组里每一项的值首先需要实例化为树的节点TreeNode,才能创建它的左孩子和右孩子,所以采用前序遍历的方式。整棵树的构建顺序也是先根节点,然后左子树,最后右子树的顺序完成。
中序遍历
仅仅只是改变了访问节点的顺序,首先访问左子树,然后访问当前根节点,最后访问右子树。还是贴出代码:
class BST {
constructor() {
this.root = null // 根节点
}
...
inorder(fn) { // 中序遍历
const _helper = node => {
if (!node) {
return
}
_helper(node.left) // 先访问左孩子
fn(node.val) // 再访问根节点
_helper(node.right) // 最后访问右孩子
}
_helper(root)
}
} 就是简单的更改了访问节点的位置,顺序也很有意思: 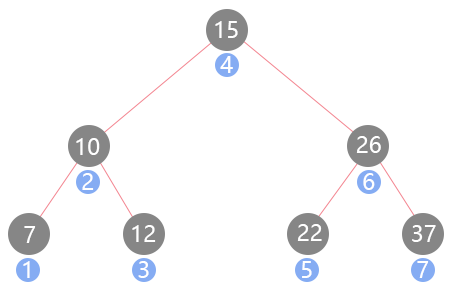
结果是7、10、12、15、22、26、37,正好是一个升序排列方式,这也是二叉搜索树使用中序遍历的一个特点,如果理解了之前前序遍历递归函数的运行过程,中序遍历理解起来就不难了。因为首先是访问完左子树,只要左孩子不是null,递归函数就会一直往左侧访问,而二叉搜索树最小的节点正好最左侧的叶子节点,到了底部之后则开始采用左中右的递归顺序往回走,正好是一个升序排列。它有啥用?还是使用一个算法题来看其应用。
中序遍历应用 - 530-二叉搜索树的最小绝对差
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。 看题目不是太好理解,就以我们示例的二叉搜索树为例: 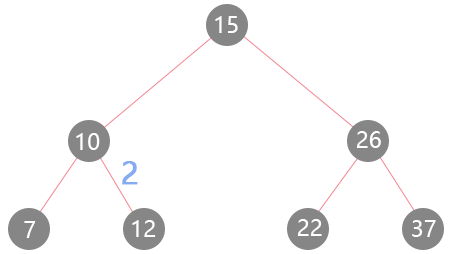
按照该题的算法,解为2,因为任意两个之间的绝对值,这是最小的。一下没有想到解题的思路?没事,假如我们把这颗二叉搜索树看成是一个升序数组[7, 10, 12, 15, 22, 26, 37],求解该数组任意两个值之间差的最小绝对值。不难发现其实"任意"是个幌子,你只能去比较两个相连数字它们的绝对值。再去看二叉搜索树,也就明白了,使用中序遍历,比较两个前后访问的节点即可得到"任意"两个节点的最小绝对值差。 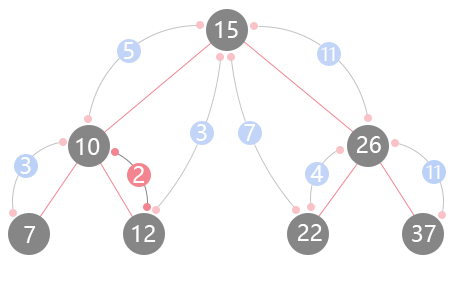
var getMinimumDifference = function (root) {
let prev = null // 保存之前访问的节点
let minimum = Infinity // 取最大值
const _helper = node => {
if (!node) {
return
}
_helper(node.left)
if (prev !== null) { // 第一次访问没有prev节点
minimum = Math.min(minimum, node.val - prev.val) // 始终保存最小的值
}
prev = node // 将本次循环的节点缓存为上一个节点
_helper(node.right)
}
_helper(root)
return minimum // 返回最小差
}; 使用一个prev变量缓存上一次访问的节点,每一次让当前访问到的节点值减去之前节点的值,因为是中序遍历,所以当前节点的值一定是大于之前节点的,将整颗树遍历完,返回两两相减最小的值即可。
后序遍历
也是仅仅改变访问节点的位置即可,先访问左子树,再访问右子树,最后访问自身根节点,贴代码:
class BST {
constructor() {
this.root = null // 根节点
}
...
postorder(fn) { // 后序遍历
const _helper = node => {
if (!node) {
return
}
_helper(node.left) // 先访问左孩子
_helper(node.right) // 然后访问右孩子
fn(node.val) // 最后访问根节点
}
_helper(root)
}
} 先访问完左子树,然后是右子树,最后是自身节点,访问顺序如下: 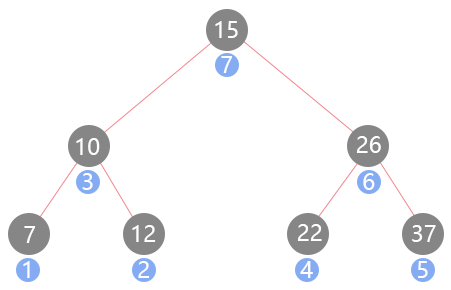
后序遍历应用 - 563-二叉树的坡度
给定一个二叉树,计算整个树的坡度。
一个树的节点的坡度定义即为,该节点左子树的结点之和和右子树结点之和的差的绝对值。空结点的的坡度是0。
整个树的坡度就是其所有节点的坡度之和。 简单来说就是每个节点的坡度等于它左右子树和的绝对差,所以叶子节点的坡度就是0,因为左右孩子都是空节点,返回的就是0-0的值。进行子问题拆解的话,可以理解为整颗树的坡度就是它的左右子树坡度之和,所以需要先求出左右孩子的坡度才能计算出当前节点的坡度,后序遍历非常适合。 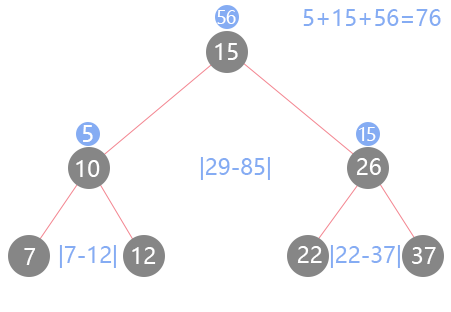
解题代码如下:
var findTilt = function (root) {
let tilt = 0
const _helper = (node) => {
if (!node) {
return 0 // 叶子节点的坡度为0
}
const l = _helper(node.left) // 先求出左子树的和
const r = _helper(node.right) // 再求出右子树的和
tilt += Math.abs(l - r) // 当前节点的坡度等于左右子树和的绝对差
return l + r + node.val // 返回子树和
}
_helper(root)
return tilt
}; 深度优先遍历(DFS)应用进阶
以上三道算法题,分别展示了树的前/中/后序遍历的实际应用,这些还远远不够。有的算法题常规的遍历方式并不能太好解决问题,这个时候就需要在深刻理解了树的(DFS)遍历特性后,进行额外灵活的处理来解决。
反常规中序遍历 - 538-把二叉搜索树转换为累加树
给定一个二叉搜索树,把它转换成为累加树,使得每个节点的值是原来的节点值加上所有大于它的节点值之和。 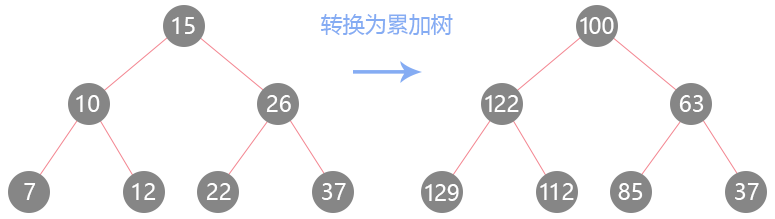
题目不好懂,不过从转换的示例可以看出,从右子树最右叶子节点开始,进行两两的节点值累加,最终从右到左的累加完整棵树。如果把这颗二叉搜索树看成是一个数组[7,10,12,15,22,26,37],那么它的操作就是数组从后往前的进行两两相加并覆盖前一个值。对于树的话,我们就需要进行反常规的中序遍历,首先遍历右子树,然后遍历根节点,最后遍历左子树,也就是进行一次降序遍历。
var convertBST = function (root) {
let sum = 0
const _helper = (node) => {
if (!node) {
return null
}
_helper(node.right) // 先遍历右子树
node.val += sum // 右子树到底后逐个节点进行值的累加与覆盖
sum = node.val // 记录的就是上个被覆盖节点的值
_helper(node.left) // 最后遍历左子树
}
_helper(root)
return root // 返回新的累加树
}; 前序加后序遍历 - 257-二叉树的所有路径
给定一个二叉树,返回所有从根节点到叶子节点的路径。 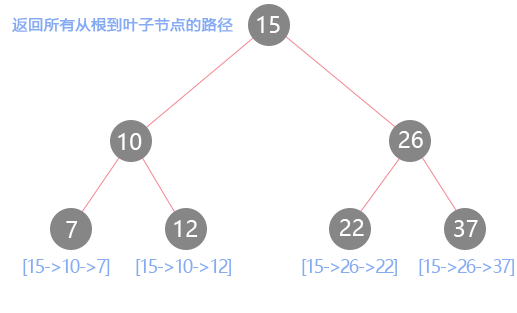
题目的要求是从根节点到叶子节点,所以要记录每一步的当前节点,而前序遍历的顺序正好可以记录从根到叶子节点的整条路径。而这道题有意思的地方在于前序遍历返回时,需要把最后一步的叶子节点从路径里移除掉,重新添加另外的节点路径值,所以可以在后序遍历的顺序里,像贪吃蛇一样一口口的去吃掉已经访问过的路径。有人把这种解法取了个挺厉害的名叫回溯。代码如下:
var binaryTreePaths = function (root) {
const ret = []
const _helper = (node, path) => {
if (!node) {
return
}
path.push(node.val) // 前序遍历访问,记录路径的每一步
_helper(node.left, path)
_helper(node.right, path)
if (!node.left && !node.right) { // 到达了叶子节点
ret.push(path.join('->')) // 将路径转换为字符串
}
path.pop() // 后序遍历访问,将访问过的路径节点弹出
}
_helper(root, [])
return ret
}; 广度优先遍历(BFS)
深度优先是先遍历完一棵子树,再遍历完另一颗子树,而广度优先的意思是按照树的层级一层层的访问每个节点,图示如下: 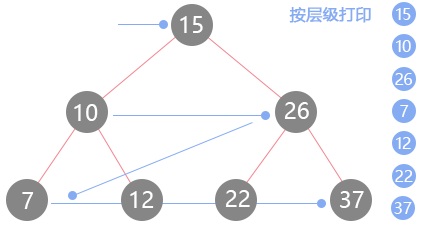
当然你也可以从右往左的打印,打印顺序就是15、26、10、37、22、12、7,广度优先的实现我们需要借助另外一种数据结构《队列》,因为普通的队列理解起来并不复杂,所以之前的章节也没有单独介绍。正好到了树的层序遍历,在这里可以将队列的定义及其应用一并介绍。
什么是队列
之前的章节我们介绍了栈,这是一种一端堵死,后进先出的数据结构。而队列则有不同,没有哪头堵死,从队尾进入,队首出队的一种顺序数据结构。 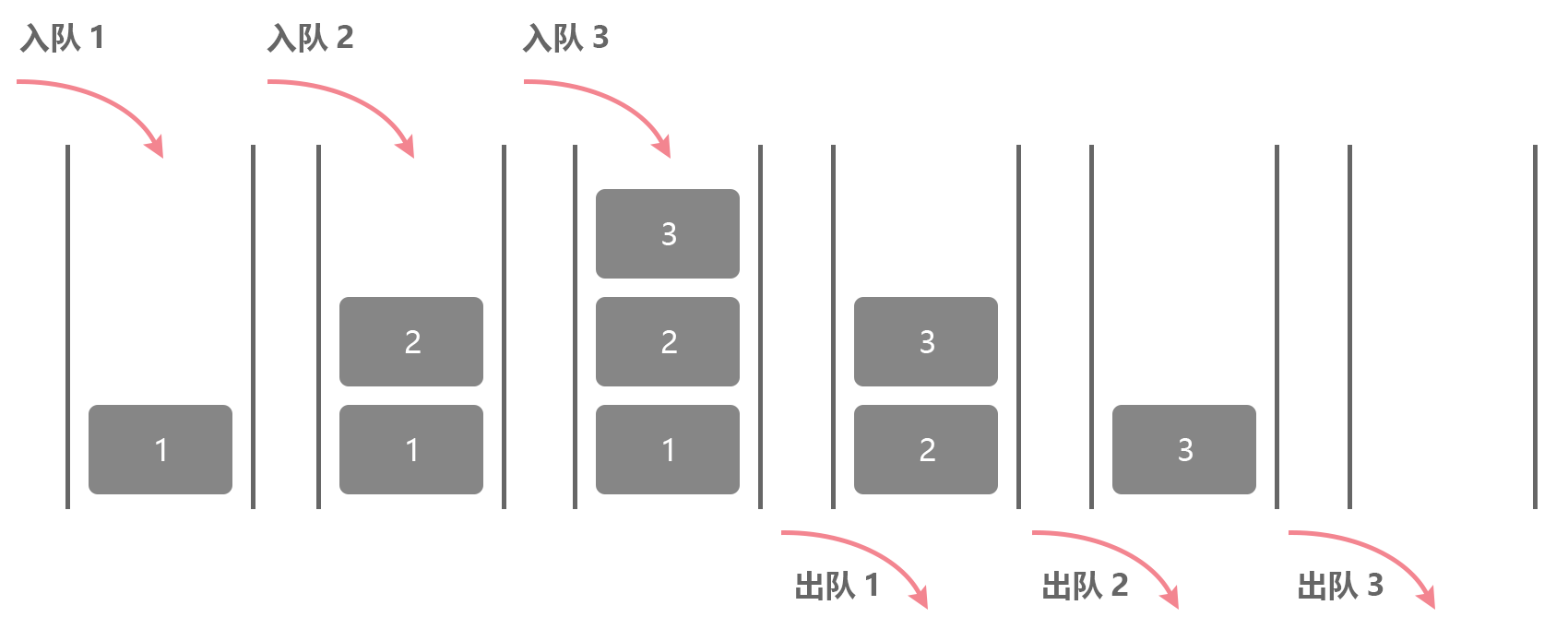
这也是一种受控的数据结构,提供的接口只能访问到队尾和队首,中间的元素外部无法访问到。
树的BFS实现
使用队列,将每个节点入队,同时在出队一个节点后,将它的两个孩子节点入队。首先入队根节点,然后出队根节点的同时,入队它的两个孩子节点,此时队列不为空,继续采用同样的方式入及出队接下来的节点。 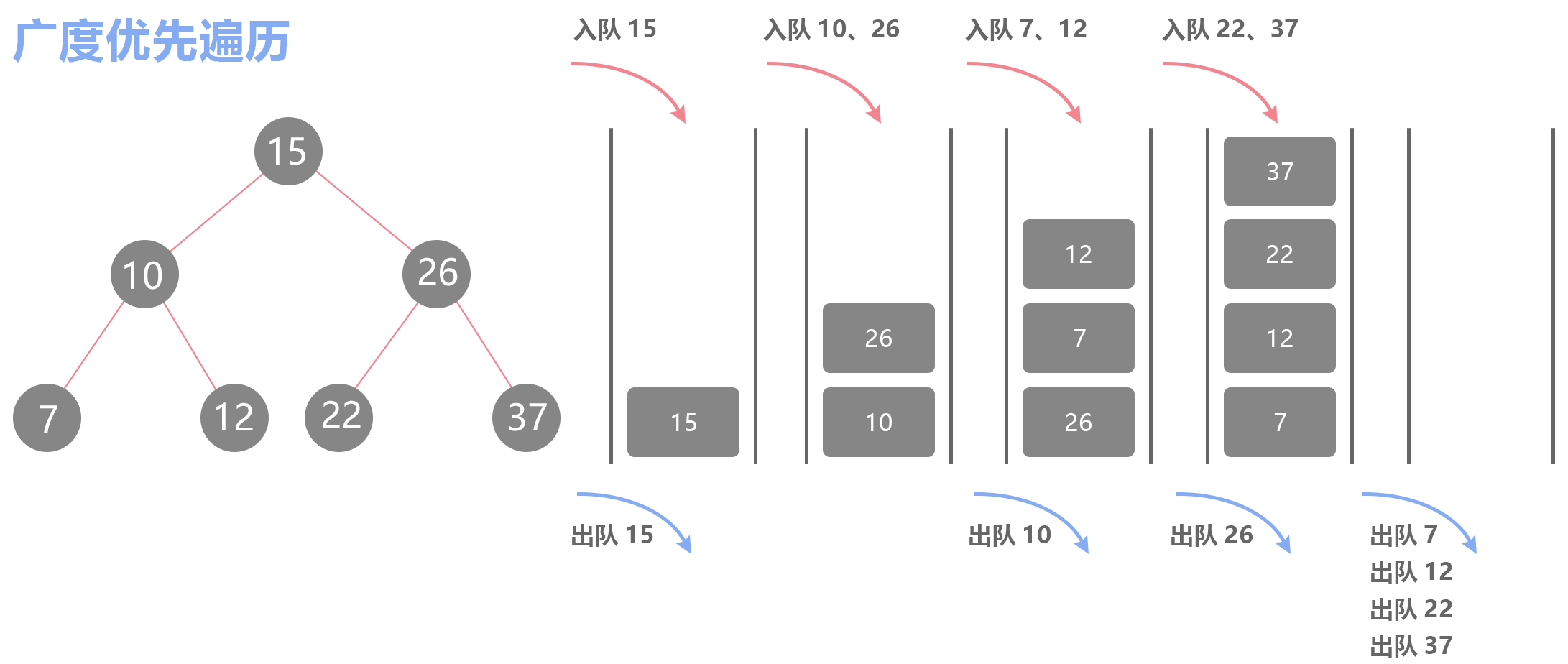
代码实现如下:
class BST {
constructor() {
this.root = null // 根节点
}
...
levelOrder(fn) {
if (!this.root) {
return
}
const queue = [this.root] // 首先入队根节点
while (queue.length > 0) {
const node = queue.shift() // 出队队首节点
fn(node.val) // 访问出队节点值
if (node.left) { // 入队左孩子
queue.push(node.left)
}
if (node.right) { // 入队右孩子
queue.push(node.right)
}
}
}
} 广度优先遍历应用 - 637-二叉树的层平均值
这个完全就是为了层序遍历而量身定制的,不过和常规的遍历有所不同,需要求出每一层的平均值,也就是说在遍历完一层的时候,我们需要知道这一层已经遍历完了,这样才可以求出平均值。可以在while循环内再加一个针对每一层的循环,代码如下:
var averageOfLevels = function (root) {
if (root === null) {
return []
}
const queue = [root]
const ret = [] // 最终返回的结果
while (queue.length > 0) {
let len = queue.length
let sum = 0 // 记录每一层的总和
for (let i = 0; i < len; i++) { // 遍历每一层
const node = queue.shift()
sum += node.val
if (node.left) {
queue.push(node.left)
}
if (node.right) {
queue.push(node.right)
}
}
ret.push(sum / len) // 求出该层的平均
}
return ret
}; 最后
告诉大家一个不好的消息,以上所有题目均为简单难度。当然主要是为了熟悉树的遍历方式,还有很多经典的树的问题,如树的公共祖先、翻转、序列化等,再理解了树的遍历和递归后,再面对这些问题也会更好理解,本章内容只是一个抛砖引玉的作用。本章github源码